FarsInstruct
收藏Hugging Face2024-09-14 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/PNLPhub/FarsInstruct
下载链接
链接失效反馈官方服务:
资源简介:
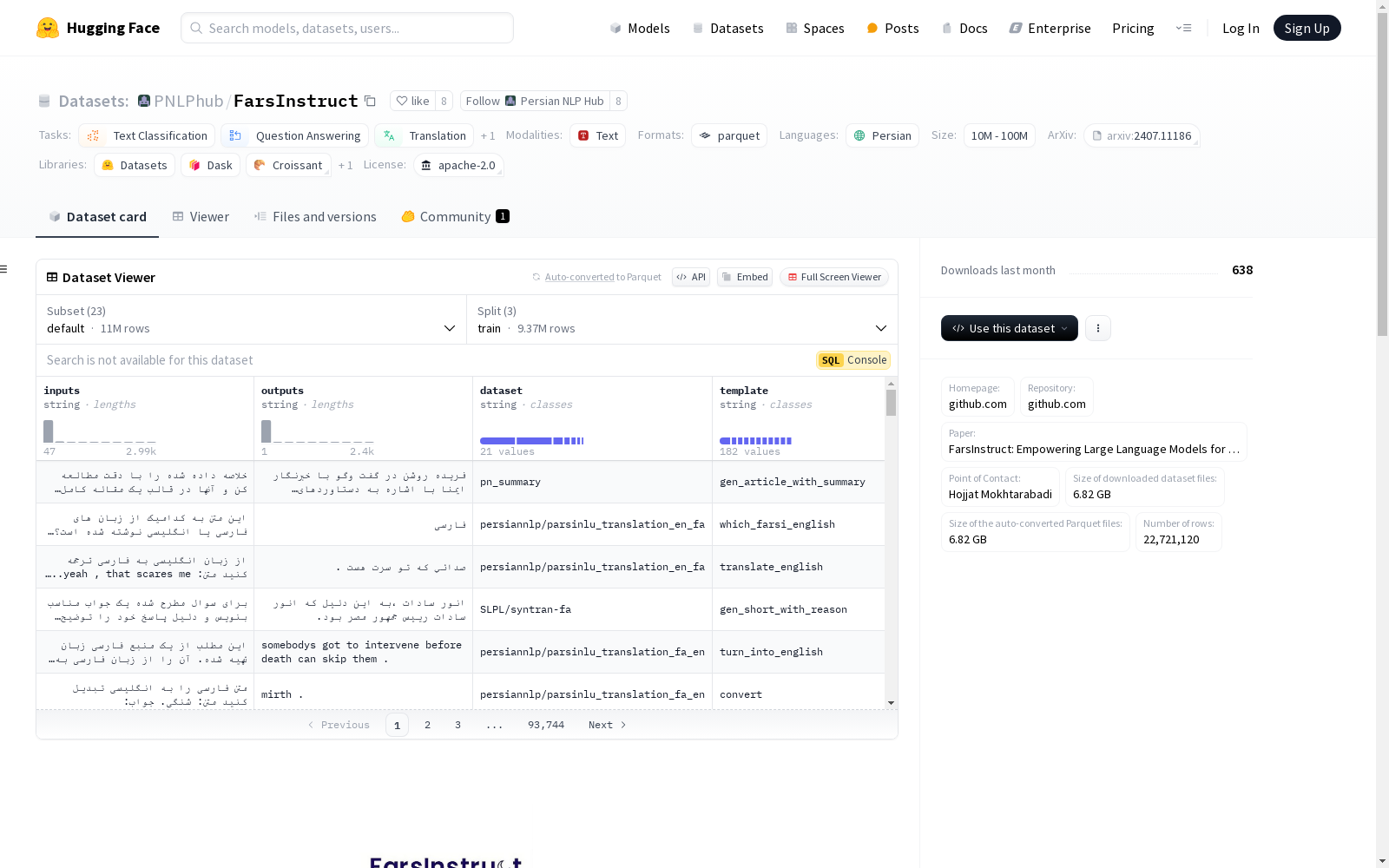
FarsInstruct是一个综合性的指令数据集,旨在增强大型语言模型对波斯语指令的理解能力。该数据集涵盖了多种任务类型和数据集,包含从简单到复杂的书面指令,以及从公共提示池中翻译的内容,确保了丰富的语言和文化代表性。目前,FarsInstruct包含超过200个模板,分布在21个不同的数据集中,并将持续更新以增强其适用性。
创建时间:
2024-09-10
原始信息汇总
FarsInstruct 数据集概述
基本信息
- 语言: 波斯语 (fa)
- 许可证: Apache 2.0
- 任务类别:
- 文本分类
- 问答
- 翻译
- 文本生成
数据集配置
默认配置 (default)
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 9,374,312 个样本, 6,649,186,819 字节validation: 316,117 个样本, 334,659,590 字节test: 1,308,596 个样本, 912,167,953 字节
- 下载大小: 3,641,339,829 字节
- 数据集大小: 7,896,014,362 字节
digi_sentiment 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 22,820 个样本, 17,608,449 字节validation: 4,890 个样本, 3,882,215 字节test: 4,900 个样本, 3,868,362 字节
- 下载大小: 8,359,417 字节
- 数据集大小: 25,359,026 字节
digimag 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 68,960 个样本, 238,365,098 字节validation: 7,670 个样本, 26,780,346 字节test: 8,520 个样本, 28,913,146 字节
- 下载大小: 133,522,898 字节
- 数据集大小: 294,058,590 字节
exappc 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 270,269 个样本, 155,435,407 字节validation: 57,592 个样本, 32,953,710 字节test: 58,033 个样本, 33,691,407 字节
- 下载大小: 82,477,372 字节
- 数据集大小: 222,080,524 字节
farstail 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 72,660 个样本, 55,160,519 字节validation: 15,370 个样本, 11,531,714 字节test: 15,640 个样本, 11,743,134 字节
- 下载大小: 29,639,181 字节
- 数据集大小: 78,435,367 字节
p3_qa_translated 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 646,505 个样本, 369,861,273 字节validation: 76,565 个样本, 39,799,885 字节
- 下载大小: 114,937,546 字节
- 数据集大小: 409,661,158 字节
pars_absa 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 45,006 个样本, 42,114,471 字节validation: 7,506 个样本, 7,177,753 字节test: 7,500 个样本, 6,919,680 字节
- 下载大小: 20,744,680 字节
- 数据集大小: 56,211,904 字节
parsinlu_comp 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 6,000 个样本, 7,262,540 字节validation: 1,250 个样本, 1,587,072 字节test: 5,700 个样本, 6,613,589 字节
- 下载大小: 6,217,942 字节
- 数据集大小: 15,463,201 字节
parsinlu_en_fa 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 3,000,000 个样本, 954,515,437 字节validation: 12,822 个样本, 4,644,558 字节test: 290,154 个样本, 137,665,422 字节
- 下载大小: 371,019,560 字节
- 数据集大小: 1,096,825,417 字节
parsinlu_entailment 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 8,296 个样本, 5,633,585 字节validation: 2,970 个样本, 2,057,795 字节test: 18,407 个样本, 12,628,240 字节
- 下载大小: 6,613,453 字节
- 数据集大小: 20,319,620 字节
parsinlu_fa_en 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 2,999,995 个样本, 951,650,636 字节validation: 25,644 个样本, 9,269,774 字节test: 572,928 个样本, 267,276,146 字节
- 下载大小: 429,940,819 字节
- 数据集大小: 1,228,196,556 字节
parsinlu_multiple_choice 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 12,710 个样本, 5,569,218 字节validation: 417 个样本, 229,444 字节test: 9,450 个样本, 4,109,446 字节
- 下载大小: 2,907,686 字节
- 数据集大小: 9,908,108 字节
parsinlu_qpp 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 17,164 个样本, 8,575,019 字节validation: 8,418 个样本, 4,246,069 字节test: 18,078 个样本, 8,529,281 字节
- 下载大小: 5,262,177 字节
- 数据集大小: 21,350,369 字节
parsinlu_sentiment 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 136,170 个样本, 73,453,659 字节
- 下载大小: 19,197,308 字节
- 数据集大小: 73,453,659 字节
persian_ner 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 143,388 个样本, 79,721,941 字节test: 71,680 个样本, 39,461,389 字节
- 下载大小: 42,457,467 字节
- 数据集大小: 119,183,330 字节
persian_news 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 79,884 个样本, 215,514,328 字节validation: 8,880 个样本, 23,986,039 字节test: 9,864 个样本, 26,811,003 字节
- 下载大小: 115,002,364 字节
- 数据集大小: 266,311,370 字节
persian_qa 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 81,974 个样本, 173,326,369 字节validation: 8,463 个样本, 17,626,045 字节
- 下载大小: 84,699,623 字节
- 数据集大小: 190,952,414 字节
peyma 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 80,280 个样本, 44,356,046 字节validation: 9,250 个样本, 4,981,884 字节test: 10,260 个样本, 5,799,753 字节
- 下载大小: 18,549,315 字节
- 数据集大小: 55,137,683 字节
pn_sum 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 902,242 个样本, 2,037,812,524 字节validation: 11,184 个样本, 20,817,174 字节test: 61,523 个样本, 138,618,064 字节
- 下载大小: 947,261,646 字节
- 数据集大小: 2,197,247,762 字节
snapp_sentiment 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 573,210 个样本, 264,483,001 字节validation: 91,707 个样本, 42,179,746 字节test: 99,363 个样本, 45,729,114 字节
- 下载大小: 93,188,564 字节
- 数据集大小: 352,391,861 字节
syntran 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 481,060 个样本, 240,609,866 字节
- 下载大小: 66,613,727 字节
- 数据集大小: 240,609,866 字节
wiki_sum 配置
- 特征:
inputs: 字符串outputs: 字符串dataset: 字符串template: 字符串
- 分割:
train: 365,224 个样本, 1,075,245,114 字节validation: 40,584 个样本, 120,120,218 字节test: 45,096 个样本, 133,19
搜集汇总
数据集介绍
构建方式
FarsInstruct数据集的构建旨在提升波斯语大语言模型的指令理解能力。该数据集通过整合多种任务类型和数据集,涵盖了从简单到复杂的手写指令以及从公共提示池翻译的内容,确保了语言和文化的丰富性。数据集包含超过200个模板,覆盖21个不同的数据集,并计划持续更新以增强其适用性。
特点
FarsInstruct数据集的特点在于其多样性和广泛性。它不仅包含了多种任务类型,如文本分类、问答、翻译和文本生成等,还特别关注波斯语这一低资源语言的指令理解能力。数据集中的每个任务都经过精心设计,以确保其在实际应用中的有效性。此外,数据集还包含了手动编写和翻译的指令,进一步丰富了其内容。
使用方法
FarsInstruct数据集的使用方法主要包括加载数据集、选择特定任务类型以及进行模型训练和评估。用户可以通过Hugging Face平台轻松访问和下载数据集,并根据需要选择不同的配置和任务类型。数据集提供了详细的训练、验证和测试集,用户可以直接使用这些数据进行模型的训练和评估,以提升波斯语大语言模型的指令理解能力。
背景与挑战
背景概述
FarsInstruct数据集由Hojjat Mokhtarabadi等人于2024年推出,旨在提升大语言模型在波斯语指令理解方面的能力。波斯语作为一种全球范围内资源相对匮乏的语言,其自然语言处理研究长期面临数据不足的困境。FarsInstruct通过整合多种任务类型和数据集,提供了丰富的波斯语指令数据,涵盖了从简单到复杂的指令任务,并包含了从英语翻译而来的指令数据。该数据集的推出不仅填补了波斯语指令理解领域的空白,还为低资源语言的自然语言处理研究提供了重要的参考。
当前挑战
FarsInstruct数据集在构建和应用过程中面临多重挑战。首先,波斯语作为一种低资源语言,其语言结构和文化背景与英语等主流语言存在显著差异,导致指令的翻译和适配过程复杂且容易引入偏差。其次,数据集中包含的任务类型多样,从文本分类到问答、翻译等,如何确保不同任务之间的数据质量和一致性是一个关键问题。此外,数据集的构建依赖于大量的人工标注和翻译工作,如何高效地管理和扩展这些数据资源,同时保持数据的多样性和代表性,也是未来需要持续解决的难题。
常用场景
经典使用场景
FarsInstruct数据集在波斯语自然语言处理领域具有广泛的应用,特别是在指令理解和任务执行方面。该数据集通过提供丰富的指令模板和多样化的任务类型,支持文本分类、问答、翻译和文本生成等多种任务。研究人员和开发者可以利用这些数据来训练和评估大型语言模型在波斯语环境下的表现,从而提升模型在低资源语言中的适应性和准确性。
实际应用
在实际应用中,FarsInstruct数据集被广泛用于开发波斯语智能助手、机器翻译系统和情感分析工具等。例如,企业可以利用该数据集训练波斯语客服机器人,以更准确地理解和回应用户的指令。此外,新闻媒体和社交媒体平台也可以借助该数据集进行波斯语文本的情感分析,从而更好地理解用户反馈和市场趋势。
衍生相关工作
FarsInstruct数据集的发布催生了一系列相关研究工作,特别是在波斯语自然语言处理领域。基于该数据集,研究人员开发了多种针对波斯语的预训练模型和微调方法,进一步提升了模型在波斯语任务中的表现。此外,该数据集还被用于跨语言迁移学习的研究,探索如何将波斯语任务的知识迁移到其他低资源语言中,从而推动多语言自然语言处理技术的发展。
以上内容由遇见数据集搜集并总结生成


