synthetic-gsm8k-evolutionary-405b
收藏Hugging Face2024-09-12 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/gretelai/synthetic-gsm8k-evolutionary-405b
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个合成生成的版本,灵感来源于GSM8K数据集,完全使用Gretel Navigator和meta-llama/Meta-Llama-3.1-405B作为代理LLM创建。它包含小学级别的推理任务,具有逐步解决方案,专注于多步推理问题。数据集通过Gretel Navigator利用进化方法生成多样性,确保了问题和答案字段的多样性。所有计算都使用Python的sympy库进行了严格验证。数据集包含600个示例的测试集,按主题和难度分层。问题涵盖了广泛的主题,确保模型在反映现实世界场景的问题上进行训练。问题按难度分为三个级别:中等、困难和非常困难,允许进行更细粒度的评估。数据集的列包括难度、难度描述、主题、上下文、年龄组、文化、问题和答案。
This is a synthetic dataset inspired by the GSM8K dataset, fully created using Gretel Navigator and meta-llama/Meta-Llama-3.1-405B as the proxy LLMs. It contains primary-school-level reasoning tasks with step-by-step solutions, focusing on multi-step reasoning problems. The dataset leverages evolutionary methods via Gretel Navigator to generate diversity, ensuring variety in both the question and answer fields. All calculations are rigorously verified using Python's sympy library. The dataset includes a test set of 600 examples, stratified by topic and difficulty. The questions cover a wide range of topics, ensuring that models are trained on problems that reflect real-world scenarios. The problems are categorized into three difficulty levels: medium, hard, and very hard, enabling more fine-grained evaluation. The dataset's columns include difficulty, difficulty description, topic, context, age group, culture, question, and answer.
提供机构:
Gretel.ai
创建时间:
2024-09-12
原始信息汇总
gretelai/synthetic-gsm8k-evolutionary-405b
概述
- 语言: 英语
- 许可: llama3.1
- 多语言性: 单语种
- 数据集大小: 1K<n<10K
- 源数据集: 原始数据集
- 任务类别: 问答
- 任务ID: 封闭领域问答
- PapersWithCode ID: gsm8k
关键特性
- 合成生成: 使用 Gretel Navigator 生成,采用进化方法确保多样性,生成
question和answer字段。 - 上下文标签: 确保多样性,使用 LLM-as-a-judge 验证输出质量,所有计算通过 Python
sympy库严格验证。 - 训练与测试集: 包含600个示例的测试集,按主题和难度分层。
- 多样化的现实世界情境: 涵盖广泛的主题,确保模型训练的问题反映现实世界场景。
- 按难度分类: 问题分为三个难度级别——中等、困难和非常困难,允许更细粒度的评估。
数据集列描述
difficulty: 问题的难度级别。difficulty_description: 问题的复杂性和所需推理的描述。topic: 问题的主题或学科。context: 问题设置的上下文。age_group: 问题的目标年龄或年级。culture: 问题中反映的文化背景或环境。question: 提供给模型的问题或问题。answer: 问题的最终解决方案。
数据集统计和分布
-
主题分布:
topic Train Test algebra 213 25 arithmetic 207 24 compound interest 167 20 data interpretation 224 27 exponential growth/decay 179 21 fractions 192 22 geometry 207 24 optimization 173 20 percentages 238 29 polynomials 157 19 probability 183 21 proportions 209 24 ratios 203 24 -
难度分布:
difficulty Train Test hard 843 99 medium 969 113 very hard 740 88
引用和使用
-
引用:
@dataset{gretelai_gsm8k_synthetic, author = {Gretel AI}, title = {Synthetically Generated Reasoning Dataset (GSM8k-inspired) with enhanced diversity using Gretel Navigator and meta-llama/Meta-Llama-3.1-405B}, year = {2024}, month = {9}, publisher = {Gretel}, howpublished = {https://huggingface.co/gretelai/synthetic-gsm8k-evolutionary-405b}, }
搜集汇总
数据集介绍
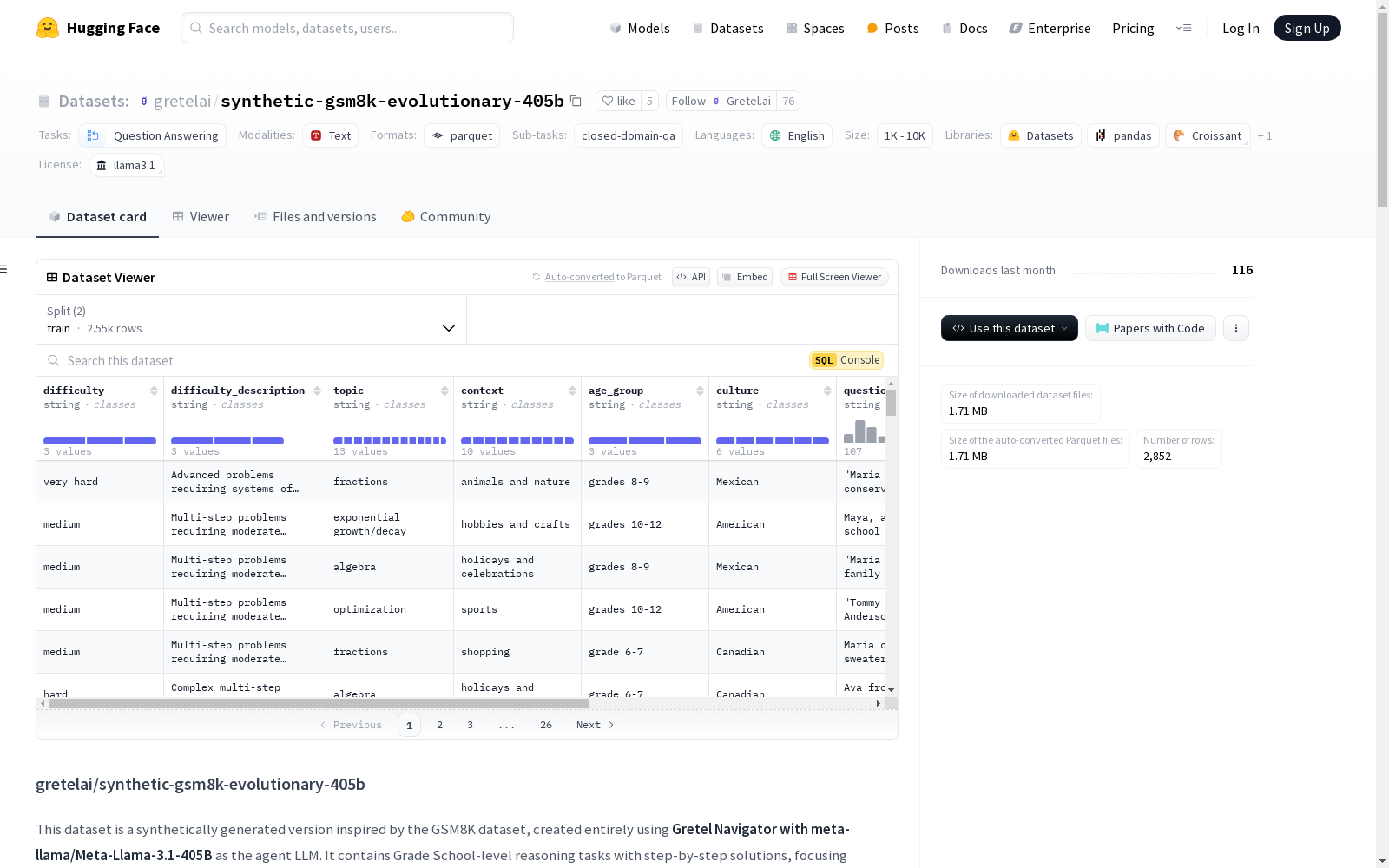
构建方式
该数据集通过Gretel Navigator工具,利用meta-llama/Meta-Llama-3.1-405B作为代理大语言模型,采用进化方法生成多样化的题目和解答。每个问题的生成过程均经过LLM-as-a-judge的质量验证,并通过Python的sympy库进行严格的数学计算验证,确保数据的准确性和多样性。数据集包含600个测试样本,按主题和难度分层,确保评估的全面性。
特点
该数据集的特点在于其多样性和复杂性。题目涵盖了代数、几何、概率等多个数学领域,且每个问题均按难度分为中等、困难和非常困难三个等级。此外,数据集还包含丰富的上下文标签,确保问题能够反映真实世界的场景。通过这种设计,数据集能够有效支持多步推理任务的训练和评估。
使用方法
该数据集适用于训练和评估大语言模型在数学推理任务中的表现。用户可以通过加载数据集,利用其分层的训练和测试集进行模型训练和验证。数据集中的每个样本均包含详细的难度描述、主题分类和上下文信息,便于用户根据需求进行筛选和使用。此外,数据集还提供了详细的统计分布信息,帮助用户更好地理解数据的结构和特点。
背景与挑战
背景概述
synthetic-gsm8k-evolutionary-405b数据集是由Gretel AI于2024年9月发布的一个合成生成的数据集,灵感来源于GSM8K数据集。该数据集专注于小学级别的多步推理问题,旨在通过模拟真实场景中的复杂推理任务,提升模型在数学问题解答中的表现。数据集使用Gretel Navigator工具,结合meta-llama/Meta-Llama-3.1-405B大语言模型,通过进化方法生成多样化的题目和解答。其核心研究问题在于如何通过合成数据增强模型的推理能力,尤其是在多步推理和复杂问题解决方面。该数据集对自然语言处理和教育技术领域的研究具有重要影响,为模型训练提供了高质量的多样化数据。
当前挑战
synthetic-gsm8k-evolutionary-405b数据集在构建过程中面临多重挑战。首先,生成高质量且多样化的题目和解答需要复杂的进化算法和严格的验证机制,以确保数据的准确性和逻辑一致性。其次,尽管使用了LLM-as-a-judge和Python sympy库进行验证,但合成数据的真实性和泛化能力仍需进一步验证,以避免模型在训练过程中过拟合于合成数据。此外,数据集的难度分级和主题分布需要精心设计,以确保模型能够在不同难度和主题下进行均衡训练。这些挑战不仅涉及技术层面的复杂性,还要求数据集在真实场景中的适用性得到充分验证。
常用场景
经典使用场景
synthetic-gsm8k-evolutionary-405b数据集在自然语言处理领域中被广泛应用于多步推理任务的模型训练与评估。该数据集通过生成具有多样化上下文和难度等级的数学问题,特别适用于训练和测试那些需要复杂推理能力的语言模型。研究人员可以利用该数据集来验证模型在处理多步数学问题时的表现,尤其是在涉及代数、几何、概率等领域的推理任务中。
衍生相关工作
基于synthetic-gsm8k-evolutionary-405b数据集,许多研究工作得以展开,尤其是在多步推理模型的优化和评估方面。例如,研究人员利用该数据集开发了新的模型架构,专门用于处理复杂的数学推理任务。此外,该数据集还催生了一系列关于模型推理能力评估的基准测试,推动了自然语言处理领域在推理任务上的技术进步。这些工作不仅提升了模型的性能,还为后续研究提供了宝贵的参考。
数据集最近研究
最新研究方向
在自然语言处理领域,synthetic-gsm8k-evolutionary-405b数据集以其独特的合成生成方式和多样化的题目设计,成为当前研究的热点之一。该数据集通过Gretel Navigator结合Meta-Llama-3.1-405B模型,生成了涵盖代数、几何、概率等多个数学领域的复杂推理问题,特别强调多步推理能力的训练。近年来,随着大语言模型在复杂任务中的表现日益突出,如何提升模型在数学推理任务中的准确性和泛化能力成为研究焦点。该数据集通过分层难度设计和多样化上下文标签,为模型提供了丰富的训练场景,推动了模型在真实世界问题中的应用。此外,其严格的验证机制和Python sympy库的精确计算支持,确保了数据的高质量,为模型评估和优化提供了可靠的基础。这一数据集的出现,不仅为数学推理任务的研究提供了新的基准,也为大语言模型在教育领域的应用开辟了新的方向。
以上内容由遇见数据集搜集并总结生成


