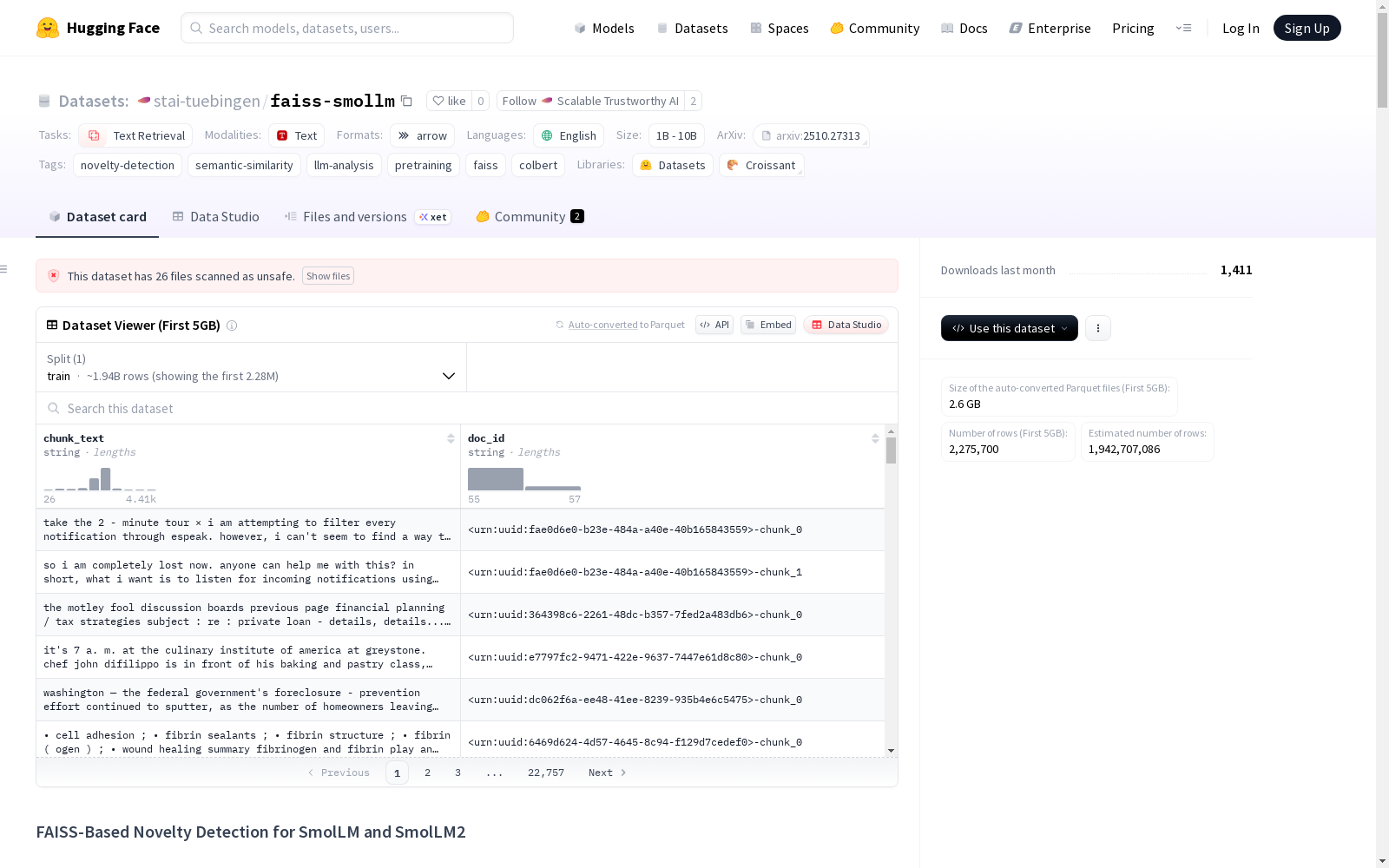
faiss-smollm
收藏FAISS-Based Novelty Detection for SmolLM and SmolLM2 数据集概述
数据集基本信息
- 任务类别: 文本检索
- 语言: 英语
- 标签: 新颖性检测、语义相似性、LLM分析、预训练、FAISS、ColBERT
数据集用途
用于测量文本查询相对于SmolLM和SmolLM2预训练语料库的新颖性,基于论文《Un-Attributability: Computing Novelty From Retrieval & Semantic Similarity》的方法,支持可选的ColBERTv2重排序以提高精度。
技术流程
- 生成嵌入 - 使用句子转换器编码查询
- FAISS搜索 - 从预训练语料库检索前K个最相似文档
- 合并结果 - 合并多个FAISS索引部分的结果
- ColBERT重排序 - 使用ColBERTv2对检索文档进行重排序(可选)
数据分布
由于Hugging Face存储配额限制,完整的FAISS索引和分块数据集分布在两个存储库中:
- https://huggingface.co/datasets/stai-tuebingen/faiss-smollm
- https://huggingface.co/datasets/enguyen/smollm-chunked
系统要求
- Python 3.11(必需)
- CUDA兼容GPU(推荐)
- 预构建的FAISS索引和分块数据集
目录结构
FAISS索引结构
FAISS_PATH_1/ ├── dclm/ │ ├── faiss_part_0.index │ ├── faiss_part_1.index ├── stack_edu/ │ ├── faiss_part_0.index
数据结构(ColBERT用)
DATA_PATH/ ├── fineweb_edu_chunked/ │ ├── part_0/ │ ├── part_1/ ├── cosmopediav2_chunked/ │ ├── part_0/ │ ├── part_1/
结果目录结构
RESULTS_PATH_PARTS/ ├── SmolLM-360M_prompted_embeddings.npy ├── SmolLM2_seq_bat_dclm_part_0_S.npy ├── SmolLM2_seq_bat_dclm_part_0_I.npy
RESULTS_PATH_COMBINED/ ├── SmolLM-360M_prompted_S.npy ├── SmolLM-360M_prompted_I.npy
COLBERT_RESULTS_PATH/ ├── My_Experiment_SmolLM-360M_prompted_top100_chunk_texts_per_query.npy ├── My_Experiment_SmolLM-360M_chunk_size_150_simple_rerank_results_model.json
使用脚本
minimal_example_embeddings.py- 生成查询嵌入minimal_example_FAISS.py- 搜索FAISS索引minimal_example_combine_FAISS.py- 合并FAISS结果minimal_example_ColBERTv2.py- ColBERT重排序(可选)
实验配置
支持单实验和多实验配置:
- 单实验:
[("SmolLM-360M", "prompted")] - 多实验:
[("SmolLM-360M", "prompted"), ("SmolLM-360M", "unprompted"), ("SmolLM-1.7B", "prompted")]