CompCars
收藏arXiv2015-09-24 更新2024-06-21 收录
下载链接:
http://mmlab.ie.cuhk.edu.hk/datasets/comp_cars/index.html
下载链接
链接失效反馈官方服务:
资源简介:
CompCars数据集是由中国科学院深圳先进技术研究院开发的一个大规模汽车数据集,旨在支持汽车相关的细粒度分类和验证研究。该数据集不仅涵盖了不同视角的汽车图像,还包括了汽车的内部和外部部件以及丰富的属性信息。CompCars数据集具有跨模态特性,包含监控性质和网络性质的数据集。数据集的应用领域广泛,包括汽车模型分类、验证和属性预测等,旨在解决汽车识别和分析中的多种问题。
CompCars is a large-scale automotive dataset developed by the Shenzhen Institute of Advanced Technology, Chinese Academy of Sciences, intended to support fine-grained classification and verification research related to automobiles. This dataset covers not only vehicle images captured from diverse perspectives, but also internal and external components of automobiles along with rich attribute information. Featuring cross-modal properties, the CompCars dataset integrates both surveillance-based and web-crawled datasets. It has broad application scenarios, including vehicle model classification, verification, attribute prediction and other related tasks, aiming to address various challenges in vehicle recognition and analysis.
提供机构:
中国科学院深圳先进技术研究院
创建时间:
2015-06-30
搜集汇总
数据集介绍
构建方式
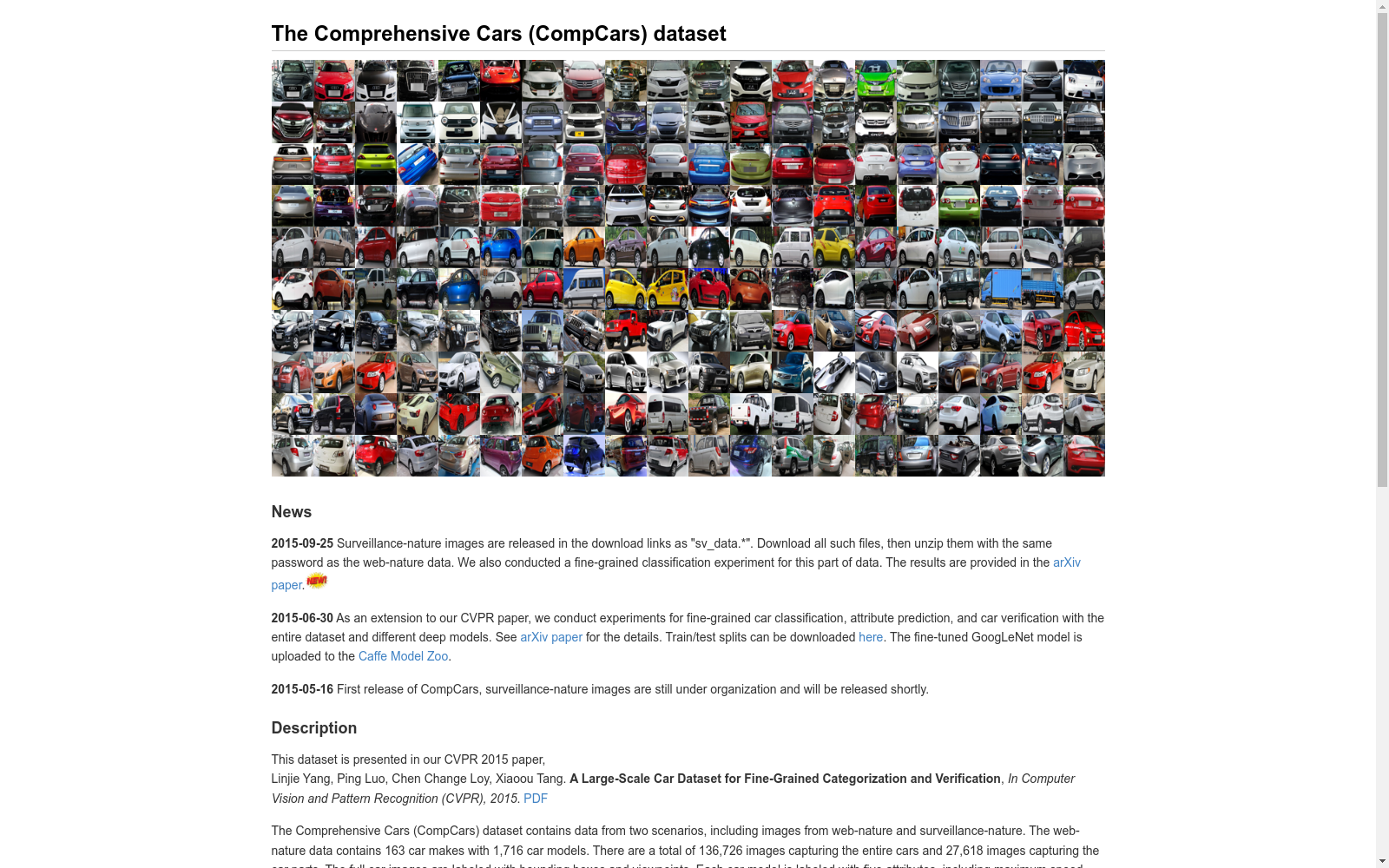
CompCars数据集的构建方式体现了对汽车视觉任务的全面覆盖。该数据集不仅包含了不同视角的汽车图像,还涵盖了汽车的内外部部件以及丰富的属性信息。数据集的构建采用了跨模态的方法,包括从网络自然场景和监控自然场景中收集数据。网络自然场景的数据来源于汽车论坛、公共网站和搜索引擎,而监控自然场景的数据则通过监控摄像头采集。这种多源数据的整合为汽车相关的研究提供了丰富的资源。
特点
CompCars数据集的显著特点在于其大规模和多样性。该数据集包含了208,826张图像,涵盖了1,716种汽车模型,这些模型来自两个不同的场景:网络自然和监控自然。此外,数据集还精心标注了视角、汽车部件以及多种属性,如车型、座位容量和车门数量。这种详尽的标注使得该数据集成为验证各种计算机视觉算法有效性的理想平台,同时也为现实应用和大量新颖研究课题提供了支持。
使用方法
CompCars数据集的使用方法多样,适用于多种汽车相关的视觉任务。例如,可以利用该数据集进行汽车模型分类、汽车模型验证和属性预测等任务。通过卷积神经网络(CNN)等深度学习模型,可以对数据集中的图像进行训练和测试,以实现高精度的分类和验证。此外,数据集的多场景特性也使其适用于跨模态研究,研究人员可以利用不同场景的数据进行模型的泛化能力测试。详细的实验设置和训练/测试数据分割可以在项目页面上找到。
背景与挑战
背景概述
CompCars数据集由香港中文大学信息工程系和深圳先进技术研究院共同创建,旨在填补计算机视觉领域中关于汽车相关任务的空白。该数据集于2015年首次发布,包含了208,826张图像,涵盖1,716种不同车型,分为网络自然和监控自然两种场景。CompCars不仅提供了多种视角的汽车图像,还包括内部和外部部件的详细标注,以及丰富的属性信息,如车型、座位数、车门数等。该数据集的构建旨在推动汽车模型分类、验证和属性预测等领域的研究,为智能交通系统、视频监控和消费者汽车选择等应用提供支持。
当前挑战
CompCars数据集在构建和应用过程中面临多项挑战。首先,汽车模型的细粒度分类任务复杂,因为不同年份和型号的汽车外观差异细微,需要高精度的识别算法。其次,汽车验证任务由于视角的不受限性,比传统的人脸验证更具挑战性。此外,数据集的构建过程中,如何从网络和监控视频中高效且准确地收集和标注大量汽车图像,以及如何确保标注的一致性和准确性,也是一大难题。最后,跨场景的汽车分析,如从网络图像到监控图像的特征迁移,需要解决数据分布差异带来的问题。
常用场景
经典使用场景
CompCars数据集的经典使用场景主要集中在车辆模型的细粒度分类和验证。通过该数据集,研究者能够训练和评估模型,以区分不同品牌、型号和年份的车辆。此外,数据集还支持车辆属性的预测,如最大速度、座位数量和车门数量等,这些属性可以从车辆的外观中推断出来。
解决学术问题
CompCars数据集解决了计算机视觉领域中车辆相关任务的研究空白。它提供了丰富的车辆图像,包括不同视角和内部外部部件,以及详细的属性标注,这为细粒度分类、验证和属性预测等任务提供了坚实的基础。通过这些任务,研究者能够开发出更精确和鲁棒的计算机视觉模型,推动智能交通系统的发展。
衍生相关工作
基于CompCars数据集,研究者已经开展了多项相关工作,包括车辆模型的细粒度分类、车辆验证和属性预测。这些工作不仅提升了车辆识别的准确性,还推动了跨模态分析和3D重建等领域的研究。例如,通过分析不同视角的车辆图像,研究者可以进行超宽基线匹配和3D重建,从而进一步提升车辆识别和验证的性能。
以上内容由遇见数据集搜集并总结生成


