KRISTEVA
收藏arXiv2025-05-15 更新2025-05-17 收录
下载链接:
https://huggingface.co/datasets/PatrickSui/ KRISTEVA
下载链接
链接失效反馈官方服务:
资源简介:
KRISTEVA是一个评估解释推理的基准数据集,包含1331个选择题,由大学课堂数据改编。数据集旨在测试大型语言模型对文学作品的理解和推理能力,包括提取文体特征、从参数知识中检索相关上下文信息以及风格与外部环境之间的多跳推理。该数据集的创建基于德克萨斯大学奥斯汀分校的批判性读者解读工具包(CRIT),用于教学和评估学生的文学解读能力。KRISTEVA适用于自然语言处理领域,特别是理解隐喻语言和多跳阅读理解。
KRISTEVA is a benchmark dataset for evaluating explanatory reasoning, consisting of 1,331 multiple-choice questions adapted from university classroom data. This dataset aims to test the comprehension and reasoning capabilities of Large Language Models (LLMs) regarding literary works, including extracting stylistic features, retrieving relevant contextual information from parametric knowledge, and conducting multi-hop reasoning between stylistic traits and external contexts. Developed based on the Critical Reader Interpretation Toolkit (CRIT) from The University of Texas at Austin, KRISTEVA is intended for teaching and assessing students' literary interpretation abilities. KRISTEVA is applicable to the field of natural language processing, particularly for tasks involving figurative language comprehension and multi-hop reading comprehension.
提供机构:
McGill University, UT Austin, Microsoft Research, University of Macau
创建时间:
2025-05-15
搜集汇总
数据集介绍
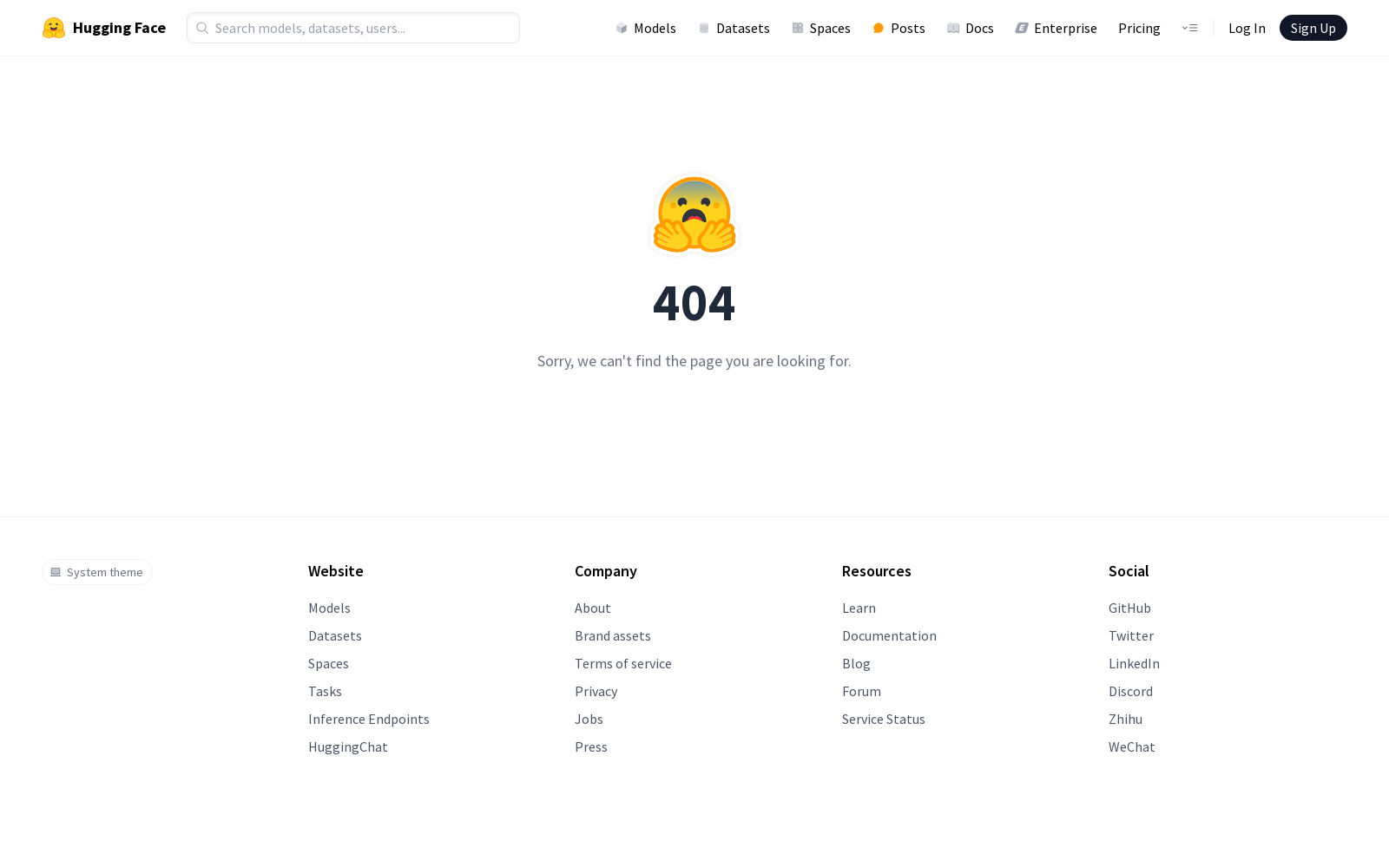
构建方式
KRISTEVA数据集的构建基于大学英语课程中的课堂数据,通过筛选和优化学生论文来确保数据质量。具体而言,研究者收集了来自一门大学文学课程的49篇匿名论文及其成绩,筛选出分数高于80%的论文,并优先使用学生修订后的版本。随后,利用GPT-4o从论文中提取文学特征,并生成多项选择题的干扰项,最终形成包含1331道多项选择题的数据集。这一过程不仅确保了数据的学术严谨性,还通过人工校验和模型优化提升了问题的多样性和挑战性。
特点
KRISTEVA数据集的特点在于其专注于文学细读任务,通过多项选择题的形式评估模型的解释性推理能力。数据集包含三类渐进式任务:提取文体特征、检索相关上下文信息以及进行多跳推理。这些任务不仅涵盖了文学文本的形式分析,还涉及对文化、历史和传记等外部语境的理解。此外,数据集的题目设计基于CRIT框架,模拟了大学课堂中的细读过程,使得评估更加贴近实际教学需求。
使用方法
KRISTEVA数据集的使用方法主要包括三个步骤:首先,模型需要通过多项选择题回答关于文学文本的细读问题;其次,研究者可以通过比较模型与人类评估者的表现,量化模型在解释性推理任务上的能力;最后,数据集还可用于研究模型在文学理解、多跳推理和语境检索等方面的表现。通过这种方式,KRISTEVA为评估大型语言模型在文学领域的理解和推理能力提供了标准化工具。
背景与挑战
背景概述
KRISTEVA数据集由McGill University、UT Austin和Microsoft Research等机构的研究人员于2025年创建,旨在填补大型语言模型(LLMs)在文学细读(close reading)任务评估上的空白。细读作为一种独特的文本解释推理形式,要求读者对文学和文化文本中的语言、形式和风格进行细致分析,以形成基于证据的论点。该数据集包含1331道多项选择题,改编自大学课堂数据,用于评估LLMs在文学理解与推理方面的能力。KRISTEVA的推出不仅为文学领域的研究提供了首个细读基准,还扩展了自然语言处理(NLP)社区对LLMs在复杂推理任务中表现的理解。
当前挑战
KRISTEVA数据集面临的挑战主要包括两个方面:领域问题的挑战和构建过程中的挑战。在领域问题方面,细读任务要求模型具备对文学文本中复杂语言现象(如修辞手法、风格特征)的识别与解释能力,以及多跳推理能力(结合文本特征与外部语境进行综合分析)。这些任务对LLMs的语言理解和推理能力提出了较高要求。在构建过程中,挑战包括:1)从非结构化的学生论文中提取结构化信息并生成高质量的多项选择题;2)确保生成的干扰项(distractors)既具有迷惑性又符合文学解释的合理性;3)处理文学解释中固有的主观性问题,即同一文本可能存在多种合理的解释。
常用场景
经典使用场景
KRISTEVA数据集作为首个专注于细读(close reading)任务的基准测试,为评估大型语言模型(LLMs)在文学文本解释性推理能力方面提供了重要工具。其经典使用场景包括对文学作品中修辞手法的识别、上下文信息的检索以及风格与外部语境的多跳推理。通过构建多层次的渐进式任务,该数据集能够全面评估模型在文学理解和批判性思维方面的表现。
解决学术问题
KRISTEVA填补了现有基准测试在文学领域评估的空白,解决了LLMs在解释性推理任务中缺乏标准化评估的问题。该数据集通过细读任务,量化了模型对文学文本中复杂语言现象的理解能力,包括修辞手法的提取、语境关联性判断以及多模态推理。其意义在于为文学计算和自然语言处理领域提供了首个专注于高阶解释性推理的评估框架,推动了模型在人文领域的应用研究。
衍生相关工作
围绕KRISTEVA数据集,已衍生出多个相关研究方向。在方法论层面,该工作启发了基于教育场景数据的基准构建范式;在技术层面,其多跳推理任务设计影响了后续文学理解模型的架构创新。典型衍生工作包括将细读框架扩展至多语言文学评估、开发基于解释性推理的模型微调方法,以及探索细读能力与其他高阶认知任务(如反事实推理)的关联性研究。
以上内容由遇见数据集搜集并总结生成


