voxlingua107_wds
收藏Hugging Face2025-08-28 更新2025-08-29 收录
下载链接:
https://huggingface.co/datasets/TalTechNLP/voxlingua107_wds
下载链接
链接失效反馈官方服务:
资源简介:
VoxLingua107是一个用于训练口语语言识别模型的语音数据集。该数据集由从YouTube视频自动提取的短语音片段组成,并根据视频标题和描述的语言进行标记,经过一些后处理步骤过滤掉假阳性。VoxLingua107包含107种语言的数据,训练集中的语音总量为6628小时,平均每种语言的数据量为62小时,但实际每种语言的数据量差异较大。还有一个独立的发展集,包含来自33种语言的1609个语音片段,由至少两名志愿者验证确实包含给定的语言。
提供机构:
Laboratory of Language Technology at Tallinn University of Technology
创建时间:
2025-08-27
原始信息汇总
VoxLingua107 数据集概述
数据集简介
VoxLingua107 是一个用于训练口语语言识别模型的语音数据集。该数据集包含从 YouTube 视频中自动提取的短语音片段,并根据视频标题和描述的语言进行标注,经过后处理步骤过滤误报。
关键特性
- 语言数量:包含 107 种语言的数据
- 总数据量:训练集语音总时长为 6628 小时
- 平均数据量:每种语言平均 62 小时(实际各语言数据量差异较大)
- 开发集:包含来自 33 种语言的 1609 个语音片段,经至少两名志愿者验证确认为对应语言
数据收集方法
通过使用语言特定搜索短语(从各语言维基百科随机选取)检索 YouTube 视频,提取音频数据。若视频标题和描述的语言与搜索短语语言匹配,则认为该视频音频可能为对应语言。采用语音/非语音检测和说话人日志技术将视频分割为短句级语音片段,并通过数据驱动的后过滤步骤移除与同语言其他片段差异过大的片段(可能非目标语言)。
数据质量说明
由于自动数据收集过程,数据集中仍存在约 2% 的片段非目标语言或包含非语音内容,某些语言(如威尔士语)此比例较高。
许可证信息
本数据集基于 Creative Commons Attribution 4.0 International License 分发。版权归视频原始所有者所有。
偏差说明
数据集中语言、口音、方言、性别、种族和社会因素的分布不能代表全球人口分布。使用此数据集训练和部署模型可能引入意外偏差。
语言数据量详情
数据集涵盖 107 种语言,各语言数据量详见原始表格(包含语言代码、语言名称和小时数)。
引用信息
如需引用本数据集,请使用以下格式:
@inproceedings{valk2021slt, title={{VoxLingua107}: a Dataset for Spoken Language Recognition}, author={J{"o}rgen Valk and Tanel Alum{"a}e}, booktitle={Proc. IEEE SLT Workshop}, year={2021}, }
搜集汇总
数据集介绍
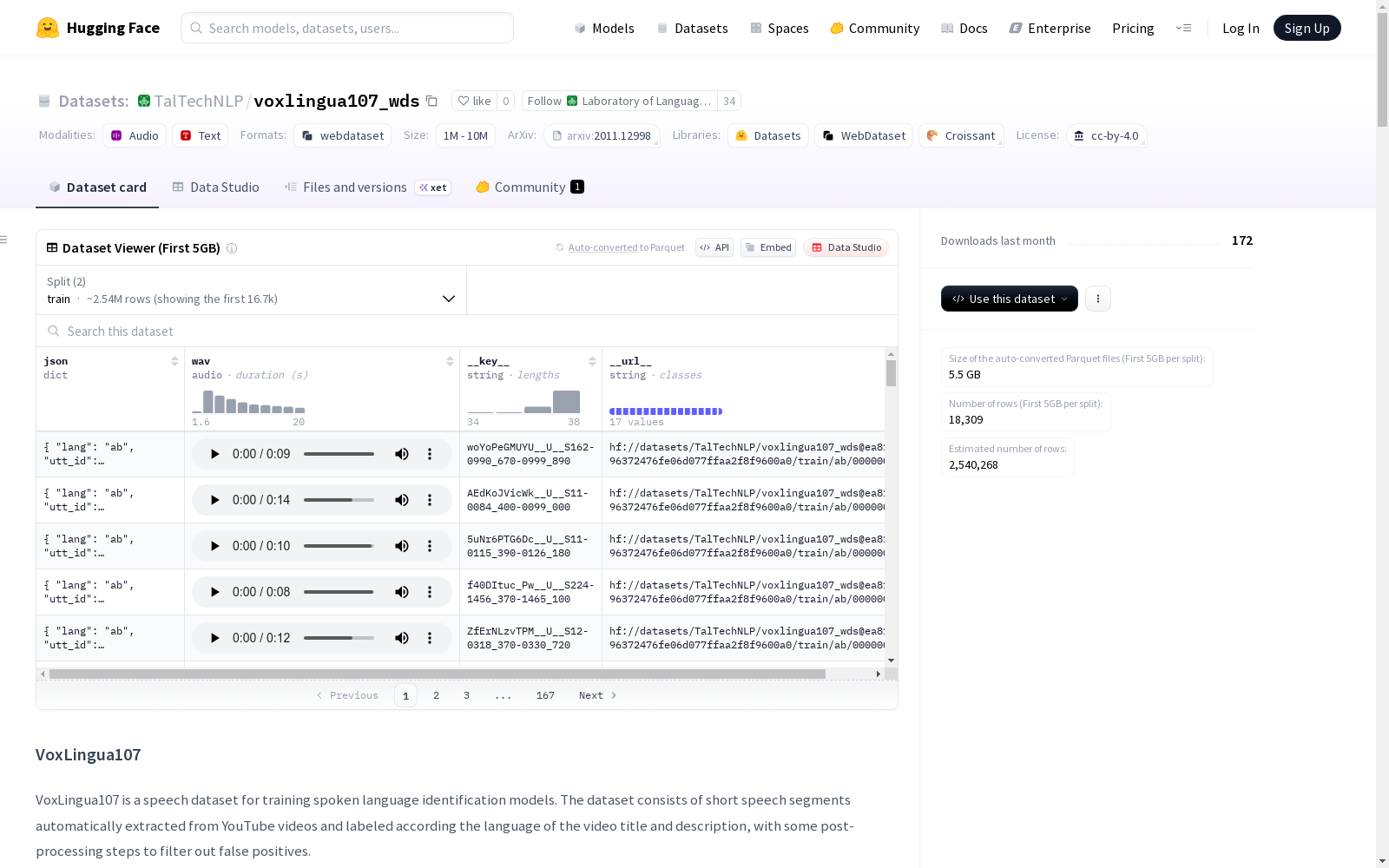
构建方式
在语音识别研究领域,大规模多语言数据集的构建对模型泛化能力至关重要。VoxLingua107通过从YouTube视频中自动提取语音片段构建而成,首先采用语言特定的维基百科随机短语进行视频检索,通过匹配视频标题和描述的语言标签初步筛选数据。随后运用语音活动检测和说话人日志技术将长音频分割为句子级片段,并通过数据驱动的后过滤机制移除与目标语言特征差异显著的异常样本,最终形成包含107种语言的语音数据集。
特点
该数据集涵盖107种语言,总时长达到6628小时,平均每种语言约62小时,但实际分布存在显著差异,如威尔士语等少数语言数据质量相对有限。数据集包含经过双重人工验证的1609段开发集样本,覆盖33种语言,确保了评估可靠性。尽管通过自动过滤降低了约2%的噪声,部分语言仍存在非目标语言片段或非语音内容,体现了真实场景下的数据复杂性。
使用方法
研究者可利用该数据集训练端到端的口语语言识别模型,特别适用于真实场景下的多语言语音处理任务。开发集为模型调优和评估提供可靠基准,用户可通过Hugging Face平台直接加载预处理后的数据格式。需要注意的是,由于数据采集自网络视频,模型部署时需考虑潜在的地域口音、性别及社会文化偏差,建议结合领域自适应技术提升模型鲁棒性。
背景与挑战
背景概述
VoxLingua107由塔林科技大学的研究团队于2021年推出,旨在构建大规模多语言语音识别数据集。该数据集涵盖107种语言,总时长超过6600小时,通过自动化流程从YouTube视频中提取语音片段并标注语言类别。其创新性在于采用数据驱动的后过滤技术降低标注噪声,为语音语言识别研究提供了重要资源,显著推动了跨语言语音处理模型的发展。
当前挑战
该数据集核心挑战在于解决真实场景中多语言语音识别的复杂性,包括方言变体、背景噪声和语速差异等问题。构建过程中面临自动标注可靠性不足的困难,需通过语音活动检测和说话人日志化技术分割音频,并采用统计过滤减少误标注,但部分语言如威尔士语仍存在约2%的噪声样本。数据分布不均衡及潜在的社会偏见也是需要关注的问题。
常用场景
经典使用场景
在语音技术研究领域,VoxLingua107数据集广泛应用于多语言语音识别系统的训练与评估。该数据集通过自动采集YouTube多语言语音片段并经过严格过滤处理,为研究者提供了覆盖107种语言、总时长超过6628小时的丰富语音资源。其经典使用场景包括构建高精度的语种识别模型,特别是在处理真实环境中的嘈杂语音、方言变体及跨语言语音样本时展现出卓越性能。
解决学术问题
该数据集有效解决了语音识别研究中低资源语言数据匮乏的核心难题。通过提供大规模多语言平行语音数据,支持了端到端语种检测模型的开发,显著提升了模型在非平衡语言分布下的泛化能力。其引入的数据清洗与验证机制为语音数据质量控制设立了新标准,推动了语种识别领域从实验室环境向实际应用场景的范式转变。
衍生相关工作
该数据集催生了多项突破性研究,包括SpeechBrain团队开发的ECAPA-TDNN语种识别模型,其在跨语言泛化性能上树立了新的基准。后续研究基于该数据集提出了多任务学习框架,将语种识别与语音情感分析相结合。此外,还衍生出针对低资源语言的对抗训练方法,以及基于自监督学习的语音表示模型,这些工作显著推动了多模态语音处理技术的发展。
以上内容由遇见数据集搜集并总结生成


