ChineseWebText2.0
收藏Hugging Face2024-11-27 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/CASIA-LM/ChineseWebText2.0
下载链接
链接失效反馈官方服务:
资源简介:
ChineseWebText2.0是一个大规模的高质量中文网络文本数据集,包含3.8 TB的数据。每个文本都附有质量评分、领域单标签和多标签、以及毒性分类和评分,使LLM研究人员能够根据新的质量阈值选择数据。数据集通过MDFG-tool进行构建和过滤,确保数据的高质量和多维度的细粒度信息。
ChineseWebText2.0 is a large-scale high-quality Chinese web text dataset containing 3.8 terabytes of data. Each text in the dataset is annotated with quality scores, single-domain labels, multi-label annotations, as well as toxicity classification and toxicity scores, enabling LLM researchers to select data based on novel quality thresholds. The dataset is constructed and filtered using the MDFG-tool, ensuring its high quality and multi-dimensional fine-grained information.
创建时间:
2024-11-15
原始信息汇总
ChineseWebText 2.0 数据集概述
数据集概览
- 数据量: 3.8 TB
- 数据类型: 中文网页文本
- 数据特点:
- 包含质量评分
- 领域单标签和多标签
- 毒性分类和评分
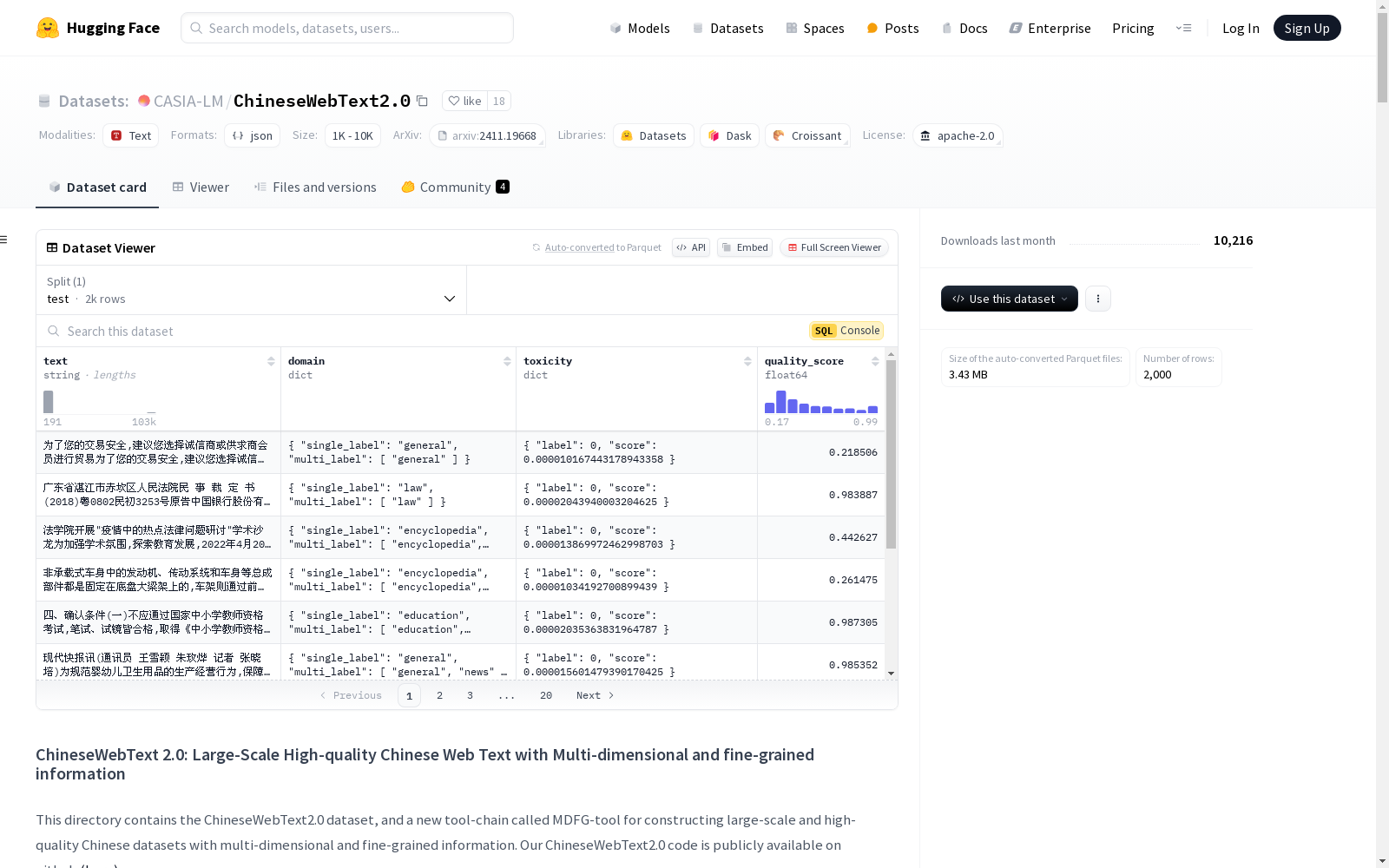
数据示例
json { "text": "近日,黑龙江省高校校报协会第十四届学术年会暨校报工作交流研讨会在东北农业大学举行。我校10件新闻作品喜获2项一等奖,2项二等奖,6项三等奖……", "domain": { "single_label": "news", "multi_label": ["news", "education"] }, "toxicity": { "label": 0, "score": 1.0347155694034882e-05 }, "quality_score": 0.96044921875 }
数据字段说明
- text: 文本内容
- single_label: 领域分类模型的最高概率标签
- multi_label: 领域分类模型生成的所有概率高于阈值的标签
- label: 毒性分类模型生成的毒性标签
- score: 毒性分类模型生成的毒性评分
- quality_score: 质量评估模型生成的质量评分
数据处理工具
- MDFG-tool: 用于构建大规模高质量中文数据集的工具链,包括粗粒度过滤、质量评估、领域分类和毒性评估等模块。
数据分析
数据移除率
- 原始数据量: 6.6 TB
- 预处理后数据量: 3.8 TB
- 移除率:
- 准备阶段: 32.32%
- 预处理阶段: 43.33%
数据质量分布
- 质量评分区间:
- [0.2, 0.4): 18%
- [0.9, 1.0): 18%
- [0.1, 0.2): 少量
- 人类接受度:
- [0.5, 1.0): 90%以上
- [0.1, 0.2): 80%
领域分布
- 总体领域分布:
- 百科: 33.43%
- 通用: 32.63%
- 新闻: 28.01%
- 数学: 0.55%
- 质量相关领域分布:
- 各质量区间内的领域分布与总体分布一致
数据毒性分析
- 毒性评分分布:
- 非毒性数据: 97.41%
- 毒性数据: 3.16 GB (1,632,620 样本)
- 与其他毒性数据集对比:
- 数据量最大,每条文本包含毒性评分
引用
- 使用数据或代码时,请引用相关论文。
搜集汇总
数据集介绍
构建方式
ChineseWebText2.0数据集的构建过程采用了多维度和细粒度信息处理工具链MDFG-tool。初始阶段通过规则过滤模块对原始数据进行清洗,确保文本长度和敏感词等标准符合要求。随后,基于BERT模型进行文本质量评估,生成质量评分,并通过设定阈值提取高质量文本。接着,使用FastText模型对清洗后的数据进行单标签和多标签分类,同时进行毒性评估,过滤有害内容并为每段文本分配毒性评分。最终,数据集经过多阶段处理,从原始6.6TB数据中筛选出3.8TB高质量中文文本。
特点
ChineseWebText2.0数据集以其大规模和高品质著称,包含3.8TB的中文文本数据。每段文本均附有质量评分、单标签和多标签领域分类、毒性分类及评分等多维度信息。数据集中,高质量文本主要集中在中等评分区间,且高评分区间(0.9-1.0)占比显著,表明数据集整体质量较高。此外,毒性分析显示97.41%的文本为非毒性内容,毒性评分超过0.99的文本被单独分类,为研究者提供了丰富的毒性数据资源。
使用方法
ChineseWebText2.0数据集适用于大语言模型(LLM)的研究与训练。研究者可根据质量评分、领域标签和毒性评分等维度筛选数据,以满足特定研究需求。例如,通过设定质量阈值提取高质量文本,或利用毒性评分优化模型的安全性。数据集的多维度信息为模型训练提供了灵活的选择空间,有助于提升模型在特定领域的表现和安全性。
背景与挑战
背景概述
ChineseWebText 2.0是由中国科学院自动化研究所的研究团队于2024年发布的大规模高质量中文网络文本数据集,旨在为大规模语言模型(LLM)的研究提供多维度和细粒度的信息支持。该数据集包含3.8 TB的文本数据,每段文本均附有质量评分、领域单标签和多标签、毒性分类及评分等丰富信息,为研究者提供了基于质量阈值的数据选择能力。通过引入MDFG-tool工具链,研究团队实现了从粗粒度过滤到细粒度标注的全流程自动化处理,显著提升了数据集的构建效率和质量。ChineseWebText 2.0的发布不仅填补了中文大规模高质量文本数据集的空白,还为LLM在中文语境下的训练和优化提供了重要资源。
当前挑战
ChineseWebText 2.0在构建过程中面临多重挑战。首先,原始数据中包含了大量无关和噪声内容,如何高效地过滤和清理这些低质量数据成为首要难题。研究团队通过规则筛选和BERT模型的质量评估,逐步剔除了不符合要求的文本,最终保留了高质量数据。其次,领域分类和毒性评估的准确性直接影响了数据集的可用性,研究团队采用FastText模型进行多标签分类和毒性评分,确保数据的多维信息标注精准可靠。此外,如何在保证数据多样性的同时提升整体质量,也是构建过程中的一大挑战。通过精细化的处理流程和严格的质量控制,研究团队成功构建了一个兼具规模与质量的中文文本数据集,为LLM的研究和应用提供了坚实基础。
常用场景
经典使用场景
ChineseWebText2.0数据集在自然语言处理领域中被广泛应用于大规模语言模型的训练与优化。其多维度、细粒度的信息标注,如质量评分、领域标签和毒性分类,使得研究人员能够根据特定需求筛选高质量数据,提升模型的性能与安全性。该数据集尤其适用于中文语言模型的预训练与微调,帮助模型更好地理解和生成中文文本。
实际应用
在实际应用中,ChineseWebText2.0数据集被广泛用于中文搜索引擎、智能客服、内容推荐系统等场景。其高质量、多领域覆盖的文本数据能够提升这些系统的语义理解能力和生成效果。此外,毒性分类功能使得系统能够有效过滤有害内容,确保生成文本的安全性与合规性,广泛应用于社交媒体、新闻平台等需要内容审核的场景。
衍生相关工作
ChineseWebText2.0数据集衍生了一系列经典研究工作,特别是在中文语言模型的预训练与微调领域。基于该数据集,研究人员开发了多种优化算法和模型架构,提升了中文语言模型的生成质量与安全性。此外,该数据集还推动了中文毒性检测与过滤技术的研究,为构建更安全的中文自然语言处理系统提供了重要支持。
以上内容由遇见数据集搜集并总结生成


