ehasler/aexams
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ehasler/aexams
下载链接
链接失效反馈官方服务:
资源简介:
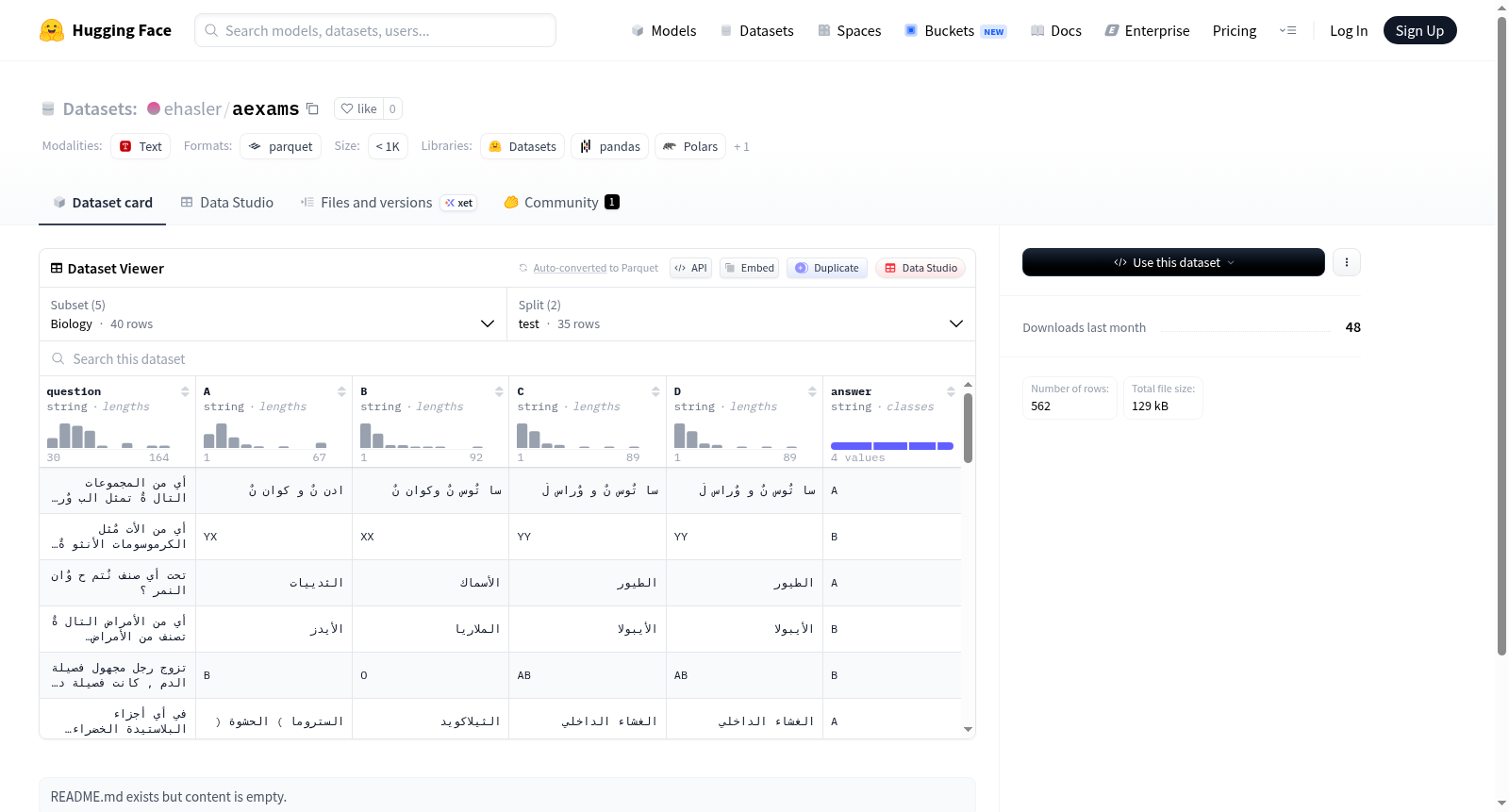
该数据集包含多个配置(生物学、伊斯兰研究、物理学、科学、社会),每个配置包含问题和多个选项(A、B、C、D)以及答案。数据集分为测试集和开发集,每个配置的样本数量和大小各不相同。
The dataset includes multiple configurations (Biology, IslamicStudies, Physics, Science, Social), each containing questions with multiple options (A, B, C, D) and answers. The dataset is divided into test and dev splits, with varying numbers of examples and sizes for each configuration.
提供机构:
ehasler
搜集汇总
数据集介绍
构建方式
aexams数据集专为评估语言模型在学术知识领域的表现而设计,覆盖生物学、伊斯兰研究、物理学、科学及社会科学五大科目。每个科目均以多项选择题形式构建,包含题目(question)、四个选项(A至D)及标准答案(answer)字段。数据分为测试集(test)与开发集(dev),其中开发集各科目统一提供5个样本,测试集样本量从35至272不等,如社会科学测试集规模最大(272例),确保了跨学科评估的多样性。数据以HuggingFace Datasets格式存储,支持通过配置名称加载特定科目,便于进行细粒度性能分析。
特点
该数据集的特点在于其学科覆盖的广度与针对性,从硬科学(物理、生物)到人文社科(伊斯兰研究、社会科学),全面考察模型的跨领域理解能力。每个样本均为标准四选一形式,答案明确,便于自动化评估。开发集与测试集的划分支持模型调优与独立测试,其中开发集样本极少(5例),可能用于提示工程而非训练。数据集规模虽小(总计约500例),但聚焦于高等教育水平的专业知识,对模型的推理与知识检索构成挑战。
使用方法
使用时,可通过HuggingFace Datasets库按配置名称(如'Biology')加载对应子集,调用load_dataset('aexams', 'Biology')即可获取训练与测试数据。每个样本的'question'字段包含题干,'A'至'D'为选项,'answer'为正确答案标识。典型应用场景包括零样本或少样本评估,开发者可将问题与选项拼接为提示文本,通过比较模型输出与正确答案计算准确率。由于无单独训练集,该数据集主要作为基准测试工具,用于衡量语言模型在专业考试环境下的表现。
背景与挑战
背景概述
aexams数据集旨在评估和提升人工智能系统在阿拉伯语教育考试中的知识推理能力。该数据集由研究机构创建于近年,聚焦于阿拉伯世界高中和大学预科阶段的标准化考试题目,涵盖生物学、伊斯兰研究、物理学、科学和社会学五个学科领域。其核心研究问题在于探讨现有大语言模型在处理阿拉伯语复杂学科知识时的表现局限,尤其是面对本土化教学内容和文化语境时的适应能力。通过提供结构化的多项选择题集(包含问题、四个选项及标准答案),aexams为阿拉伯语自然语言处理领域开辟了新的评估基准,对推动多语言AI系统的公平性与鲁棒性研究具有重要影响,亦为阿拉伯语教育资源的数字化进程提供了数据支撑。
当前挑战
该数据集所解决的领域问题在于填补阿拉伯语教育考试评估任务的空白,现有主流评估基准多集中于英语或中文,导致AI模型在阿拉伯语学科推理上缺乏针对性评测手段,限制了其在多语种教育场景的应用。构建过程中面临的挑战包括:首先,题目来源单一且高度依赖本土教材与课程大纲,需确保数据覆盖各学科核心知识点并符合考试标准格式;其次,平衡各学科样本数量差异——社会科学(272条测试样本)远多于伊斯兰研究(73条),可能导致模型评估偏差;此外,题目翻译与术语一致性难以保证,若直接由非母语者转换易引入语义偏差,需投入大量专家进行质量控制与答案验证。
常用场景
经典使用场景
在自然语言处理与教育测评交叉领域,aexams数据集为多学科选择题问答提供了标准化基准。该数据集涵盖生物、物理、科学、社会及伊斯兰研究五个学科,每个样本均由单项选择题构成,包含题干、四个选项和标准答案。研究者常将其作为评估语言模型在阿拉伯语教育场景下知识掌握与推理能力的测试集,通过零样本或少样本设置,衡量模型在特定学科上的表现,尤其关注跨领域迁移与学科内细粒度知识理解。
衍生相关工作
aexams数据集的发布催生了一系列相关研究工作,推动了阿拉伯语教育AI的评测基准建设。基于该数据集,研究者提出了针对低资源语言的多任务学习框架,以提升模型在多个学科上的联合推理能力。此外,有工作探索了将aexams与其它多语言问答数据集结合,进行跨语言知识迁移学习的范式。在模型层面,针对该数据集特点,涌现了诸如结构化知识嵌入与选项对比学习等创新方法,旨在增强模型对学科专业术语与逻辑关系的理解,为教育领域大模型微调提供了新思路。
数据集最近研究
最新研究方向
在当前阿拉伯语自然语言处理与多语言教育评估的前沿交汇处,aexams数据集为跨学科知识推理提供了稀缺的多选题基准资源。该数据集涵盖生物学、伊斯兰研究、物理学、科学与社会五大领域,以标准化四选一格式,系统性地刻画了高中会考水平的认知复杂度。随着多语言大模型评测热潮从英语核心向低资源语言拓展,aexams填补了阿拉伯语学科知识问答的评估空白,为模型在非西方教育体系下的常识理解与专业术语对齐能力研究注入全新动力,亦为推动多模态与跨文化智能评估的公平性与多样性树立标杆。
以上内容由遇见数据集搜集并总结生成


