DocVQA
收藏arXiv2021-01-05 更新2024-07-25 收录
下载链接:
https://www.docvqa.org/
下载链接
链接失效反馈官方服务:
资源简介:
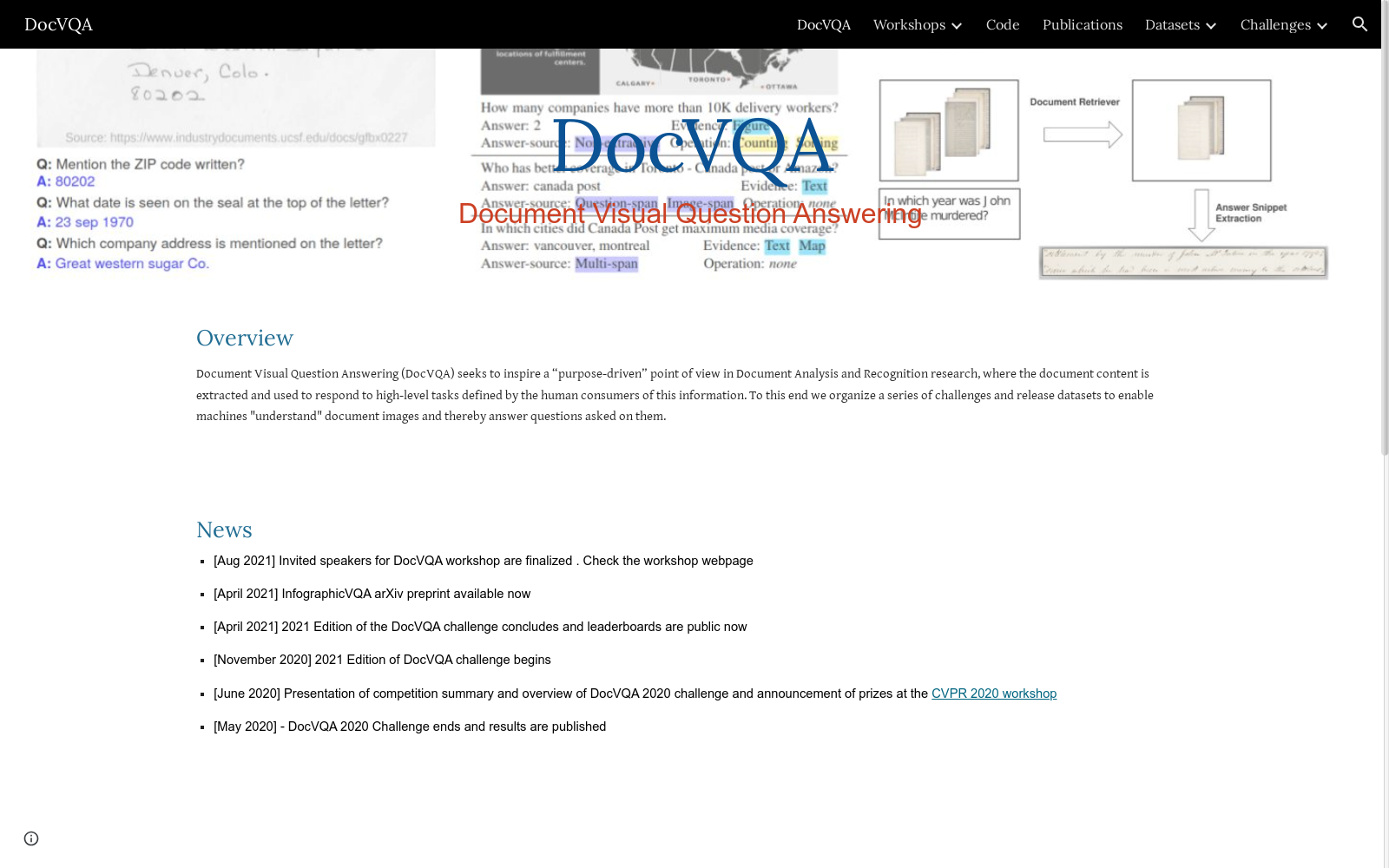
DocVQA是由印度海得拉巴IIIT的CVIT和西班牙UAB的计算机视觉中心创建的一个大规模文档图像视觉问答数据集。该数据集包含超过12,000个文档图像和50,000个问题,旨在通过视觉和文本信息解决文档理解中的高层次问题。数据集中的图像来源于UCSF工业文档图书馆,涵盖多种文档类型和行业。DocVQA的创建过程涉及远程工作者使用网络工具进行标注,确保数据的质量和多样性。该数据集的应用领域包括文档分析、信息提取和自动问答系统,旨在提高机器对文档内容的理解和响应能力。
DocVQA is a large-scale visual question answering dataset for document images, created by the CVIT at IIIT Hyderabad in India and the Computer Vision Center at UAB in Spain. This dataset contains over 12,000 document images and 50,000 questions, aiming to address high-level problems in document understanding via visual and textual information. The images in the dataset are sourced from the UCSF Industry Documents Library, covering a wide range of document types and industries. The construction of DocVQA involved remote workers conducting annotations through web-based tools, ensuring the quality and diversity of the dataset. Its application domains include document analysis, information extraction and automated question answering systems, with the objective of improving machines' capability to understand and respond to document content.
提供机构:
计算机视觉中心,UAB,西班牙
创建时间:
2020-07-01
搜集汇总
数据集介绍
构建方式
DocVQA 数据集的构建主要分为数据收集和标注两个阶段。数据收集阶段从 UCSF Industry Documents Library 中挑选了 6071 份来自不同行业和年代的文档,并从中选择了包含表格、表单、列表和图表等元素的页面。标注阶段则分为三个阶段,首先由远程工作人员在文档图像上定义最多 10 个问题-答案对,并鼓励提供多个正确答案;然后进行数据验证,要求工作人员为每个问题分配一个或多个问题类型;最后,如果第一阶段和第二阶段的答案不匹配,则由作者进行审查和编辑。
特点
DocVQA 数据集具有以下特点:1) 规模大,包含 12767 张文档图像和 50000 个问题;2) 类型多样,涵盖表格、表单、列表、图表等多种文档类型;3) 问题类型丰富,根据推理需求分为表格/列表、表单、布局、运行文本、手写文本等多种类型;4) 真实性高,数据来自真实文档,而非合成图像。
使用方法
DocVQA 数据集可用于评估和训练文档图像问答模型。使用者可以根据自己的需求选择不同的模型进行评估,例如 VQA 模型、阅读理解模型等。同时,数据集还提供了基线结果,可以帮助使用者了解现有模型的性能和局限性。
背景与挑战
背景概述
DocVQA数据集由Minesh Mathew和Dimosthenis Karatzas等研究人员于2021年1月发布,旨在推动文档视觉问答(DocVQA)领域的研究。该数据集包含超过12,000张文档图像和50,000个问题,涵盖了各种类型的文档,包括表格、表单和图形等。DocVQA旨在解决文档分析和识别(DAR)领域中的信息提取问题,通过定义在文档图像上的视觉问答任务,促使DAR算法进行条件性解释,从而推动DAR研究向“目标驱动”的方向发展。该数据集的发布为文档图像理解领域的研究提供了重要的数据基础,并对相关领域产生了深远的影响。
当前挑战
DocVQA数据集面临着一些挑战。首先,现有模型在解决文档图像上的视觉问答问题时,其性能与人类相比存在较大差距。其次,模型在理解文档结构方面存在困难,尤其是在需要理解文档结构才能回答的问题上。此外,文档图像中包含大量高密度的语义信息,这给模型的推理能力提出了更高的要求。最后,文档图像中的文本内容可能存在OCR错误,这可能导致模型无法正确回答问题。为了解决这些挑战,需要进一步研究和开发新的模型和方法,以提高模型在文档图像理解方面的性能和推理能力。
常用场景
经典使用场景
DocVQA数据集在文档图像视觉问答(VQA)任务中具有重要应用。该数据集包含超过12,000张文档图像和50,000个问题,涵盖了多种文档类型,包括表格、表单和图表等。研究人员可以使用DocVQA数据集来训练和评估视觉问答模型,以理解文档图像中的文本、布局和结构信息,并回答自然语言问题。例如,模型可以学习如何从表格中提取信息,识别文档中的标题和页码,或理解图表和图像的含义。
衍生相关工作
DocVQA数据集衍生了许多相关的经典工作,推动了视觉问答和阅读理解领域的研究进展。例如,LoRRA和M4C等视觉问答模型在DocVQA数据集上取得了良好的性能,并揭示了文档图像理解中的关键挑战。此外,BERT等预训练语言模型在DocVQA数据集上也取得了显著的成果,为视觉问答和阅读理解任务提供了新的思路。这些相关工作进一步推动了视觉问答和阅读理解领域的研究,并为开发更先进的文档图像理解模型提供了重要参考。
数据集最近研究
最新研究方向
DocVQA数据集的最新研究方向主要聚焦于文档图像的视觉问答(VQA)任务,旨在推动文档分析和识别(DAR)研究向“目的驱动”的方向发展。该数据集包含了12,767张不同类型和内容的文档图像,以及50,000个问答对,旨在训练模型理解和回答关于文档内容的自然语言问题。DocVQA数据集的引入,为研究文档图像的理解和问答提供了新的视角,有助于推动DAR算法的进步。
相关研究论文
- 1DocVQA: A Dataset for VQA on Document Images计算机视觉中心,UAB,西班牙 · 2021年
以上内容由遇见数据集搜集并总结生成


