DVQA
收藏github2024-05-07 更新2024-05-31 收录
下载链接:
https://github.com/kushalkafle/DVQA_dataset
下载链接
链接失效反馈官方服务:
资源简介:
DVQA数据集是一个关于条形图问答的数据集,旨在通过问答理解数据可视化。数据集包含图像、元数据和问题-答案对,用于训练和评估算法对数据可视化的理解能力。
The DVQA dataset is a collection focused on bar chart question answering, designed to facilitate the understanding of data visualization through Q&A. It comprises images, metadata, and question-answer pairs, which are utilized for training and evaluating algorithms' comprehension of data visualizations.
创建时间:
2018-06-09
原始信息汇总
数据集概述
数据集名称
DVQA
数据集内容
- 图像:包含多种类型的图像,文件名格式为
bar_{split}_xxxxxxxx.png,其中split为train,val_easy, 或val_hard,xxxxxxxx为8位图像ID。总大小约6.5 GB。 - 问题-答案对:包含三个文件,分别对应三种不同的数据集分割,文件名为
{split}_qa.json。每个文件包含以下字段:image:相关图像文件名question:问题answer:答案question_type:问题类型(结构、数据或推理)bbox_answer:答案的边界框信息question_id:唯一的问题ID 总大小约750 MB。
- 条形图元数据:包含三个文件,分别对应三种不同的数据集分割,文件名为
{split}_metadata.json。每个文件包含以下字段:image:相关图像文件名bars:条形图的边界框和名称信息texts:文本块的信息table:用于创建图表的基础表格数据 总大小约800 MB。
下载链接
引用信息
@inproceedings{kafle2018dvqa, title={DVQA: Understanding Data Visualizations via Question Answering}, author={Kafle, Kushal and Cohen, Scott and Price, Brian and Kanan, Christopher}, booktitle={CVPR}, year={2018} }
搜集汇总
数据集介绍
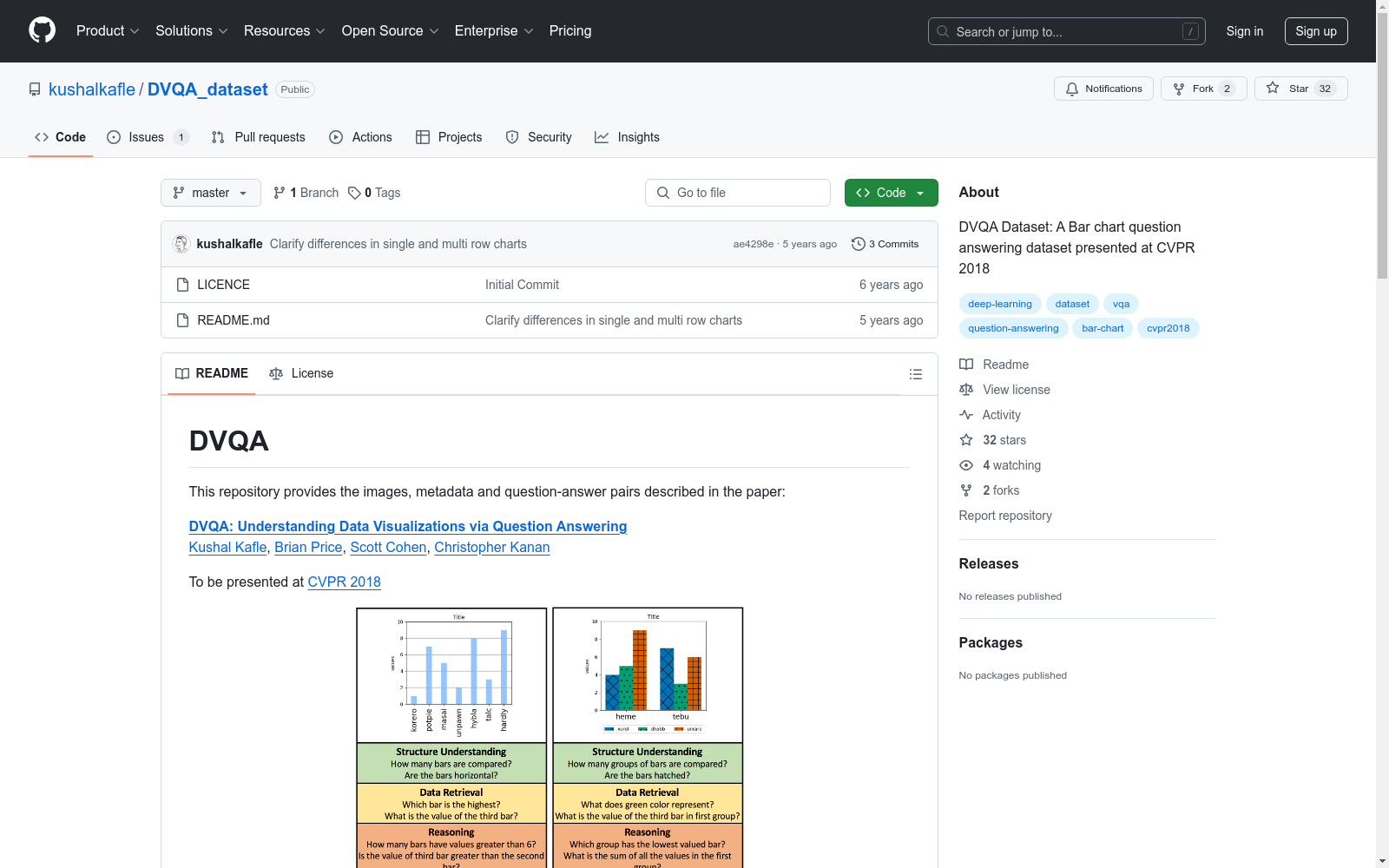
构建方式
DVQA数据集的构建基于对数据可视化图像的深入分析,结合了图像、元数据以及问题-答案对。数据集中的图像主要为条形图,通过特定的命名规则进行标识,并分为训练、简单验证和困难验证三个子集。问题-答案对则涵盖了结构、数据和推理三种类型,提供了详细的字段描述,包括图像文件名、问题、答案、问题类型、边界框信息等。此外,条形图的元数据包含了每个对象的详细注释,如边界框、名称、颜色等,以及用于生成图表的底层表格数据,这些数据以嵌套列表的形式存储,便于进一步分析和使用。
使用方法
DVQA数据集的使用方法多样,适用于多种研究场景。首先,研究者可以通过下载图像、问题-答案对和元数据,进行模型训练和验证。问题-答案对提供了丰富的字段信息,如问题类型和边界框,便于进行针对性的模型评估。其次,元数据中的条形图注释和底层表格数据,可以用于进一步的分析和模型优化。例如,研究者可以将表格数据转换为numpy数组,以便更方便地访问和处理。最后,数据集的三个子集(训练、简单验证和困难验证)为模型提供了不同难度的测试环境,有助于全面评估模型的性能。
背景与挑战
背景概述
DVQA数据集由Kushal Kafle、Brian Price、Scott Cohen和Christopher Kanan于2018年创建,旨在通过问答方式深入理解数据可视化。该数据集的核心研究问题是如何通过自然语言处理和计算机视觉技术,使机器能够解析和回答关于数据可视化图表的问题。DVQA不仅提供了图像、问题-答案对,还包含了详细的图表元数据,为研究者提供了一个全面的工具来探索数据可视化理解的复杂性。该数据集在CVPR 2018上首次亮相,标志着数据可视化与自然语言处理交叉领域的重要进展。
当前挑战
DVQA数据集面临的挑战主要集中在两个方面。首先,数据可视化的复杂性要求模型能够理解图表的结构、数据分布以及推理逻辑,这需要高度复杂的自然语言处理和计算机视觉技术。其次,构建过程中,如何准确标注图表中的各个元素(如条形图的边界框、颜色、文本功能等)以及如何设计有效的问题-答案对,都是极具挑战性的任务。此外,数据集的多样性和规模也增加了模型训练和评估的难度,要求研究者开发出能够处理大规模、多样化数据的算法。
常用场景
经典使用场景
DVQA数据集的经典使用场景主要集中在通过问答系统来理解和解析数据可视化图表。该数据集通过提供图像、元数据和问题-答案对,使得研究者能够训练和评估模型在解读柱状图等数据可视化图表时的表现。具体而言,模型需要根据给定的图表图像回答结构、数据或推理类型的问题,从而推动了计算机视觉与自然语言处理交叉领域的研究。
解决学术问题
DVQA数据集解决了在数据可视化理解领域的多个学术研究问题。首先,它填补了现有数据集中关于数据可视化理解的空白,为研究者提供了一个标准化的基准。其次,通过提供详细的元数据和问题类型分类,该数据集促进了模型在理解图表结构、数据内容和推理能力方面的研究,推动了智能问答系统和视觉推理技术的发展。
实际应用
DVQA数据集在实际应用中具有广泛的前景。例如,在商业智能领域,企业可以利用该数据集训练的模型来自动解析和理解大量的数据可视化报告,从而提高决策效率。此外,在教育领域,该数据集可以帮助开发智能辅导系统,通过解读图表来增强学生的数据分析能力。医疗领域也可以利用该数据集来辅助医生快速理解复杂的医疗数据图表。
数据集最近研究
最新研究方向
近年来,数据可视化领域的研究逐渐向智能化方向发展,DVQA数据集的提出为这一趋势提供了重要的研究基础。该数据集通过结合图像、元数据和问答对,旨在通过问答的方式帮助机器理解数据可视化内容,尤其是在柱状图中的结构、数据和推理问题。这一研究方向不仅推动了计算机视觉与自然语言处理的交叉应用,还为智能数据分析工具的开发提供了新的思路。DVQA数据集的引入,使得研究者能够更深入地探索如何使机器具备解读和分析复杂数据可视化图表的能力,从而在数据科学、商业智能等领域具有广泛的应用前景。
以上内容由遇见数据集搜集并总结生成


