xcodemind/vision2ui
收藏Hugging Face2024-07-01 更新2024-04-19 收录
下载链接:
https://hf-mirror.com/datasets/xcodemind/vision2ui
下载链接
链接失效反馈官方服务:
资源简介:
Vision2UI是一个从真实场景中提取的、包含丰富布局信息的数据集,专门用于微调多模态大语言模型(MLLMs)以生成UI代码。该数据集通过精心收集、清理和精炼开源Common Crawl数据集创建,确保了高质量。数据集包含超过三百万个并行样本,每个样本包括网页截图、布局信息、网页代码文本、截图比例、页面内容的主要语言、HTML和CSS代码的令牌计数、神经评分器生成的评分以及图像的哈希码。此外,数据集还引入了新的度量标准TreeBLEU来评估生成网页与源代码的结构相似性,并提出了基于Vision Transformer的基线模型UICoder。
Vision2UI is a dataset extracted from real-world scenarios and rich in layout information, specifically designed for fine-tuning multi-modal large language models (MLLMs) to generate UI code. It is constructed by carefully collecting, cleaning, and refining the open-source Common Crawl dataset to guarantee high data quality. The dataset contains over three million parallel samples, where each sample comprises webpage screenshots, layout information, webpage code text, screenshot aspect ratio, the primary language of the page content, token counts of HTML and CSS codes, scores generated by a neural scorer, and the image's hash code. Additionally, this dataset introduces a novel metric TreeBLEU for evaluating the structural similarity between generated webpages and their source codes, and proposes a Vision Transformer-based baseline model named UICoder.
提供机构:
xcodemind
原始信息汇总
数据集概述
数据集名称
- Vision2UI
数据集描述
- Vision2UI 是一个专为从用户界面(UI)设计图像自动生成网页代码而设计的数据集。该数据集通过精心处理开放源代码的Common Crawl数据集,包含超过三百万个平行样本,包括UI设计图像、网页代码和布局信息。
数据集特点
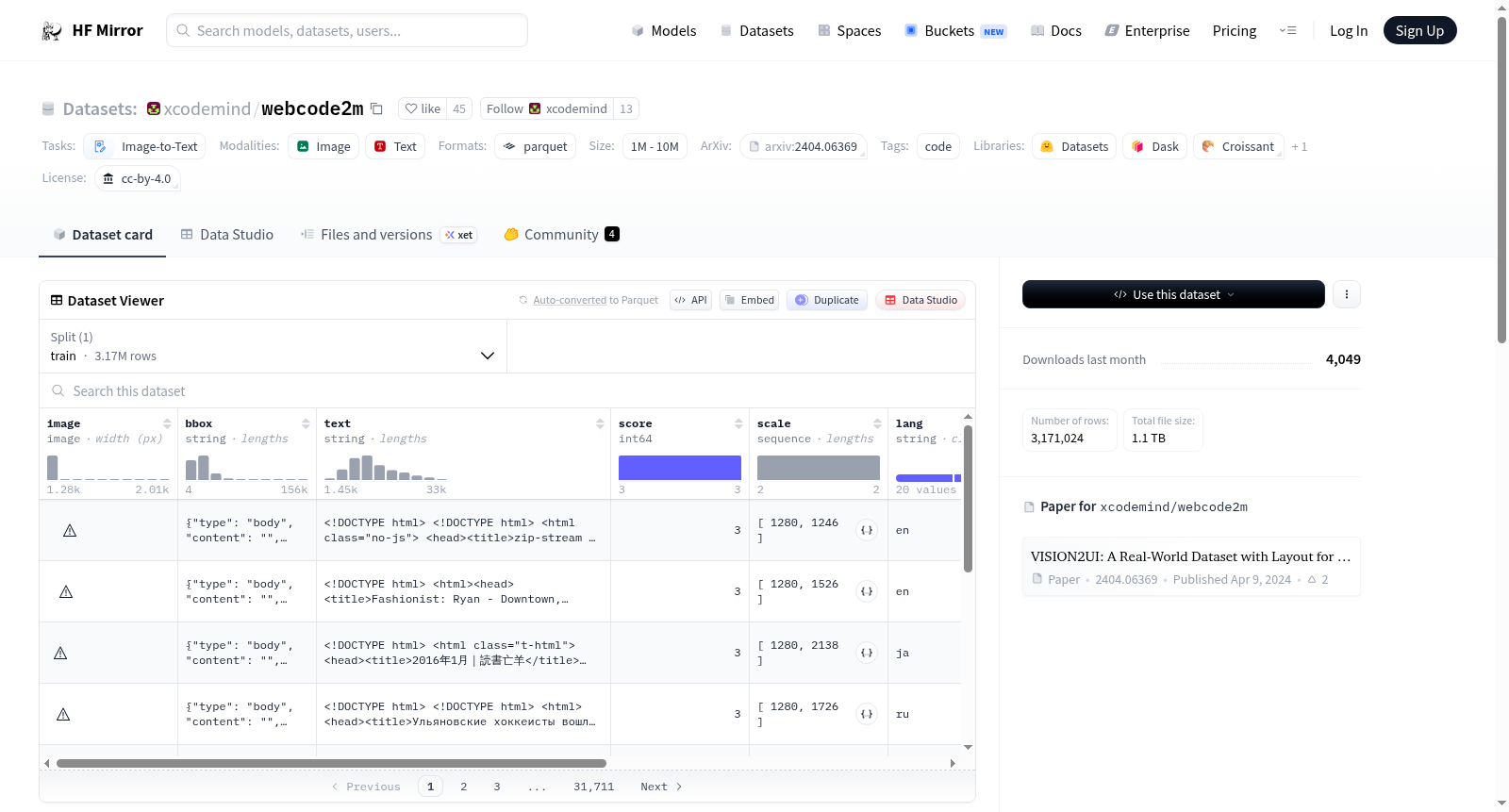
- 图像(image):网页截图。
- 边界框(bbox):网页元素的布局信息,包括大小、位置和层次信息。
- 文本(text):包含HTML/CSS代码的网页代码文本。
- 比例(scale):截图的尺寸,格式为[宽度, 高度]。
- 语言(lang):渲染页面上显示的主要文本内容的语言(不包括HTML/CSS代码),支持20种语言。
- 令牌(tokens):HTML和CSS代码的令牌计数,格式为[CSS长度, HTML长度]。
- 分数(score):由论文中提出的神经评分器获得的分数。
- 哈希(hash):图像对象的哈希代码。
数据集用途
- 用于微调多模态大型语言模型(MLLMs),以提高从UI设计图像自动生成网页代码的性能。
数据集配置
- 默认配置(config_name: default)
- 数据文件路径:
data/*.parquet - 数据分割:
train
- 数据文件路径:
许可证
- CC-BY-4.0
数据集链接
- 项目主页:Vision2UI
搜集汇总
数据集介绍
构建方式
在自动化前端开发的浪潮中,高质量的图文数据对于训练多模态大语言模型至关重要。Vision2UI(亦称WebCode2M)数据集应运而生,其构建过程严谨而系统。该数据集从真实互联网资源中采集了256万个实例,每个实例均包含网页设计截图、对应的HTML/CSS代码及布局边界框信息。为确保数据质量,研究团队设计了一套评分模型,通过美学评估与完整性检测,自动过滤掉低质量或不完整的样本,从而保留了高质量、高还原度的网页设计-代码对。
特点
Vision2UI数据集以其真实性与规模性在同类数据集中独树一帜。它涵盖了20种主要语言的网页内容,并提供了详细的布局层次信息(包括元素尺寸、位置与层级关系),以及代码的token统计与截图缩放比例。数据集还附带了由高精度语言检测模型生成的语种标签,便于多语言场景下的模型训练与评估。此外,经过净化处理的增强版本进一步过滤了不当内容,确保了数据使用的安全性。
使用方法
该数据集以Parquet格式存储,通过HuggingFace Datasets库可便捷加载。用户可按照标准图像到文本(image-to-text)任务范式进行使用:将网页截图作为视觉输入,对应的HTML/CSS代码作为文本输出,同时可结合布局边界框信息进行结构化生成。数据集提供了训练集拆分,支持直接用于微调多模态大语言模型。此外,研究者还可利用其提供的TreeBLEU指标,对模型生成的代码结构层次进行精准评估。
背景与挑战
背景概述
在当今数字化时代,前端开发中从网页设计图自动生成代码的需求日益迫切,这不仅能显著降低开发者的工作负荷,还能提升开发效率。然而,现有的大规模多模态语言模型(MLLMs)在自动网页代码生成任务上表现欠佳,其根本原因在于缺乏高质量、大规模且源自真实世界的训练数据集。为填补这一空白,研究人员于2024年提出了WebCode2M(亦称Vision2UI)数据集,由相关团队创建。该数据集包含256万个实例,每个实例均由真实网页截图、对应的HTML/CSS代码及布局边界框信息构成,数据来源覆盖多种现实应用场景。通过引入基于美学和完整性的评分模型进行质量筛选,WebCode2M确保了数据的高可用性。该数据集在相关领域内具有重要影响力,为MLLMs在网页代码生成方向的进步提供了坚实基础,并催生了基于Vision Transformer的基线模型WebCoder及新型评估指标TreeBLEU,推动了前端设计工具智能化的发展。
当前挑战
WebCode2M数据集所面临的挑战主要体现在两个层面。在领域问题层面,自动网页代码生成任务的核心难点在于如何从复杂多变的网页设计图像中精准还原出结构化的代码与布局,这要求模型同时理解视觉元素的空间关系、层次结构以及对应的语义标签,而现有MLLMs在处理此类细粒度多模态映射时仍存在显著性能瓶颈。在数据集构建过程中,挑战则更为具体:首先,从互联网海量资源中收集真实网页数据时,不可避免地会混入低质量或包含不当内容(如暴力或敏感素材)的样本,尽管通过评分模型进行了过滤,仍难以完全剔除。其次,为确保数据的多样性和代表性,需要覆盖20种不同语言的文本内容,这增加了语言检测与处理的复杂性。此外,代码与布局信息的对齐标注过程要求高精度,而不同网页的代码风格与结构差异巨大,进一步提升了数据标准化的难度。
常用场景
经典使用场景
在视觉与代码的交叉领域中,Vision2UI(亦称WebCode2M)作为迄今规模最大的真实网页设计到代码生成数据集,凭借其256万组涵盖设计截图、布局边界框与完整HTML/CSS代码的实例,为多模态大语言模型(MLLMs)提供了前所未有的训练与评测基准。研究者可基于该数据集探索从像素级视觉表征到结构化代码序列的映射关系,尤其适用于端到端页面代码生成任务的模型微调与性能验证。
衍生相关工作
基于该数据集衍生的经典工作包括WebCoder基线模型,其以Vision Transformer为核心架构验证了真实数据对MLLMs代码生成能力的显著提升效果。此外,数据集的净化版本(webcode2m_purified)为过滤不当内容提供了实践范例,而TreeBLEU指标的提出则引发了关于代码结构评估方法的新一轮讨论,推动了布局感知型生成模型与层次化代码质量评估体系的后续研究。
数据集最近研究
最新研究方向
Vision2UI(WebCode2M)数据集聚焦于多模态大语言模型在网页前端代码自动生成领域的前沿探索。随着多模态大语言模型(MLLMs)在视觉-语言任务中展现卓越能力,如何利用真实世界的大规模数据驱动网页设计到代码的端到端生成成为研究热点。该数据集包含256万实例,涵盖设计图像、对应网页代码及布局边界框信息,为克服现有模型因缺乏高质量真实世界数据而性能不足的瓶颈提供了关键支撑。当前研究前沿方向包括:基于Vision Transformer(ViT)的基线模型WebCoder的构建,以及新型评估指标TreeBLEU的提出,后者通过测量结构化层级召回率更精准地评估代码生成质量。该数据集还揭示出复杂布局理解、多语言适配及内容安全性过滤等实际挑战,推动前端自动化工具向更鲁棒、更实用的方向发展。其影响在于为MLLMs在自动化UI编码这一垂直场景中建立标准化基准,并为未来结合视觉布局与结构化代码生成的跨模态研究奠定坚实基础。
以上内容由遇见数据集搜集并总结生成


