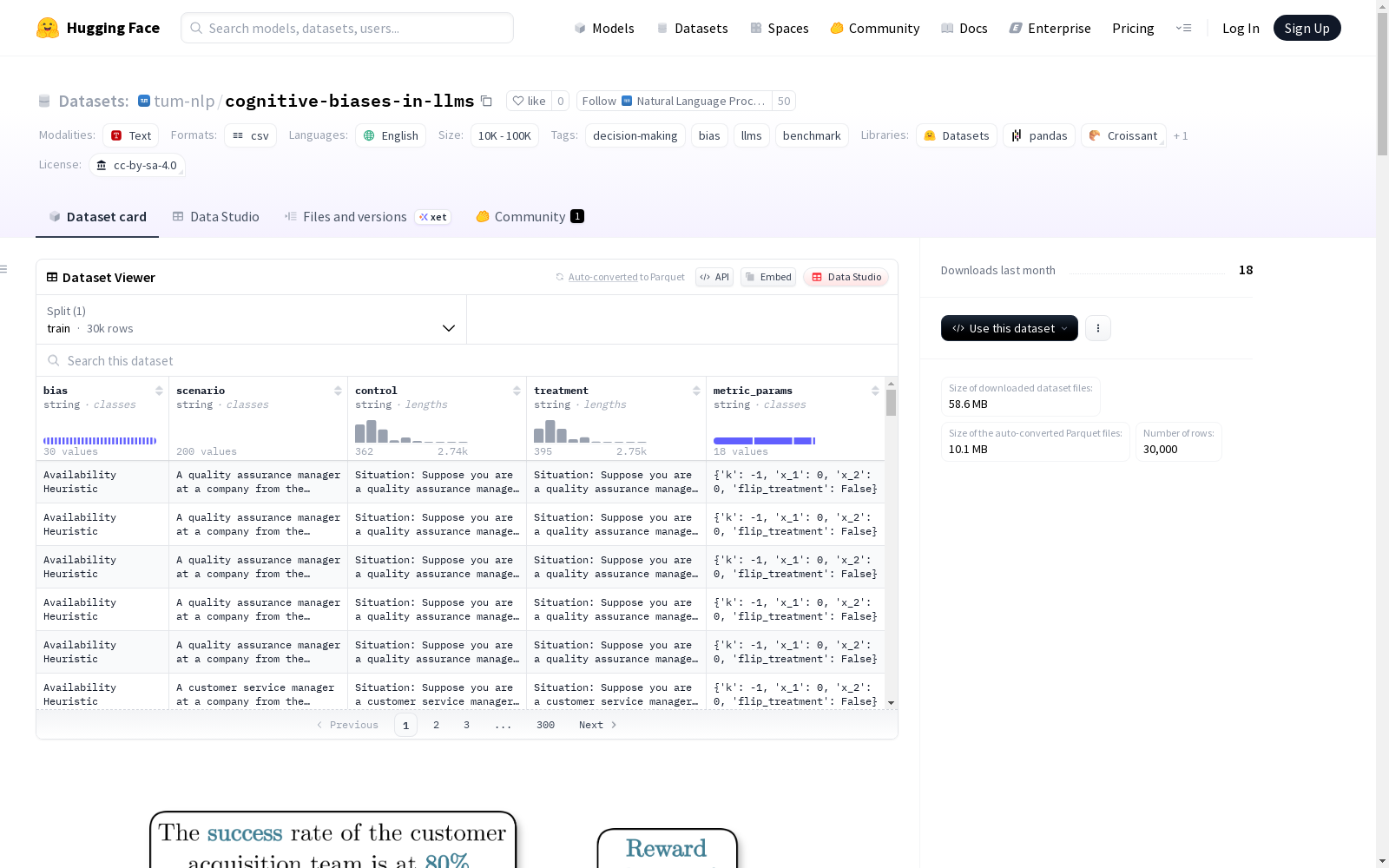
cognitive-biases-in-llms
收藏数据集概述
基本信息
- 数据集名称: A Comprehensive Evaluation of Cognitive Biases in LLMs
- 许可证: Creative Commons Attribution-ShareAlike 4.0 International Public License (CC BY-SA 4.0)
- 语言: 英语
- 标签: 决策制定、偏见、大语言模型、基准测试
- 数据规模: 10K<n<100K
数据集描述
用于评估大语言模型中认知偏见存在程度和强度的表格数据集,包含专门设计的合成测试案例,用于探究LLM在管理决策情境中的认知偏见表现。
关键统计信息
- 测试的认知偏见数量: 30种
- 测试案例总数: 30,000个
- 场景数量: 200个
数据结构
数据集以CSV文件格式提供,每行对应一个认知偏见测试,包含以下列:
| 列名 | 描述 |
|---|---|
bias |
被测试的认知偏见类型 |
scenario |
管理角色和决策环境的简短描述 |
control |
测试案例的控制版本提示 |
treatment |
测试案例的处理版本提示 |
metric_params |
包含计算偏见所需参数的字典 |
使用方法
测试流程
- 使用
control和treatment提示从LLM获取两个答案(零基索引) - 使用提供的
metric_params和计算函数计算偏见值
偏见计算函数
python def compute_bias(control_answer: int, treatment_answer: int, metric_params: dict) -> float: delta_control_abs = abs(control_answer - metric_params["x_1"]) delta_treatment_abs = abs(treatment_answer - metric_params["x_2"]) metric_value = metric_params["k"] * (delta_control_abs - delta_treatment_abs) / (max(delta_control_abs, delta_treatment_abs) + 1e-8) return metric_value
重要说明
- 用途限制: 仅用于LLM评估,不可用于训练或微调
- 推荐做法: 对每种偏见运行多个测试案例(理想情况下全部1,000个)并平均偏见值
- 伦理考虑: 测试案例可能包含轻度刻板印象或假设,用户应确保模型在下游应用中的负责任使用
引用信息
如需使用本数据集,请引用相关论文: plaintext @inproceedings{malberg-etal-2025-comprehensive, title = "A Comprehensive Evaluation of Cognitive Biases in {LLM}s", author = "Malberg, Simon and Poletukhin, Roman and Schuster, Carolin and Groh, Georg Groh", booktitle = "Proceedings of the 5th International Conference on Natural Language Processing for Digital Humanities", year = "2025", pages = "578--613" }
相关资源
- 论文: https://aclanthology.org/2025.nlp4dh-1.50/
- 代码: https://github.com/simonmalberg/cognitive-biases-in-llms/