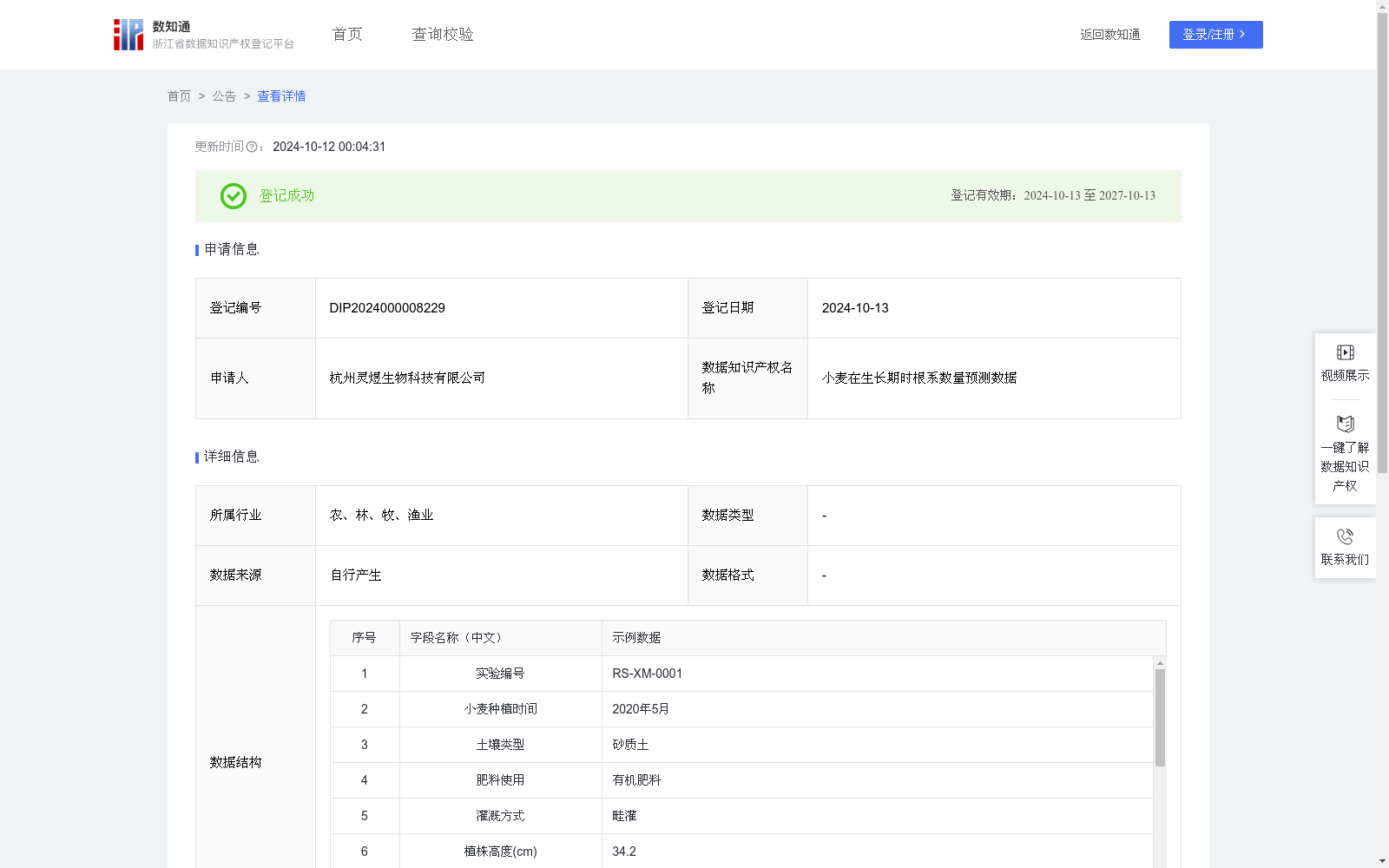
小麦在生长期时根系数量预测数据
收藏浙江省数据知识产权登记平台2024-10-12 更新2024-10-12 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/70113
下载链接
链接失效反馈官方服务:
资源简介:
可以用于小麦根系数量预测,输入为土壤类型、肥料使用、灌溉方式、植株高度(cm)、小麦茎粗(cm)、叶面积指数、根系长度(cm)、小麦产量(亩产量)、根系主要分布范围(cm)、根茎长(cm)、叶绿素含量(mg/g)、叶片数量。输出为小麦根系数量预测值。该模型帮助解决了小麦根系数量和小麦状况的关系建模的问题。小麦植株的根系数量对小麦根的生长有着重要的影响,根系的健康状况(包括有根系数量)还能影响其对养分的吸收效率,从而影响作物的最终产量。因此,通过预测小麦根系的数量,可以初步判断作物的生长状况。通过调查采集小麦数据,并使用传统算法和多元线性回归算法预测小麦根系数量。该模型的输入为土壤类型、肥料使用、灌溉方式、植株高度(cm),小麦茎粗(cm),叶面积指数,根系长度(cm),小麦产量(亩产量),根系主要分布范围(cm),小麦根系数量,根茎长(cm),叶绿素含量(mg/g)。多元线性回归算法通过分析这些输入变量与小麦根系预测数量之间的线性关系,确定每个变量的权重系数,使用深度学习框架构建模型F=ω1 * U1 + ω2* U2+…ω13 * U13,其中,ω1至ω13分别是土壤类型、肥料使用、灌溉方式、植株高度、小麦茎粗、叶面积指数、根系长度、小麦产量、根系主要分布范围、根茎长、叶绿素含量、叶片数量的权重系数,同样的 U1至 U13分别是上述13个输入量的参数值,F是小麦根系数量预测值。在模型训练过程中,算法会利用小麦根系数量实际值进行优化,调整权重系数以最小化预测误差,因此上述权重系数(ω1至ω13)是会动态变化。模型通过最小二乘法等技术,根据输入的数据计算小麦根系数量预测值,从而得出最终结果。通过这样的过程,模型能够将多个输入变量综合考虑,准确预测小麦根系数量。
This dataset is applicable for wheat root count prediction. Its input features include soil type, fertilizer application, irrigation method, plant height (cm), wheat stem diameter (cm), leaf area index, root length (cm), wheat yield (per mu), main root distribution range (cm), rhizome length (cm), chlorophyll content (mg/g), and leaf count, while the output is the predicted wheat root count.
This model addresses the problem of modeling the relationship between wheat root count and wheat growth status. Wheat root count plays a critical role in root growth, and the health status of roots (including root count) also affects their nutrient uptake efficiency, thereby impacting the final crop yield. Therefore, predicting wheat root count allows for a preliminary assessment of crop growth status.
Wheat data was collected through field surveys, and traditional algorithms and multiple linear regression were employed to predict wheat root count. The model's input variables are: soil type, fertilizer application, irrigation method, plant height (cm), wheat stem diameter (cm), leaf area index, root length (cm), wheat yield (per mu), main root distribution range (cm), wheat root count, rhizome length (cm), chlorophyll content (mg/g), and leaf count.
The multiple linear regression algorithm analyzes the linear correlation between these input variables and the predicted wheat root count to determine the weight coefficient for each variable. A deep learning framework is utilized to construct the model as F = ω₁*U₁ + ω₂*U₂ + … + ω₁₃*U₁₃, where ω₁ to ω₁₃ are the weight coefficients corresponding to soil type, fertilizer application, irrigation method, plant height, wheat stem diameter, leaf area index, root length, wheat yield, main root distribution range, wheat root count, rhizome length, chlorophyll content, and leaf count respectively, and U₁ to U₁₃ represent the parameter values of the aforementioned 13 input variables, with F being the predicted wheat root count.
During model training, the actual values of wheat root count are used for optimization, adjusting the weight coefficients to minimize prediction errors, thus the weight coefficients (ω₁ to ω₁₃) are dynamically adjustable. The model calculates the predicted wheat root count based on the input data using techniques such as the method of least squares to obtain the final result. Through this process, the model comprehensively considers multiple input variables to achieve accurate prediction of wheat root count.
提供机构:
杭州灵煜生物科技有限公司
创建时间:
2024-09-10
搜集汇总
数据集介绍
特点
该数据集包含4077条记录,每月更新,用于预测小麦在生长期的根系数量。数据涵盖了土壤类型、肥料使用、灌溉方式等多种因素,通过多元线性回归算法进行预测,模型考虑了13个输入变量,并通过最小二乘法优化权重系数,以提高预测准确性。
以上内容由遇见数据集搜集并总结生成


