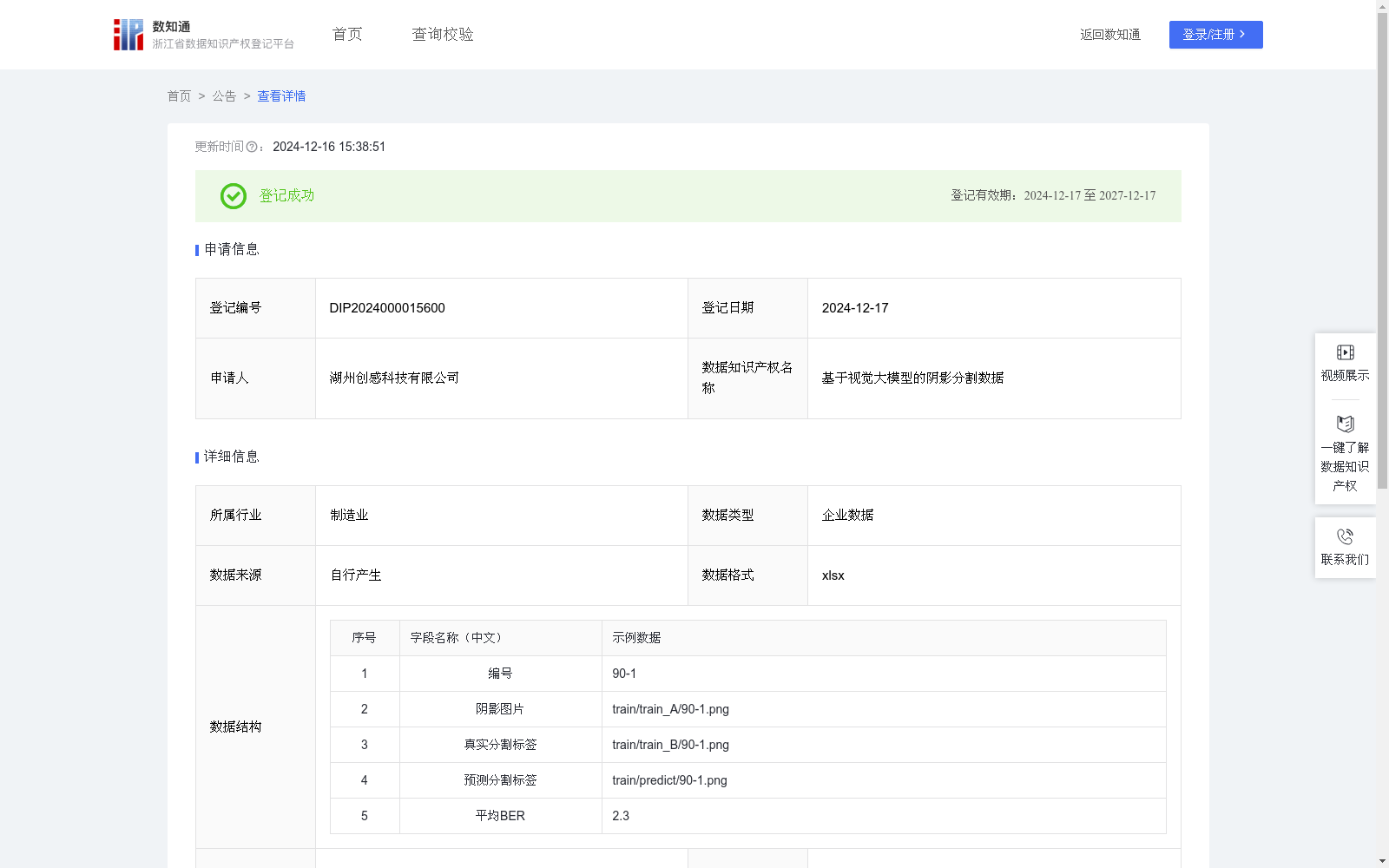
基于视觉大模型的阴影分割数据
收藏浙江省数据知识产权登记平台2024-12-16 更新2024-12-17 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/104900
下载链接
链接失效反馈官方服务:
资源简介:
阴影分割技术在计算机视觉领域,尤其是自动驾驶、机器人视觉、环境感知等应用中具有重要意义。通过对阴影区域的精确分割,可以有效区分真实物体和阴影,提升图像理解和场景分析的精度。本场景应用于基于视觉大模型的阴影分割,利用深度学习模型对图像中的阴影区域进行精确分割,并评估其性能表现。该技术可以广泛应用于图像处理、图像增强、自动驾驶、无人机监测等领域,帮助提高视觉识别系统在复杂环境下的鲁棒性。数据收集:在阴影分割任务中,收集包含阴影和非阴影区域的图像数据。数据集中的每个条目包括一张阴影图像、其对应的真实分割标签。阴影图像是在自然光场景下采集,有不同程度阴影区域的图片。真实分割标签,是公司内部专业技术人员按照像素级别标注,用于视觉大模型的训练监督。
数据预处理:在预处理阶段,对输入图像进行标准化处理,将阴影区域与非阴影区域标记为不同的类别。对图像进行尺寸调整、色彩均衡、噪声去除等操作,以确保数据的一致性。
模型构建:使用基于视觉大模型SAM在阴影分割数据上微调。模型的输入为经过预处理的阴影图片,输出为阴影与非阴影的二分类结果。在模型中,输入的图像通过多个卷积层进行特征提取,然后通过多层自注意力模块捕捉图像中不同区域的依赖关系,最后对每个像素进行分类,得到阴影分割结果。公式为:P=f_θ(I),其中f_θ表示视觉大模型,参数为θ,P为模型输出的预测分割标签。采用比特错误率(BER)作为模型性能的评估指标。比特错误率度量了预测分割标签与真实标签之间的差异,公式为BER = (1 / N) * Σ |y_i - p_i|, 其中 N 为像素总数,y_i 为真实分割标签,p_i 为预测分割标签。
Shadow segmentation technology holds significant importance in the field of computer vision, particularly in applications such as autonomous driving, robotic vision, and environmental perception. Accurate segmentation of shadow regions can effectively distinguish real objects from shadows, enhancing the accuracy of image understanding and scene analysis. This scenario is applied to shadow segmentation based on vision large models, which use deep learning models to precisely segment shadow regions in images and evaluate their performance. This technology can be widely applied in fields including image processing, image enhancement, autonomous driving, and unmanned aerial vehicle (UAV) monitoring, helping to improve the robustness of visual recognition systems in complex environments.
Data Collection: For the shadow segmentation task, image data containing both shadow and non-shadow regions is collected. Each entry in the dataset consists of a shadow image and its corresponding ground-truth segmentation label. The shadow images are collected under natural light scenes, with varying degrees of shadow coverage. The ground-truth segmentation labels are annotated at the pixel level by internal professional technical personnel of the company, and are used for training supervision of vision large models.
Data Preprocessing: During the preprocessing stage, standardized processing is performed on the input images, with shadow regions and non-shadow regions marked as different categories. Operations such as image resizing, color equalization, and noise removal are conducted to ensure data consistency.
Model Construction: The vision large model SAM is fine-tuned on the shadow segmentation dataset. The input of the model is the preprocessed shadow images, and the output is the binary classification result for shadow vs. non-shadow. In the model, the input image undergoes feature extraction via multiple convolutional layers, then captures dependencies between different regions in the image through multi-layer self-attention modules, and finally classifies each pixel to obtain the shadow segmentation result. The formula is: $P = f_ heta(I)$, where $f_ heta$ represents the vision large model with parameter $ heta$, and $P$ is the predicted segmentation label output by the model. Bit Error Rate (BER) is adopted as the evaluation metric for model performance. BER measures the difference between the predicted segmentation label and the ground-truth label, with the formula: $BER = (1 / N) * Sigma |y_i - p_i|$, where $N$ is the total number of pixels, $y_i$ is the ground-truth segmentation label, and $p_i$ is the predicted segmentation label.
提供机构:
湖州创感科技有限公司
创建时间:
2024-11-14
搜集汇总
数据集介绍
特点
该数据集包含1001条阴影分割数据,适用于计算机视觉领域,特别是自动驾驶和机器人视觉等应用。数据集通过深度学习模型进行阴影区域的精确分割,已在浙江省知识产权区块链公共存证平台存证。
以上内容由遇见数据集搜集并总结生成


