GEM/FairytaleQA
收藏Hugging Face2022-10-25 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/GEM/FairytaleQA
下载链接
链接失效反馈官方服务:
资源简介:
FairytaleQA数据集是一个专注于幼儿园到八年级学生叙事理解的英语数据集。该数据集由教育专家基于证据理论框架创建,包含10,580个显式和隐式问题,这些问题源自278个儿童友好故事,涵盖了七种叙事元素或关系。数据集支持问题生成和问题回答任务,旨在帮助开发系统以促进儿童叙事理解能力的评估和训练。
The FairytaleQA dataset is an English-language dataset focused on narrative comprehension for students from kindergarten through 8th grade. Developed by educational experts under the framework of evidence theory, it contains 10,580 explicit and implicit questions derived from 278 child-friendly stories, covering seven narrative elements or relationships. The dataset supports both question generation and question answering tasks, and is designed to aid the development of systems that facilitate the assessment and training of children's narrative comprehension abilities.
提供机构:
GEM
原始信息汇总
FairytaleQA 数据集概述
数据集描述
- 名称: FairytaleQA
- 语言: 英语
- 许可: 未知
- 任务类别: 其他
- 任务ID: 无
- 数据集大小: 未知
- 多语言性: 否
- 源数据集: 原始
- 注释创建者: 专家创建
- 数据集创建者: Ying Xu (University of California Irvine); Dakuo Wang (IBM Research); Mo Yu (IBM Research); 等
- 资金来源: Schmidt Futures
- 数据集主页: GEM Website
- 数据集存储库: Github
- 数据集论文: ArXiv
- 联系人: Ying Xu, Dakuo Wang
- 联系邮箱: ying.xu@uci.edu, dakuo.wang@ibm.com
- 是否包含排行榜: 是
- 排行榜链接: PapersWithCode
数据集概要
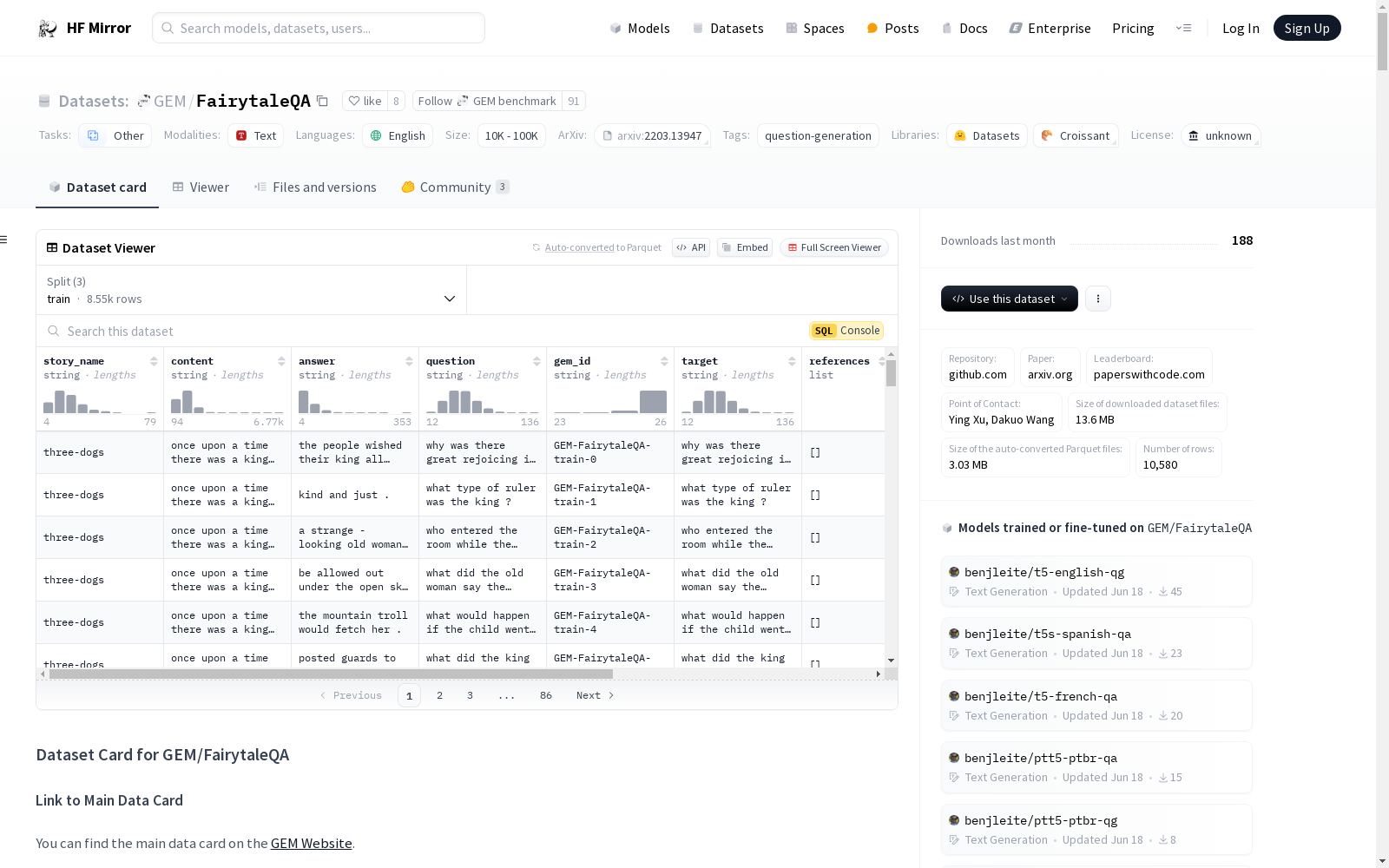
FairytaleQA 数据集是一个专注于幼儿园至八年级学生叙事理解能力的英语数据集。该数据集由教育专家基于证据理论框架生成,包含10,580个明确和隐含的问题,源自278个适合儿童的故事,涵盖七种类型的叙事元素或关系。数据集经过校正,支持问题生成和问题回答任务。
数据集结构
-
数据字段:
story_name: 故事名称content: 故事内容question: 问题内容answer: 答案内容gem_id: GEM命名规则的IDtarget: 用于训练的问题内容references: 用于自动评估的问题内容列表local_or_sum: 本地或摘要,指示QA是否与一个故事部分或多个部分相关attribute: 通过教育专家注释者分类的QA,基于7个叙事元素的框架ex_or_im: 明确或隐含,指示答案是否可以直接在故事内容中找到
-
数据分割:
- 训练: 8548个QA对
- 验证: 1025个QA对
- 测试: 1007个QA对
数据集用途
该数据集旨在帮助开发系统,以促进教育领域儿童叙事理解技能的评估和培训。数据集适合开发模型,自动生成满足持续供应新问题需求的问题和QA对,这可能促进大规模AI支持的交互平台的发展,用于阅读理解技能的学习和评估。
数据集在GEM中的包含理由
数据集区分了细粒度的阅读技能,如对不同叙事元素的理解,并包含由教育专家生成的高质量QA对,这些专家具有足够的培训和教育领域知识,以一致的方式创建有效的QA对。
搜集汇总
数据集介绍
构建方式
FairytaleQA数据集由教育专家基于一个基于证据的理论框架生成,专注于幼儿园至八年级学生的叙事理解。该数据集包含10,580个显式和隐式问题,源自278个适合儿童的故事,涵盖七种叙事元素或关系。数据集经过校正,以支持问题生成和问题回答任务。
特点
FairytaleQA数据集的特点在于其高质量的问答对,由具有足够培训和教育领域知识的教育专家生成,确保问答对的准确性和一致性。此外,数据集区分了细粒度的阅读技能,如对不同叙事元素的理解,并包含显式和隐式答案,增强了数据集的多样性和复杂性。
使用方法
使用FairytaleQA数据集可以通过导入'datasets'库并调用'load_dataset'函数来实现。数据集适用于开发自动生成问题和问答对的模型,以满足对新问题持续供应的需求,从而可能支持大规模的AI支持的互动平台,用于阅读理解技能的学习和评估。
背景与挑战
背景概述
FairytaleQA数据集由加州大学欧文分校和IBM研究院的研究人员于2022年创建,专注于为幼儿园至八年级学生提供叙事理解训练。该数据集基于一个基于证据的理论框架,由教育专家生成,包含10,580个显性和隐性问题,源自278个适合儿童的故事,涵盖七种叙事元素或关系。其核心研究问题在于如何通过高质量的问答对来评估和提升儿童的叙事理解能力,对教育领域的自然语言处理研究具有重要影响。
当前挑战
FairytaleQA数据集在构建过程中面临的主要挑战包括:1) 确保问答对的生成质量,这需要教育专家的深度参与和专业知识;2) 数据集的多样性和覆盖范围,确保能够涵盖多种叙事元素和关系;3) 数据集的标注一致性,避免因不同专家的解读差异导致的数据偏差。此外,该数据集在应用中的挑战在于如何有效利用这些高质量的问答对来开发能够大规模支持阅读理解技能评估和训练的AI系统。
常用场景
经典使用场景
在教育领域,FairytaleQA数据集的经典使用场景主要集中在叙事理解能力的评估与训练。该数据集通过精心设计的问答对,涵盖了从幼儿园到八年级学生的阅读理解需求,特别关注于叙事元素的理解,如角色、因果关系、动作、设定、情感、预测和结果等。这些问答对不仅有助于评估学生的阅读理解能力,还能为开发自动生成问题和答案的系统提供宝贵的训练数据。
衍生相关工作
FairytaleQA数据集的发布激发了大量相关研究工作。例如,基于该数据集的问答生成模型研究,如BART-based模型,展示了其在生成高质量问题方面的潜力。此外,还有研究探讨了如何利用该数据集进行多模态学习,结合图像和文本数据来增强叙事理解。这些衍生工作不仅扩展了数据集的应用范围,还推动了教育技术领域的创新和发展。
数据集最近研究
最新研究方向
在教育领域,FairytaleQA数据集的最新研究方向主要集中在利用先进的自然语言处理技术来提升儿童叙事理解能力的评估和训练系统。该数据集通过专家生成的问答对,涵盖了从幼儿园到八年级学生的叙事元素理解,为开发能够自动生成高质量问题和答案的模型提供了宝贵的资源。当前的研究热点包括利用生成对抗网络(GANs)和预训练语言模型(如BERT和GPT-3)来改进问题生成和回答的准确性,以及探索如何通过这些模型来个性化学习路径,以适应不同学生的阅读理解需求。这些研究不仅有助于提升教育技术的智能化水平,还为大规模开发支持阅读理解技能学习和评估的AI互动平台奠定了基础。
以上内容由遇见数据集搜集并总结生成


