wuwa_dialogue
收藏Hugging Face2025-02-11 更新2025-02-12 收录
下载链接:
https://huggingface.co/datasets/kang49/wuwa_dialogue
下载链接
链接失效反馈官方服务:
资源简介:
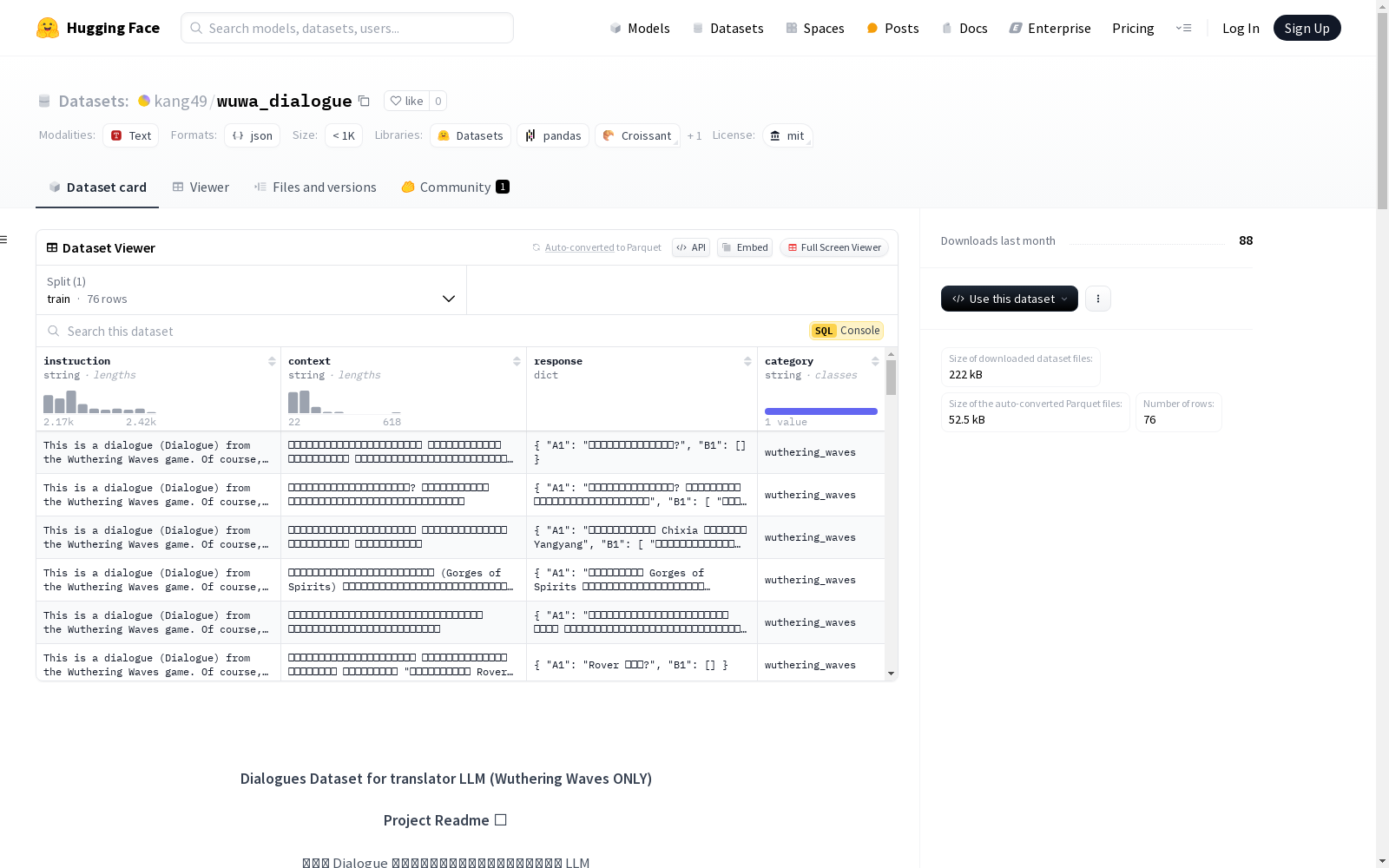
这是一个用于翻译游戏对话的数据集,专为Wuthering Waves游戏设计。该数据集利用LLM(大型语言模型)技术进行对话翻译。
创建时间:
2025-02-01
搜集汇总
数据集介绍
构建方式
wuwa_dialogue数据集的构建,旨在针对游戏对话进行机器翻译任务,特别针对Wuthering Waves游戏。数据集的构建涉及从游戏中提取对话文本,并通过机器学习模型,如Gemma2,对这些对话进行翻译。该过程包括数据的清洗、格式化以及利用OCR技术对游戏屏幕中的文本进行识别,进而形成可用于模型训练的文本对。
特点
该数据集的特点在于其专注于游戏对话的翻译,具有实际应用场景的针对性。数据集包含了从Wuthering Waves游戏中提取的对话文本,覆盖了游戏中的多种对话情景。此外,数据集使用了Gemma2模型进行翻译,该模型在对话翻译方面表现出色,保证了数据集的质量和实用性。
使用方法
使用wuwa_dialogue数据集时,用户首先需要从指定的GitHub页面下载程序执行文件,并配置相应的环境,包括下载Ollama平台和Gemma2模型。在使用过程中,程序将打开全屏覆盖,捕捉游戏中的对话文本,并通过模型进行实时翻译。用户需注意,程序对内存和GPU资源的需求较高,因此在低规格的计算机上运行时需要谨慎。
背景与挑战
背景概述
wuwa_dialogue数据集,旨在为大型语言模型(LLM)提供游戏对话的翻译数据,专注于Wuthering Waves游戏的对话内容。该数据集由软件工程师Kankawee Aramrak(kang49)创建于TensorMiK,其核心研究问题是如何利用LLM技术高效翻译游戏对话。此数据集的产生对于游戏本地化领域具有重要的参考价值,能够助力研究者开发出更加精准的翻译工具,进而推动游戏文化在全球范围内的传播与交流。
当前挑战
该数据集在研究领域面临的挑战主要包括:如何确保翻译的准确性和流畅性,以适应不同语境下的游戏对话;构建过程中遇到的挑战则包括对话数据的收集、处理和标注,以及与LLM模型的适配和性能优化等问题。此外,数据集的多样性和覆盖范围也是需要关注的重点,以确保能够满足不同游戏类型的翻译需求。
常用场景
经典使用场景
在自然语言处理领域,特别是在游戏对话翻译任务中,wuwa_dialogue数据集扮演着至关重要的角色。该数据集专门针对长篇游戏对话进行机器翻译,其经典的使用场景在于,通过训练先进的翻译模型,如Gemma2,实现对游戏内对话的实时翻译,提高玩家体验。
实际应用
在实用层面,wuwa_dialogue数据集的应用不仅限于学术研究,还广泛应用于游戏本地化过程中。它帮助开发者和翻译者高效地完成游戏对话的翻译工作,降低成本,缩短周期,使游戏内容更加贴近不同语言和文化背景的用户。
衍生相关工作
基于wuwa_dialogue数据集,衍生出了一系列相关的研究工作,如对话翻译模型的优化、游戏特定领域的语言模型构建等。这些研究进一步拓宽了数据集的应用范围,促进了机器翻译技术的多样化发展。
以上内容由遇见数据集搜集并总结生成


