BiomedCLIP-PubMedBERT_256-vit_base_patch16_224
收藏魔搭社区2026-01-02 更新2025-10-04 收录
下载链接:
https://modelscope.cn/datasets/AaronAaron/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224
下载链接
链接失效反馈官方服务:
资源简介:
# BiomedCLIP-PubMedBERT_256-vit_base_patch16_224
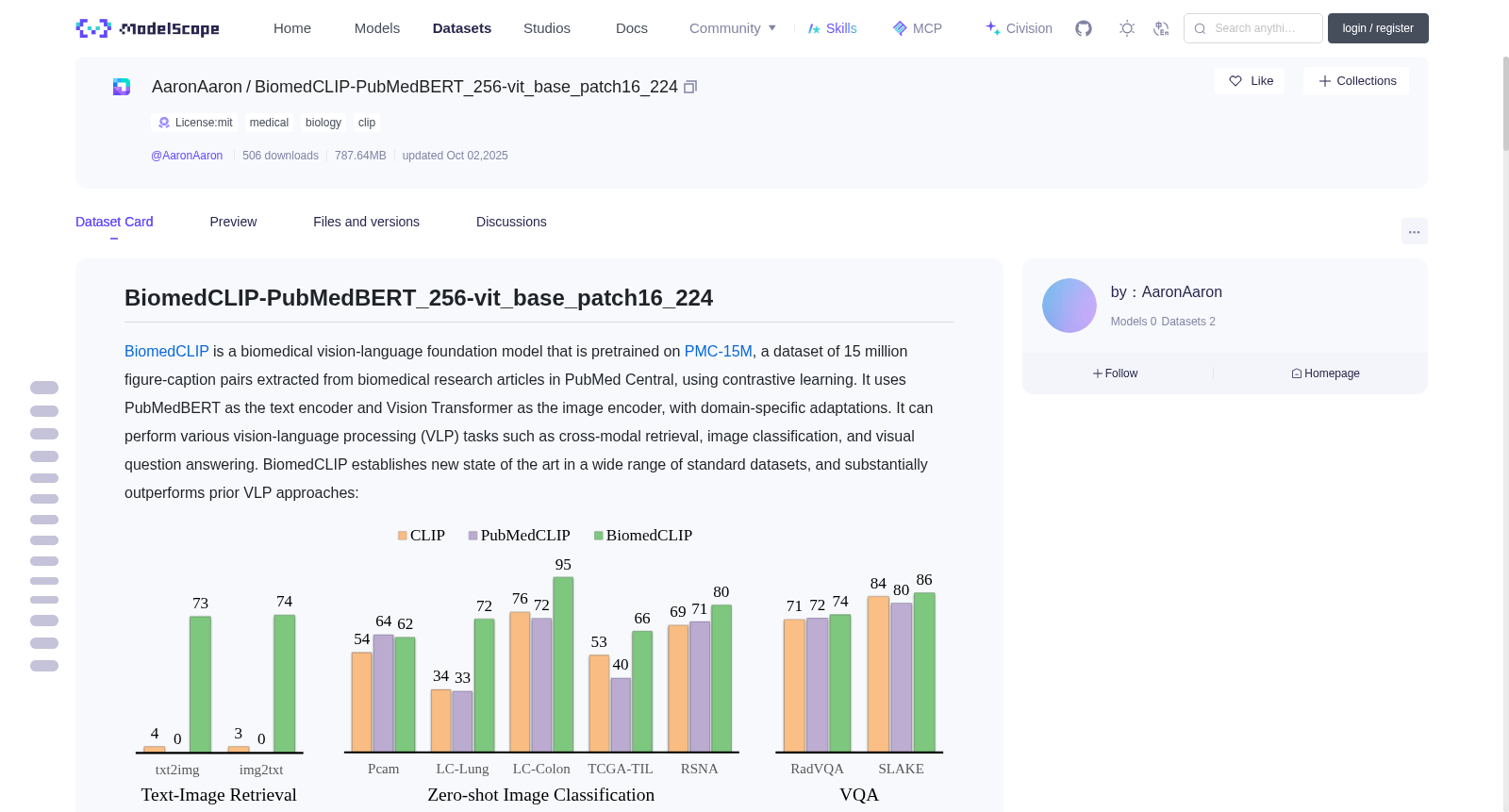
[BiomedCLIP](https://aka.ms/biomedclip-paper) is a biomedical vision-language foundation model that is pretrained on [PMC-15M](https://github.com/microsoft/BiomedCLIP_data_pipeline), a dataset of 15 million figure-caption pairs extracted from biomedical research articles in PubMed Central, using contrastive learning.
It uses PubMedBERT as the text encoder and Vision Transformer as the image encoder, with domain-specific adaptations.
It can perform various vision-language processing (VLP) tasks such as cross-modal retrieval, image classification, and visual question answering.
BiomedCLIP establishes new state of the art in a wide range of standard datasets, and substantially outperforms prior VLP approaches:

## Contents
- [Training Data](#training-data)
- [Model Use](#model-use)
- [Reference](#reference)
- [Limitations](#limitations)
- [Further Information](#further-information)
## Training Data
We have released BiomedCLIP Data Pipeline at [https://github.com/microsoft/BiomedCLIP_data_pipeline](https://github.com/microsoft/BiomedCLIP_data_pipeline), which automatically downloads and processes a set of articles from the PubMed Central Open Access dataset.
BiomedCLIP builds upon the PMC-15M dataset, which is a large-scale parallel image-text dataset generated by this data pipeline for biomedical vision-language processing. It contains 15 million figure-caption pairs extracted from biomedical research articles in PubMed Central and covers a diverse range of biomedical image types, such as microscopy, radiography, histology, and more.
## Model Use
### 1. Environment
```bash
conda create -n biomedclip python=3.10 -y
conda activate biomedclip
pip install open_clip_torch==2.23.0 transformers==4.35.2 matplotlib
```
### 2.1 Load from HF hub
```python
import torch
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer
# Load the model and config files from the Hugging Face Hub
model, preprocess = create_model_from_pretrained('hf-hub:microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224')
tokenizer = get_tokenizer('hf-hub:microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224')
# Zero-shot image classification
template = 'this is a photo of '
labels = [
'adenocarcinoma histopathology',
'brain MRI',
'covid line chart',
'squamous cell carcinoma histopathology',
'immunohistochemistry histopathology',
'bone X-ray',
'chest X-ray',
'pie chart',
'hematoxylin and eosin histopathology'
]
dataset_url = 'https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/'
test_imgs = [
'squamous_cell_carcinoma_histopathology.jpeg',
'H_and_E_histopathology.jpg',
'bone_X-ray.jpg',
'adenocarcinoma_histopathology.jpg',
'covid_line_chart.png',
'IHC_histopathology.jpg',
'chest_X-ray.jpg',
'brain_MRI.jpg',
'pie_chart.png'
]
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
model.eval()
context_length = 256
images = torch.stack([preprocess(Image.open(urlopen(dataset_url + img))) for img in test_imgs]).to(device)
texts = tokenizer([template + l for l in labels], context_length=context_length).to(device)
with torch.no_grad():
image_features, text_features, logit_scale = model(images, texts)
logits = (logit_scale * image_features @ text_features.t()).detach().softmax(dim=-1)
sorted_indices = torch.argsort(logits, dim=-1, descending=True)
logits = logits.cpu().numpy()
sorted_indices = sorted_indices.cpu().numpy()
top_k = -1
for i, img in enumerate(test_imgs):
pred = labels[sorted_indices[i][0]]
top_k = len(labels) if top_k == -1 else top_k
print(img.split('/')[-1] + ':')
for j in range(top_k):
jth_index = sorted_indices[i][j]
print(f'{labels[jth_index]}: {logits[i][jth_index]}')
print('\n')
```
### 2.2 Load from local files
```python
import json
from urllib.request import urlopen
from PIL import Image
import torch
from huggingface_hub import hf_hub_download
from open_clip import create_model_and_transforms, get_tokenizer
from open_clip.factory import HF_HUB_PREFIX, _MODEL_CONFIGS
# Download the model and config files
hf_hub_download(
repo_id="microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224",
filename="open_clip_pytorch_model.bin",
local_dir="checkpoints"
)
hf_hub_download(
repo_id="microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224",
filename="open_clip_config.json",
local_dir="checkpoints"
)
# Load the model and config files
model_name = "biomedclip_local"
with open("checkpoints/open_clip_config.json", "r") as f:
config = json.load(f)
model_cfg = config["model_cfg"]
preprocess_cfg = config["preprocess_cfg"]
if (not model_name.startswith(HF_HUB_PREFIX)
and model_name not in _MODEL_CONFIGS
and config is not None):
_MODEL_CONFIGS[model_name] = model_cfg
tokenizer = get_tokenizer(model_name)
model, _, preprocess = create_model_and_transforms(
model_name=model_name,
pretrained="checkpoints/open_clip_pytorch_model.bin",
**{f"image_{k}": v for k, v in preprocess_cfg.items()},
)
# Zero-shot image classification
template = 'this is a photo of '
labels = [
'adenocarcinoma histopathology',
'brain MRI',
'covid line chart',
'squamous cell carcinoma histopathology',
'immunohistochemistry histopathology',
'bone X-ray',
'chest X-ray',
'pie chart',
'hematoxylin and eosin histopathology'
]
dataset_url = 'https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/'
test_imgs = [
'squamous_cell_carcinoma_histopathology.jpeg',
'H_and_E_histopathology.jpg',
'bone_X-ray.jpg',
'adenocarcinoma_histopathology.jpg',
'covid_line_chart.png',
'IHC_histopathology.jpg',
'chest_X-ray.jpg',
'brain_MRI.jpg',
'pie_chart.png'
]
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
model.eval()
context_length = 256
images = torch.stack([preprocess(Image.open(urlopen(dataset_url + img))) for img in test_imgs]).to(device)
texts = tokenizer([template + l for l in labels], context_length=context_length).to(device)
with torch.no_grad():
image_features, text_features, logit_scale = model(images, texts)
logits = (logit_scale * image_features @ text_features.t()).detach().softmax(dim=-1)
sorted_indices = torch.argsort(logits, dim=-1, descending=True)
logits = logits.cpu().numpy()
sorted_indices = sorted_indices.cpu().numpy()
top_k = -1
for i, img in enumerate(test_imgs):
pred = labels[sorted_indices[i][0]]
top_k = len(labels) if top_k == -1 else top_k
print(img.split('/')[-1] + ':')
for j in range(top_k):
jth_index = sorted_indices[i][j]
print(f'{labels[jth_index]}: {logits[i][jth_index]}')
print('\n')
```
### Use in Jupyter Notebook
Please refer to this [example notebook](https://aka.ms/biomedclip-example-notebook).
### Intended Use
This model is intended to be used solely for (I) future research on visual-language processing and (II) reproducibility of the experimental results reported in the reference paper.
#### Primary Intended Use
The primary intended use is to support AI researchers building on top of this work. BiomedCLIP and its associated models should be helpful for exploring various biomedical VLP research questions, especially in the radiology domain.
#### Out-of-Scope Use
**Any** deployed use case of the model --- commercial or otherwise --- is currently out of scope. Although we evaluated the models using a broad set of publicly-available research benchmarks, the models and evaluations are not intended for deployed use cases. Please refer to [the associated paper](https://aka.ms/biomedclip-paper) for more details.
## Reference
```bibtex
@article{zhang2024biomedclip,
title={A Multimodal Biomedical Foundation Model Trained from Fifteen Million Image–Text Pairs},
author={Sheng Zhang and Yanbo Xu and Naoto Usuyama and Hanwen Xu and Jaspreet Bagga and Robert Tinn and Sam Preston and Rajesh Rao and Mu Wei and Naveen Valluri and Cliff Wong and Andrea Tupini and Yu Wang and Matt Mazzola and Swadheen Shukla and Lars Liden and Jianfeng Gao and Angela Crabtree and Brian Piening and Carlo Bifulco and Matthew P. Lungren and Tristan Naumann and Sheng Wang and Hoifung Poon},
journal={NEJM AI},
year={2024},
volume={2},
number={1},
doi={10.1056/AIoa2400640},
url={https://ai.nejm.org/doi/full/10.1056/AIoa2400640}
}
```
## Limitations
This model was developed using English corpora, and thus can be considered English-only.
## Further information
Please refer to the corresponding paper, ["Large-Scale Domain-Specific Pretraining for Biomedical Vision-Language Processing"](https://aka.ms/biomedclip-paper) for additional details on the model training and evaluation.
# BiomedCLIP-PubMedBERT_256-vit_base_patch16_224
[BiomedCLIP](https://aka.ms/biomedclip-paper) 是一款生物医学多模态基础模型,基于对比学习范式在[PMC-15M](https://github.com/microsoft/BiomedCLIP_data_pipeline)数据集上完成预训练。该数据集包含从PubMed Central收录的生物医学研究论文中提取的1500万张图像-标题对。
本模型采用PubMedBERT作为文本编码器,视觉Transformer(Vision Transformer)作为图像编码器,并针对生物医学领域进行了适配优化。其可实现多种视觉语言处理(Vision-Language Processing, VLP)任务,包括跨模态检索、图像分类以及视觉问答。
BiomedCLIP在多款标准基准数据集上刷新了当前最优性能,显著优于此前的视觉语言处理模型:

## 目录
- [训练数据](#training-data)
- [模型使用](#model-use)
- [参考文献](#reference)
- [局限性](#limitations)
- [补充信息](#further-information)
## 训练数据
我们已将BiomedCLIP数据处理流水线发布至[https://github.com/microsoft/BiomedCLIP_data_pipeline](https://github.com/microsoft/BiomedCLIP_data_pipeline),该工具可自动从PubMed Central开放获取数据集下载并处理论文文本与图像数据。
BiomedCLIP基于PMC-15M数据集构建,该数据集为由本数据处理流水线生成的大规模并行图像-文本数据集,专用于生物医学视觉语言处理任务。其包含从PubMed Central收录的生物医学研究论文中提取的1500万张图像-标题对,涵盖多种生物医学图像类型,如显微镜图像、放射成像图像、组织病理学图像等。
## 模型使用
### 1. 运行环境
bash
conda create -n biomedclip python=3.10 -y
conda activate biomedclip
pip install open_clip_torch==2.23.0 transformers==4.35.2 matplotlib
### 2.1 从Hugging Face Hub加载
python
import torch
from urllib.request import urlopen
from PIL import Image
from open_clip import create_model_from_pretrained, get_tokenizer
# 从Hugging Face Hub加载模型与配置文件
model, preprocess = create_model_from_pretrained('hf-hub:microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224')
tokenizer = get_tokenizer('hf-hub:microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224')
# 零样本图像分类
template = 'this is a photo of '
labels = [
'adenocarcinoma histopathology',
'brain MRI',
'covid line chart',
'squamous cell carcinoma histopathology',
'immunohistochemistry histopathology',
'bone X-ray',
'chest X-ray',
'pie chart',
'hematoxylin and eosin histopathology'
]
dataset_url = 'https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/'
test_imgs = [
'squamous_cell_carcinoma_histopathology.jpeg',
'H_and_E_histopathology.jpg',
'bone_X-ray.jpg',
'adenocarcinoma_histopathology.jpg',
'covid_line_chart.png',
'IHC_histopathology.jpg',
'chest_X-ray.jpg',
'brain_MRI.jpg',
'pie_chart.png'
]
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
model.eval()
context_length = 256
images = torch.stack([preprocess(Image.open(urlopen(dataset_url + img))) for img in test_imgs]).to(device)
texts = tokenizer([template + l for l in labels], context_length=context_length).to(device)
with torch.no_grad():
image_features, text_features, logit_scale = model(images, texts)
logits = (logit_scale * image_features @ text_features.t()).detach().softmax(dim=-1)
sorted_indices = torch.argsort(logits, dim=-1, descending=True)
logits = logits.cpu().numpy()
sorted_indices = sorted_indices.cpu().numpy()
top_k = -1
for i, img in enumerate(test_imgs):
pred = labels[sorted_indices[i][0]]
top_k = len(labels) if top_k == -1 else top_k
print(img.split('/')[-1] + ':')
for j in range(top_k):
jth_index = sorted_indices[i][j]
print(f'{labels[jth_index]}: {logits[i][jth_index]}')
print('
')
### 2.2 从本地文件加载
python
import json
from urllib.request import urlopen
from PIL import Image
import torch
from huggingface_hub import hf_hub_download
from open_clip import create_model_and_transforms, get_tokenizer
from open_clip.factory import HF_HUB_PREFIX, _MODEL_CONFIGS
# 下载模型与配置文件
hf_hub_download(
repo_id="microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224",
filename="open_clip_pytorch_model.bin",
local_dir="checkpoints"
)
hf_hub_download(
repo_id="microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224",
filename="open_clip_config.json",
local_dir="checkpoints"
)
# 加载模型与配置文件
model_name = "biomedclip_local"
with open("checkpoints/open_clip_config.json", "r") as f:
config = json.load(f)
model_cfg = config["model_cfg"]
preprocess_cfg = config["preprocess_cfg"]
if (not model_name.startswith(HF_HUB_PREFIX)
and model_name not in _MODEL_CONFIGS
and config is not None):
_MODEL_CONFIGS[model_name] = model_cfg
tokenizer = get_tokenizer(model_name)
model, _, preprocess = create_model_and_transforms(
model_name=model_name,
pretrained="checkpoints/open_clip_pytorch_model.bin",
**{f"image_{k}": v for k, v in preprocess_cfg.items()},
)
# 零样本图像分类
template = 'this is a photo of '
labels = [
'adenocarcinoma histopathology',
'brain MRI',
'covid line chart',
'squamous cell carcinoma histopathology',
'immunohistochemistry histopathology',
'bone X-ray',
'chest X-ray',
'pie chart',
'hematoxylin and eosin histopathology'
]
dataset_url = 'https://huggingface.co/microsoft/BiomedCLIP-PubMedBERT_256-vit_base_patch16_224/resolve/main/example_data/biomed_image_classification_example_data/'
test_imgs = [
'squamous_cell_carcinoma_histopathology.jpeg',
'H_and_E_histopathology.jpg',
'bone_X-ray.jpg',
'adenocarcinoma_histopathology.jpg',
'covid_line_chart.png',
'IHC_histopathology.jpg',
'chest_X-ray.jpg',
'brain_MRI.jpg',
'pie_chart.png'
]
device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')
model.to(device)
model.eval()
context_length = 256
images = torch.stack([preprocess(Image.open(urlopen(dataset_url + img))) for img in test_imgs]).to(device)
texts = tokenizer([template + l for l in labels], context_length=context_length).to(device)
with torch.no_grad():
image_features, text_features, logit_scale = model(images, texts)
logits = (logit_scale * image_features @ text_features.t()).detach().softmax(dim=-1)
sorted_indices = torch.argsort(logits, dim=-1, descending=True)
logits = logits.cpu().numpy()
sorted_indices = sorted_indices.cpu().numpy()
top_k = -1
for i, img in enumerate(test_imgs):
pred = labels[sorted_indices[i][0]]
top_k = len(labels) if top_k == -1 else top_k
print(img.split('/')[-1] + ':')
for j in range(top_k):
jth_index = sorted_indices[i][j]
print(f'{labels[jth_index]}: {logits[i][jth_index]}')
print('
')
### 在Jupyter Notebook中使用
请参考该[示例笔记本](https://aka.ms/biomedclip-example-notebook)。
### 预期用途
本模型仅可用于以下两类场景:(I) 视觉语言处理领域的后续研究;(II) 复现参考文献论文中报告的实验结果。
#### 主要预期用途
本模型的核心使用场景为支持AI研究者基于本工作开展后续研究。BiomedCLIP及其关联模型可用于探索各类生物医学视觉语言处理研究问题,尤其适用于放射学领域的相关研究。
#### 禁止使用场景
**任何**部署级使用场景(包括商业与非商业用途)目前均不在本模型的适用范围内。尽管我们已通过大量公开研究基准对模型进行了评估,但本模型及其评估流程仅面向研究场景,不支持部署级应用。详细信息请参考[相关论文](https://aka.ms/biomedclip-paper)。
## 参考文献
bibtex
@article{zhang2024biomedclip,
title={基于1500万图像-文本对训练的多模态生物医学基础模型},
author={Sheng Zhang and Yanbo Xu and Naoto Usuyama and Hanwen Xu and Jaspreet Bagga and Robert Tinn and Sam Preston and Rajesh Rao and Mu Wei and Naveen Valluri and Cliff Wong and Andrea Tupini and Yu Wang and Matt Mazzola and Swadheen Shukla and Lars Liden and Jianfeng Gao and Angela Crabtree and Brian Piening and Carlo Bifulco and Matthew P. Lungren and Tristan Naumann and Sheng Wang and Hoifung Poon},
journal={NEJM AI},
year={2024},
volume={2},
number={1},
doi={10.1056/AIoa2400640},
url={https://ai.nejm.org/doi/full/10.1056/AIoa2400640}
}
## 局限性
本模型仅使用英语语料库开发,因此仅支持英语场景。
## 补充信息
请参考对应论文《面向生物医学视觉语言处理的大规模领域预训练》(https://aka.ms/biomedclip-paper),以获取模型训练与评估的更多细节。
提供机构:
maas
创建时间:
2025-10-02
搜集汇总
数据集介绍
背景与挑战
背景概述
BiomedCLIP-PubMedBERT_256-vit_base_patch16_224是一个专为生物医学领域设计的视觉语言处理模型,通过对比学习在PMC-15M数据集上预训练,支持多种跨模态任务,并在生物医学图像分类和检索等任务中表现出色。
以上内容由遇见数据集搜集并总结生成


