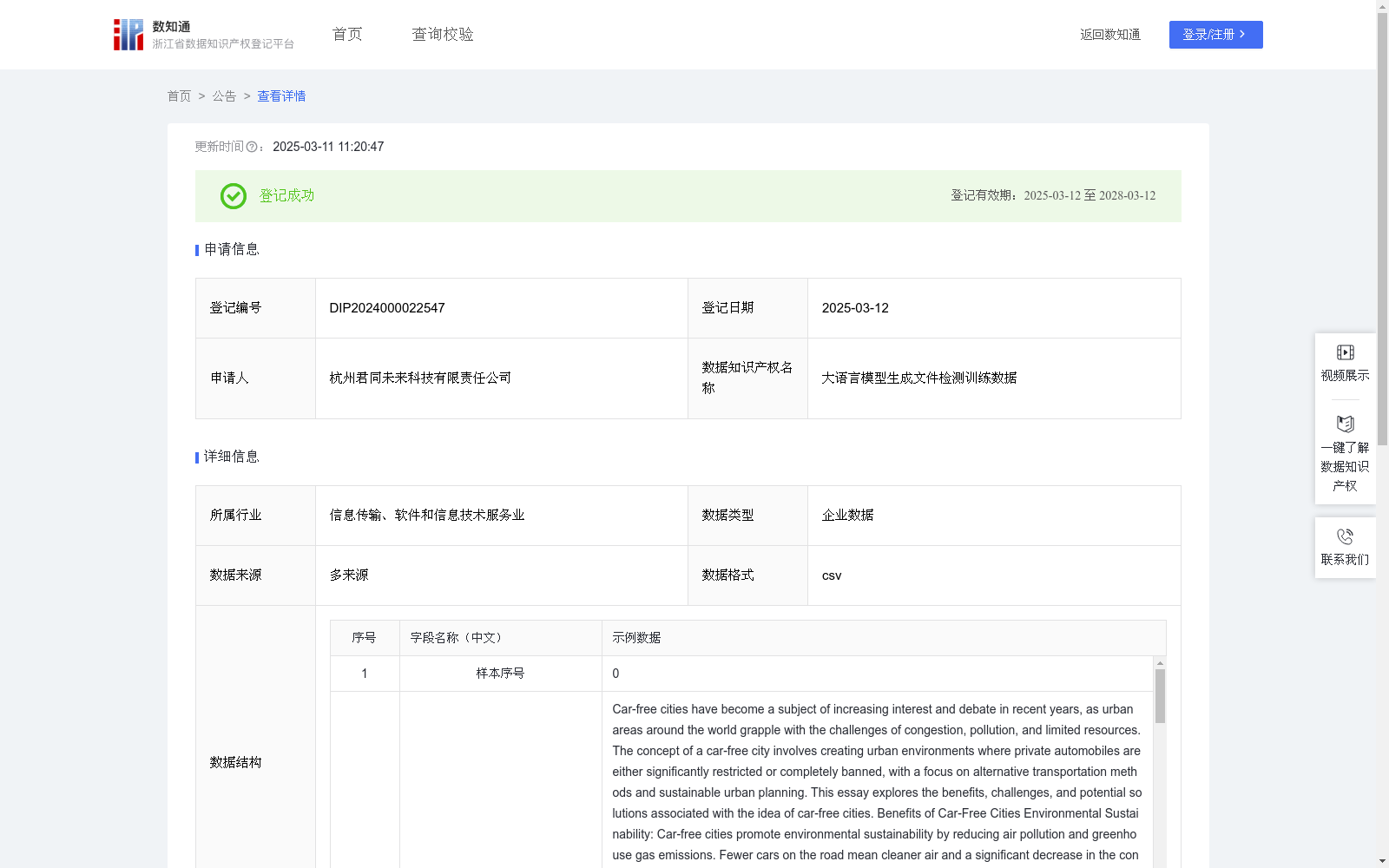
大语言模型生成文件检测训练数据
收藏浙江省数据知识产权登记平台2025-03-11 更新2025-03-12 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/116695
下载链接
链接失效反馈官方服务:
资源简介:
该数据集能够在多个应用场景中高效检测各类大语言模型生成的文本,包括学术论文、新闻报道、社交媒体内容和虚假评论。在学术诚信方面,它可用于防止论文抄袭和自动生成内容作弊;在媒体与信息安全领域,可帮助识别虚假新闻,遏制信息操纵;在在线平台治理中,助力社交媒体内容审核,维护社区真实互动;在数字版权管理和AI内容监管场景下,支持原创内容保护,防止未经授权的AI生成文本滥用。(1)数据来源:学生撰写的多篇论文和AI生成的文章。
https://github.com/wpc666/LLM-detect
(2)数据集结构:该数据集为1个csv文件,共有29164条样本,其中表格第1列表示样本序号;第2列为样本内容;第3列为样本标签,一共分为两个类别,“LLM模型”表示由大语言模型生成,“人类”表示有人工生成,第4列为样本长度,第5列为样本的训练损失。
(3)文本标准化处理:对收集到的文本数据进行标准化处理,包括去除多余空格、标点符号标准化、大小写统一以及停用词去除。
(4)关键语言特征提取:从文本中提取关键语言特征,包括词频统计、TF-IDF特征、句法依赖关系、上下文嵌入表示(如BERT向量)、情感分析特征以及与生成文本检测相关的特征,包括语言模型标志性生成模式、不自然的词序排列等。这些特征有助于模型更准确地识别和区分真实文本与生成文本。
(5)深度学习架构选择:采用基于Transformer的深度学习架构,如BERT或RoBERTa,用于文本嵌入与分类任务。
(6)模型训练与评估:在标注好的生成文本与真实文本数据集上训练分类模型,通过监督学习的方式让模型学习识别生成文本的特征。通过交叉验证和使用不同性能指标(如准确率、F1分数)评估模型的检测能力。
(7)超参数调优:进行超参数调优,包括学习率、批量大小、隐藏层维度、注意力头数等
(8)模型优化与验证:根据评估结果,对模型进行正则化等优化措施。在独立的测试集上验证模型的性能,确保模型在未见数据上也能表现良好。
This dataset can efficiently detect texts generated by various large language models (LLMs) across multiple application scenarios, including academic papers, news reports, social media content, and fake reviews. In terms of academic integrity, it can be used to prevent academic plagiarism and AI-generated content cheating; in the field of media and information security, it helps identify fake news and curb information manipulation; in online platform governance, it assists in social media content moderation to maintain genuine community interactions; in digital rights management and AI content regulation scenarios, it supports original content protection and prevents unauthorized abuse of AI-generated texts.
(1) Data Source: Multiple essays written by students and AI-generated articles. https://github.com/wpc666/LLM-detect
(2) Dataset Structure: This dataset is contained in a single CSV file with a total of 29,164 samples. The first column of the table represents the sample serial number; the second column contains the sample content; the third column is the sample label, which has two categories: "LLM Model" indicates texts generated by large language models, and "Human" indicates texts manually generated by humans; the fourth column is the sample length; the fifth column is the training loss of the sample.
(3) Text Standardization Processing: Standardization processing is performed on the collected text data, including removing redundant spaces, standardizing punctuation marks, unifying capitalization, and removing stopwords.
(4) Key Linguistic Feature Extraction: Key linguistic features are extracted from the texts, including word frequency statistics, TF-IDF features, syntactic dependency relations, contextual embedding representations (such as BERT embeddings), sentiment analysis features, and features related to generated text detection, including characteristic generation patterns of language models, unnatural word order arrangements, etc. These features help the model more accurately identify and distinguish between genuine texts and generated texts.
(5) Deep Learning Architecture Selection: A Transformer-based deep learning architecture, such as BERT or RoBERTa, is adopted for text embedding and classification tasks.
(6) Model Training and Evaluation: The classification model is trained on the labeled dataset of generated and genuine texts, allowing the model to learn features for identifying generated texts through supervised learning. The model's detection capability is evaluated via cross-validation and using different performance metrics, such as accuracy and F1-score.
(7) Hyperparameter Tuning: Hyperparameter tuning is conducted, including learning rate, batch size, hidden layer dimension, number of attention heads, etc.
(8) Model Optimization and Validation: Optimization measures such as regularization are applied to the model based on the evaluation results. The model's performance is validated on an independent test set to ensure that the model performs well on unseen data.
提供机构:
杭州君同未来科技有限责任公司
创建时间:
2024-12-10
搜集汇总
数据集介绍
特点
该数据集是一个用于检测大语言模型生成文本的训练数据集,包含29145条样本,格式为CSV,每年更新。数据集应用于多个场景,如学术诚信、媒体与信息安全等,能够有效识别和区分由大语言模型生成的文本与人工生成的文本。
以上内容由遇见数据集搜集并总结生成


