myanmar_quran_parallel_dataset_human_vs_ai
收藏Hugging Face2026-01-31 更新2026-02-02 收录
下载链接:
https://huggingface.co/datasets/freococo/myanmar_quran_parallel_dataset_human_vs_ai
下载链接
链接失效反馈官方服务:
资源简介:
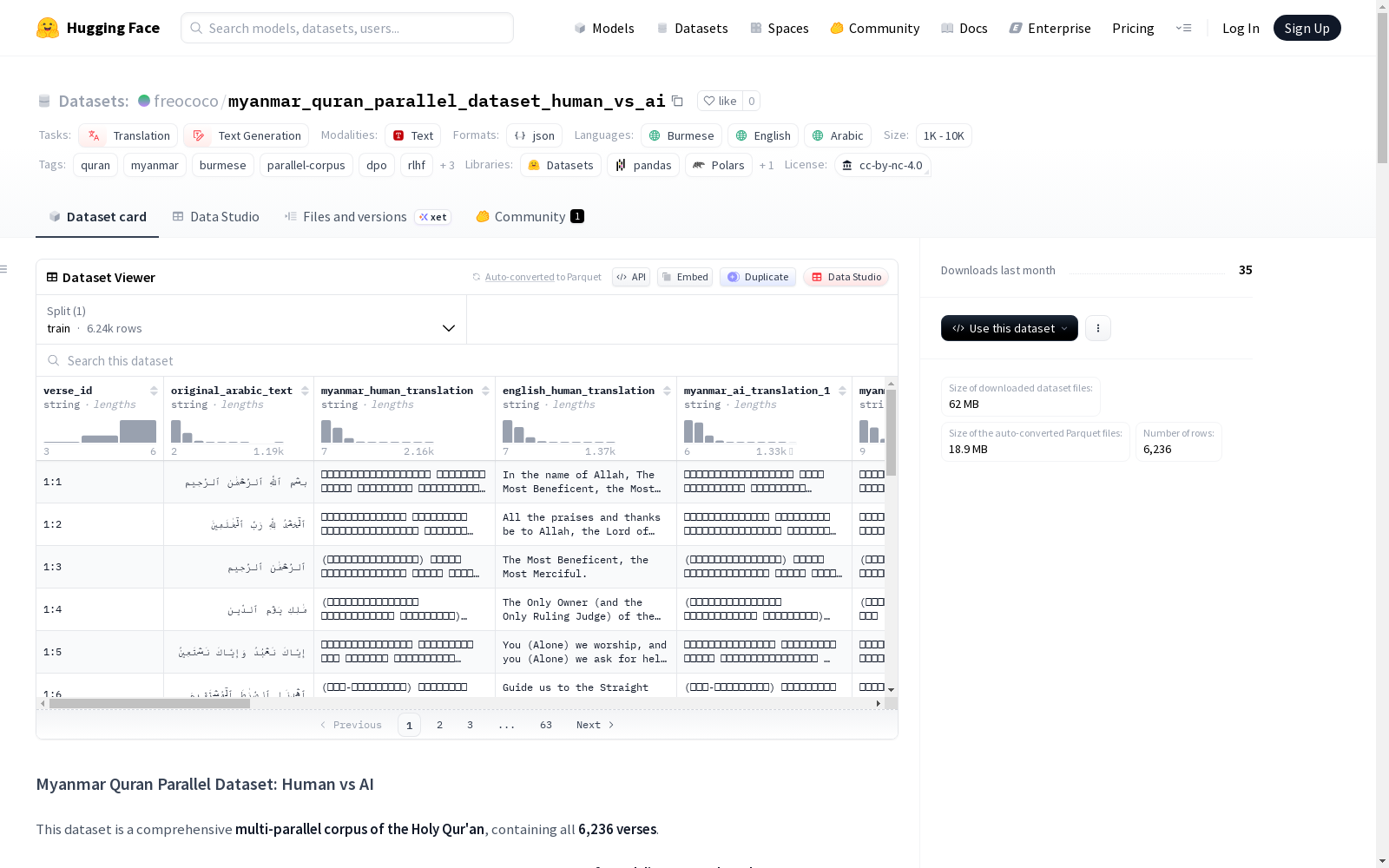
缅甸古兰经平行数据集(人类与AI对比)是一个全面的多平行语料库,包含《古兰经》的全部6,236节经文。该数据集旨在为评估和调整AI系统在宗教语境下的正式、文学和现代缅甸(缅甸语)语言提供高质量的语言资源。每节经文都对齐了原始的Uthmani阿拉伯文本、可信的人类翻译和多个AI生成的翻译,从而能够在语言和语域上进行人类学术与AI输出的细粒度比较。数据集特别适用于偏好学习、翻译基准测试和高语域缅甸语语言建模。数据以JSONL格式提供,每行包含一节经文,包括原始阿拉伯文本、人类翻译的缅甸语和英语版本,以及多个AI生成的缅甸语和英语翻译。数据集采用CC BY-NC 4.0许可,仅限非商业用途。
创建时间:
2026-01-30
搜集汇总
数据集介绍
构建方式
在构建缅甸语《古兰经》平行数据集的过程中,研究者采用了严谨的多源对齐策略。该数据集以《古兰经》全部6236节经文为基础,整合了权威的乌斯曼阿拉伯语原文、由法赫德国王《古兰经》印刷局提供的人类缅甸语翻译,以及希拉利与汗博士的英文译本。核心创新在于,利用Gemini 3 Flash Preview模型,通过精心设计的提示词为每节经文生成了多达14种风格各异的缅甸语AI翻译和2种英文AI翻译,旨在捕捉从正式、文学到现代语体的多样性。所有AI输出均经过人工审查,以确保语义忠实性、术语准确性和语言规范性,从而构建了一个用于精细比较人类学术成果与AI生成内容的高密度平行语料库。
特点
该数据集最显著的特征在于其多层次、高密度的平行结构。它不仅提供了阿拉伯语、缅甸语和英语三种语言之间的权威对齐,更关键的是为每节经文引入了多个人工智能生成的翻译变体。这些AI翻译在保持核心语义一致的前提下,展现了丰富的语体风格、词汇选择和句法结构差异,覆盖了从高度正式的宗教文献语言到现代解释性表达的连续谱。这种设计使得数据集超越了传统平行语料的单一对照功能,成为一个能够支持翻译质量评估、风格偏好分析以及跨语言语义一致性研究的动态资源库,尤其为缅甸语这一资源相对稀缺的语言提供了珍贵的正式语体建模材料。
使用方法
该数据集以JSONL格式提供,每行对应一节经文,便于通过Hugging Face的`datasets`库直接加载。研究人员可将其应用于多个前沿领域:在大型语言模型对齐研究中,可将人类翻译作为参考标准,将多样化的AI翻译作为候选响应,用于直接偏好优化或基于人类反馈的强化学习训练。在机器翻译领域,它可作为高质量的双语或多语平行语料,用于训练和评估阿拉伯语-缅甸语或英语-缅甸语翻译系统。对于比较语言学研究,该数据集为分析人类学术翻译与AI生成文本在风格、语域和解释深度上的系统性差异提供了实证基础。此外,其丰富的正式缅甸语文本也适用于训练能够理解和生成高雅文学语言的语言模型。
背景与挑战
背景概述
随着人工智能在自然语言处理领域的迅猛发展,多语言平行语料库的构建成为推动机器翻译与语言模型对齐研究的关键资源。缅甸语作为资源相对匮乏的语言,尤其在宗教文本等高雅语域中,缺乏高质量的基准数据集。在此背景下,Myanmar Quran Parallel Dataset: Human vs AI应运而生,该数据集由研究团队于近期创建,核心目标在于提供古兰经经文在乌斯曼阿拉伯原文、缅甸语及英语之间的权威人工翻译与多样化AI生成翻译的精细对齐。它不仅致力于弥合古典宗教文本与现代计算语言学之间的鸿沟,更为缅甸语的形式化与文学性语言建模奠定了坚实基础,对低资源语言的技术发展与文化保存具有深远影响。
当前挑战
该数据集旨在应对宗教文本机器翻译与AI对齐中的核心挑战:如何在保持语义忠实性与术语规范性的前提下,生成风格多样、语域恰当的高质量翻译。具体而言,领域挑战体现在对古典阿拉伯语微妙神学含义的精确捕捉,以及将其适配到缅甸语这一资源有限语言的高雅文学表达中。构建过程中的挑战则集中于通过精心设计的提示工程引导AI模型产出多样化的句式与词汇变体,同时确保所有生成内容经过严格的人工循环审核,以维护翻译的学术严谨性与文化敏感性,从而在有限经文数量下实现高密度的、可用于偏好学习与对比分析的平行语料。
常用场景
经典使用场景
在自然语言处理领域,多语言平行语料库的构建对于推动机器翻译与语言模型对齐研究至关重要。Myanmar Quran Parallel Dataset 以其精心设计的结构,为研究者提供了一个经典的使用场景:通过对比同一古兰经经文的人类权威翻译与多种AI生成翻译,进行细粒度的风格、语域及词汇选择分析。这一场景特别适用于评估AI系统在正式、文学性缅甸语生成中的表现,为低资源语言的高质量翻译研究奠定了实证基础。
解决学术问题
该数据集有效应对了学术研究中若干关键挑战。首先,它弥合了低资源语言如缅甸语在高质量、正式文本语料方面的稀缺性,为相关语言模型训练提供了可靠数据。其次,通过提供人类翻译与多版本AI翻译的平行对照,数据集为翻译质量评估、风格迁移研究以及AI输出与人类偏好对齐问题提供了结构化基准。这有助于深化对AI生成文本在语义忠实度与语体多样性之间平衡的理解,推动跨语言自然语言处理技术的发展。
衍生相关工作
围绕该数据集,已衍生出一系列具有影响力的研究工作。在机器翻译领域,研究者利用其平行语料开发了针对缅甸语的神经翻译模型,显著提升了低资源语言的翻译性能。在AI对齐方面,该数据集被用于构建偏好学习基准,指导模型生成更贴近人类学者风格的正式文本。同时,它在跨语言语义表示学习、多风格文本生成评估以及宗教计算语言学等新兴方向也催生了多项创新研究,推动了多模态与多语种NLP技术的交叉融合。
以上内容由遇见数据集搜集并总结生成


