有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
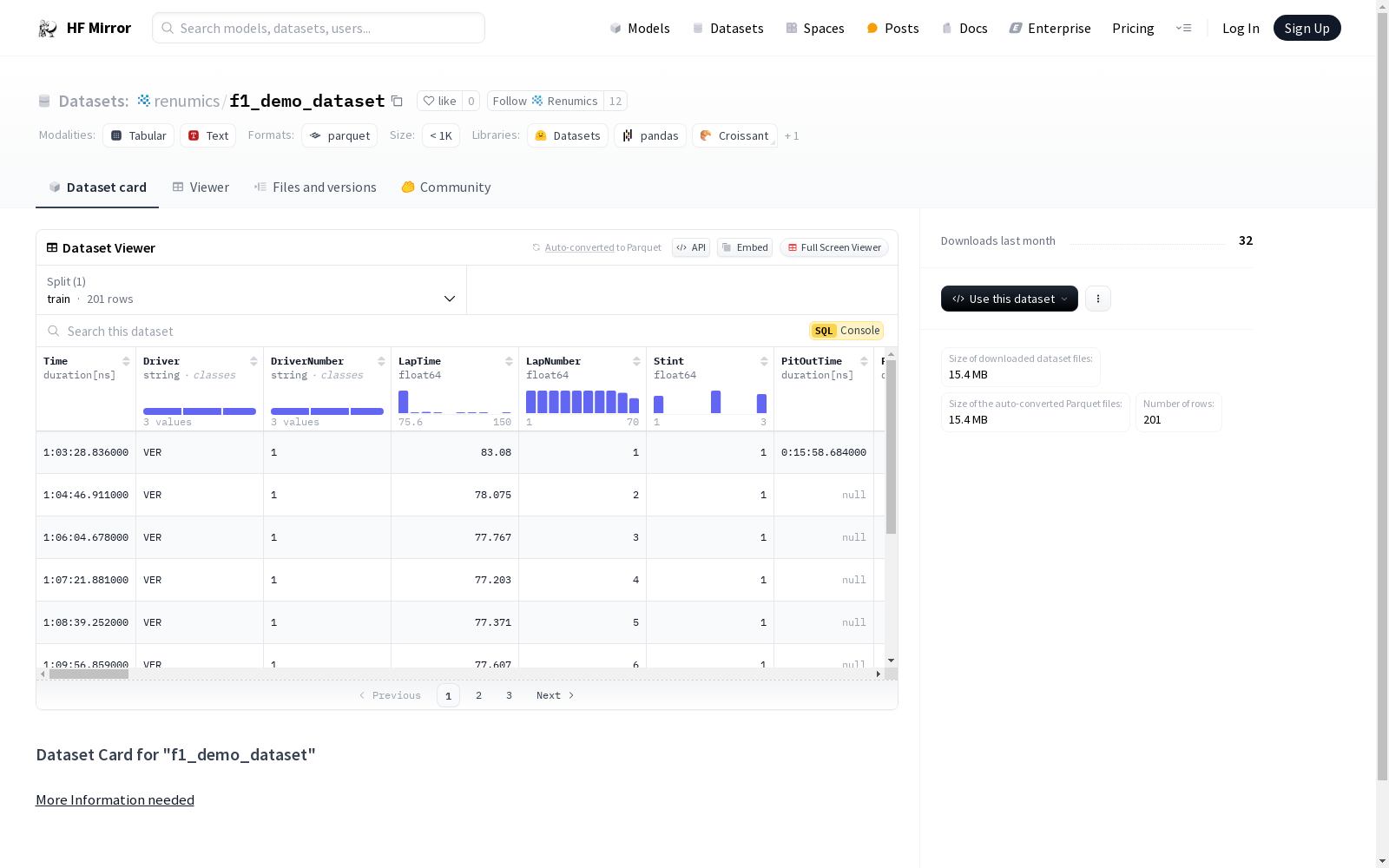
时间特征:
驾驶员相关特征:
速度与位置特征:
可视化特征:
索引特征:
光伏电站发电量预估数据
1、准确预测一个地区分布式光伏场站的整体输出功率,可以提高电网的稳定性,增加电网消纳光电能量的能力,在降低能源消耗成本的同时促进低碳能源发展,实现动态供需状态预测的方法,为绿色电力源网荷储的应用落地提供支持。 2、准确预估光伏电站发电量,可以自动发现一些有故障的设备或者低效电站,提升发电效能。1、逆变器及电站数据采集,将逆变器中计算累计发电量数据,告警数据同步到Maxcompute大数据平台 2、天气数据采集, 通过API获取ERA5气象数据包括光照辐射、云量、温度、湿度等 3、数据特征构建, 在大数据处理平台进行数据预处理,用累计发电量矫正小时平均发电功率,剔除异常数据、归一化。告警次数等指标计算 4、异常数据处理, 天气、设备数据根据经纬度信息进行融合, 并对融合后的数据进行二次预处理操作,剔除辐照度和发电异常的一些数据 5、算法模型训练,基于XGBoost算法模型对历史数据进行训练, 生成训练集并保存至OSS 6、算法模型预测,基于XGBoost算法模型接入OSS训练集对增量数据进行预测, 并评估预测准确率等效果数据,其中误差率=(发电量-预估发电量)/发电量,当误差率低于一定阈值时,该数据预测为准确。预测准确率=预测准确数量/预测数据总量。
浙江省数据知识产权登记平台 收录
PCLT20K
PCLT20K数据集是由湖南大学等机构创建的一个大规模PET-CT肺癌肿瘤分割数据集,包含来自605名患者的21,930对PET-CT图像,所有图像都带有高质量的像素级肿瘤区域标注。该数据集旨在促进医学图像分割研究,特别是在PET-CT图像中肺癌肿瘤的分割任务。
arXiv 收录
CE-CSL
CE-CSL数据集是由哈尔滨工程大学智能科学与工程学院创建的中文连续手语数据集,旨在解决现有数据集在复杂环境下的局限性。该数据集包含5,988个从日常生活场景中收集的连续手语视频片段,涵盖超过70种不同的复杂背景,确保了数据集的代表性和泛化能力。数据集的创建过程严格遵循实际应用导向,通过收集大量真实场景下的手语视频材料,覆盖了广泛的情境变化和环境复杂性。CE-CSL数据集主要应用于连续手语识别领域,旨在提高手语识别技术在复杂环境中的准确性和效率,促进聋人与听人社区之间的无障碍沟通。
arXiv 收录
Yahoo Finance
Dataset About finance related to stock market
kaggle 收录
RAVDESS
情感语音和歌曲 (RAVDESS) 的Ryerson视听数据库包含7,356个文件 (总大小: 24.8 GB)。该数据库包含24位专业演员 (12位女性,12位男性),以中性的北美口音发声两个词汇匹配的陈述。言语包括平静、快乐、悲伤、愤怒、恐惧、惊讶和厌恶的表情,歌曲则包含平静、快乐、悲伤、愤怒和恐惧的情绪。每个表达都是在两个情绪强度水平 (正常,强烈) 下产生的,另外还有一个中性表达。所有条件都有三种模态格式: 纯音频 (16位,48kHz .wav),音频-视频 (720p H.264,AAC 48kHz,.mp4) 和仅视频 (无声音)。注意,Actor_18没有歌曲文件。
OpenDataLab 收录