有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
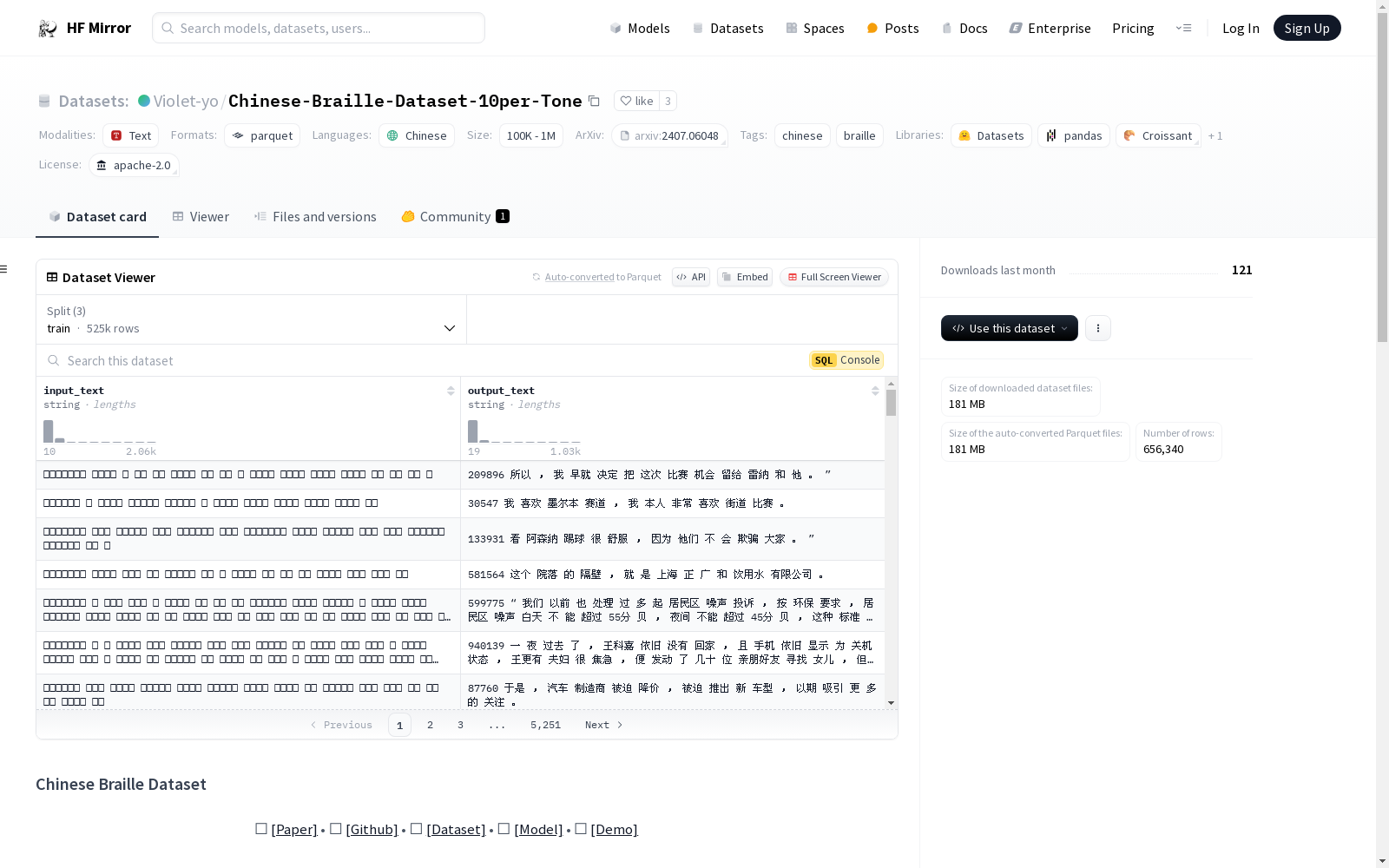
Chinese-Braille-10per-Tone 数据集解决了公开可用中文盲文数据集稀缺的问题。原始中文文本数据来源于公开的 Leipzig Corpora Collection,包含2007年至2009年间从新闻媒体收集的100万条独立句子。
中文汉字通过中国盲文在线平台的工具转换为“全音调”盲文,形成 Chinese-Braille-Dataset-Full-Tone 数据集。该工具基于规则的方法标注汉字发音并转换为盲文,但有时会返回错位数据和乱码。经过数据清洗和去重后,数据集大小减少至约60万条句子。
随机移除 Chinese-Braille-Dataset-Full-Tone 数据集中90%的音调,生成 Chinese-Braille-10per-Tone 数据集,以模拟现实世界中盲文使用中约90%音调被省略的情况。通过识别和排除数字及标点符号,确保仅移除音调标记。
此外,还创建了 Chinese-Braille-Dataset-No-Tone 数据集,移除了 Chinese-Braille-Dataset-Full-Tone 数据集中的所有音调。
| # 样本数 | 盲文长度(均值/中位数)字符串 | 盲文长度(均值/中位数)标记 | 中文长度(均值/中位数)字符串 | 中文长度(均值/中位数)标记 | |
|---|---|---|---|---|---|
| 训练集 | 525072 | 145/112 | 149/115 | 74/64 | 59/51 |
| 验证集 | 65634 | 117/96 | 121/99 | 71/62 | 57/50 |
| 测试集 | 65634 | 107/90 | 111/93 | 72/63 | 58/50 |
CatMeows
该数据集包含440个声音样本,由21只属于两个品种(缅因州库恩猫和欧洲短毛猫)的猫在三种不同情境下发出的喵声组成。这些情境包括刷毛、在陌生环境中隔离和等待食物。每个声音文件都遵循特定的命名约定,包含猫的唯一ID、品种、性别、猫主人的唯一ID、录音场次和发声计数。此外,还有一个额外的zip文件,包含被排除的录音(非喵声)和未剪辑的连续发声序列。
huggingface 收录
LFW
人脸数据集;LFW数据集共有13233张人脸图像,每张图像均给出对应的人名,共有5749人,且绝大部分人仅有一张图片。每张图片的尺寸为250X250,绝大部分为彩色图像,但也存在少许黑白人脸图片。 URL: http://vis-www.cs.umass.edu/lfw/index.html#download
AI_Studio 收录
VisDrone2019
VisDrone2019数据集由AISKYEYE团队在天津大学机器学习和数据挖掘实验室收集,包含288个视频片段共261,908帧和10,209张静态图像。数据集覆盖了中国14个不同城市的城市和乡村环境,包括行人、车辆、自行车等多种目标,以及稀疏和拥挤场景。数据集使用不同型号的无人机在各种天气和光照条件下收集,手动标注了超过260万个目标边界框,并提供了场景可见性、对象类别和遮挡等重要属性。
github 收录
MedDialog
MedDialog数据集(中文)包含了医生和患者之间的对话(中文)。它有110万个对话和400万个话语。数据还在不断增长,会有更多的对话加入。原始对话来自好大夫网。
github 收录
Data_on_Data_Analysts
我们正在探索数据分析师职位的就业市场趋势:需求技能、薪资变化和招聘模式。该数据集汇编了美国数据分析师职位的招聘信息,直接来源于Google的职位搜索结果。数据收集始于2022年11月4日,并持续增长,每天新增约100个职位信息,提供了当前就业市场的持续更新快照。
github 收录