WinoGrande (Winograd Schema Challenge on a Grand Scale)
收藏winogrande.allenai.org2024-10-25 收录
下载链接:
https://winogrande.allenai.org/
下载链接
链接失效反馈官方服务:
资源简介:
WinoGrande是一个大规模的Winograd模式挑战数据集,旨在测试自然语言理解系统的能力。该数据集包含44k个问题,这些问题设计得非常微妙,需要理解上下文和常识推理才能正确回答。
WinoGrande is a large-scale Winograd Schema Challenge dataset designed to evaluate the capabilities of natural language understanding systems. This dataset contains 44k questions that are meticulously crafted to be highly nuanced, necessitating contextual comprehension and commonsense reasoning to answer correctly.
提供机构:
winogrande.allenai.org
搜集汇总
数据集介绍
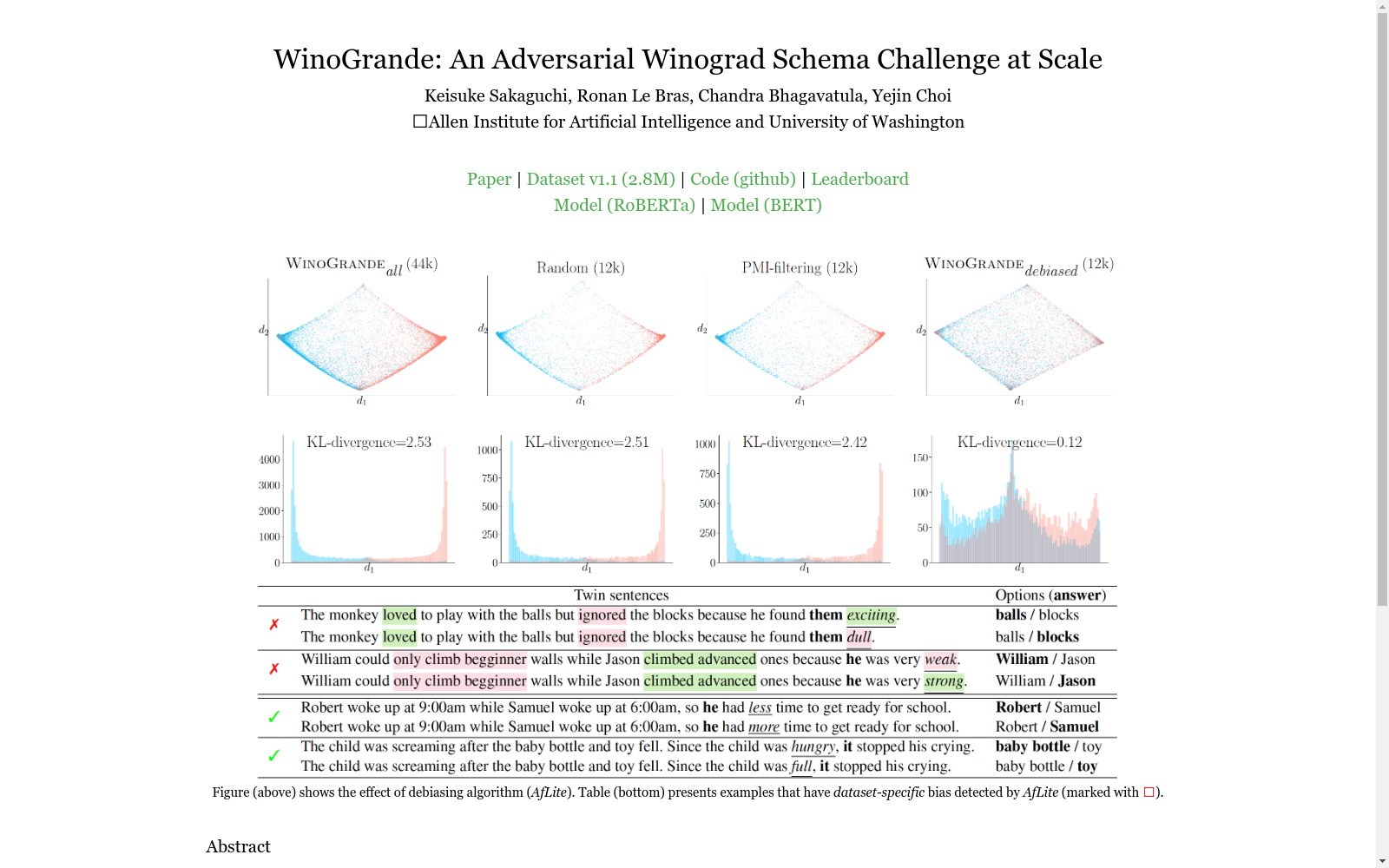
构建方式
WinoGrande数据集的构建基于Winograd Schema Challenge(WSC)的原理,通过大规模扩展和多样化语料库来生成。该数据集包含了超过44,000个自然语言理解任务,每个任务都设计为测试系统对上下文敏感的代词消解能力。构建过程中,研究人员采用了多种语言模型和人工标注相结合的方法,确保了数据集的高质量和多样性。
特点
WinoGrande数据集的主要特点在于其规模和复杂性。相较于传统的WSC数据集,WinoGrande提供了更为广泛和多样化的语言实例,涵盖了不同领域和语境下的代词消解问题。此外,该数据集还特别注重于测试模型在处理歧义和复杂语境时的表现,从而为自然语言理解研究提供了更为全面的评估基准。
使用方法
WinoGrande数据集适用于多种自然语言处理任务,特别是那些需要高精度代词消解和上下文理解的应用。研究人员可以通过该数据集评估和改进其语言模型的性能,尤其是在处理复杂和歧义语境时的表现。此外,WinoGrande也可用于开发和测试新的自然语言理解算法,帮助推动该领域的前沿研究。
背景与挑战
背景概述
WinoGrande数据集诞生于自然语言处理领域对复杂推理能力的需求日益增长之际。该数据集由艾伦人工智能研究所(Allen Institute for AI)于2019年发布,旨在解决传统Winograd Schema Challenge(WSC)数据集规模较小、难以有效评估现代大型语言模型推理能力的问题。WinoGrande通过扩展WSC的规模和多样性,提供了一个更为全面和严格的测试平台,显著推动了自然语言推理(NLI)技术的发展。其影响力不仅体现在学术研究中,还对工业界开发更智能的对话系统和问答系统产生了深远影响。
当前挑战
WinoGrande数据集在构建过程中面临多项挑战。首先,扩展Winograd Schema Challenge的规模需要大量高质量的文本数据,这要求研究团队具备强大的数据收集和处理能力。其次,确保数据集的多样性和代表性,以避免模型过拟合特定类型的推理问题,是一个复杂且耗时的任务。此外,评估模型的推理能力时,如何设计公平且有效的评估指标,也是一个亟待解决的问题。这些挑战不仅考验了研究团队的技术实力,也推动了自然语言处理领域对更复杂推理任务的研究和探索。
发展历史
创建时间与更新
WinoGrande数据集由Sakaguchi等人在2019年创建,旨在扩展和改进Winograd Schema Challenge,以更好地评估自然语言理解能力。该数据集自创建以来,未有公开的更新记录。
重要里程碑
WinoGrande数据集的创建标志着自然语言处理领域对复杂推理任务的重视。其核心里程碑包括:1)扩展了原始Winograd Schema Challenge的规模,包含44k个问题,显著提升了数据集的多样性和挑战性;2)引入了新的评估指标,以更全面地衡量模型在解决歧义和推理任务中的表现;3)通过公开竞赛和学术研究,推动了自然语言理解模型的发展和优化。
当前发展情况
当前,WinoGrande数据集已成为自然语言处理研究中的重要基准之一,广泛应用于模型评估和算法改进。其对相关领域的贡献意义在于,通过提供大规模、高质量的推理任务数据,促进了模型在复杂语境下的理解和推理能力的提升。此外,WinoGrande的公开性和多样性,也为跨领域的研究合作提供了丰富的资源和平台,进一步推动了人工智能在语言理解方面的前沿探索。
发展历程
- WinoGrande数据集首次发表,旨在解决Winograd Schema Challenge的规模问题,提供了一个大规模的基准测试集,以评估自然语言理解模型的性能。
- WinoGrande数据集首次应用于多个自然语言处理研究项目,成为评估模型在复杂语境下理解和推理能力的重要工具。
- WinoGrande数据集被广泛用于学术界和工业界的研究,推动了自然语言理解技术的发展,特别是在解决歧义和复杂推理任务方面。
常用场景
经典使用场景
WinoGrande数据集在自然语言处理领域中,主要用于评估和提升机器理解复杂语言结构的能力。其经典使用场景包括但不限于:通过设计大量具有歧义性的句子,测试模型在上下文理解、指代消解和逻辑推理方面的表现。例如,数据集中的句子常包含多个可能的解释,要求模型根据上下文选择最合理的解释,从而模拟人类在日常交流中的语言理解过程。
衍生相关工作
WinoGrande数据集的发布激发了大量相关研究工作,推动了自然语言处理领域的创新。例如,基于WinoGrande的改进模型在多个基准测试中取得了显著成绩,展示了其在处理复杂语言任务中的优势。此外,该数据集还促进了跨学科研究,如心理学和语言学的结合,探索人类和机器在语言理解上的差异和共性。这些衍生工作不仅丰富了学术研究,也为实际应用提供了新的思路和方法。
数据集最近研究
最新研究方向
在自然语言处理领域,WinoGrande数据集因其大规模的Winograd模式挑战而备受关注。最新研究主要集中在提升模型对复杂语境的理解能力,特别是在多义词和隐含逻辑推理方面。研究者们通过引入更复杂的预训练任务和多任务学习框架,旨在增强模型在处理歧义和上下文依赖性问题上的表现。此外,跨语言迁移学习和零样本学习也成为研究热点,以验证模型在不同语言和文化背景下的通用性和鲁棒性。这些研究不仅推动了自然语言理解技术的发展,也为人工智能在实际应用中的可靠性提供了新的视角。
相关研究论文
- 1WinoGrande: An Adversarial Winograd Schema Challenge at ScaleAllen Institute for AI · 2020年
- 2Evaluating the Robustness of Neural Language Models to Input PerturbationsUniversity of California, Berkeley · 2020年
- 3On the Cross-lingual Transferability of Monolingual RepresentationsUniversity of Amsterdam · 2020年
- 4A Survey of Winograd Schema Challenge Datasets and ApproachesUniversity of Cambridge · 2021年
- 5Improving Natural Language Understanding by Incorporating Unsupervised LearningStanford University · 2021年
以上内容由遇见数据集搜集并总结生成


