多任务画布数据集
收藏arXiv2025-11-27 更新2025-11-28 收录
下载链接:
https://snap-research.github.io/canvas-to-image/
下载链接
链接失效反馈官方服务:
资源简介:
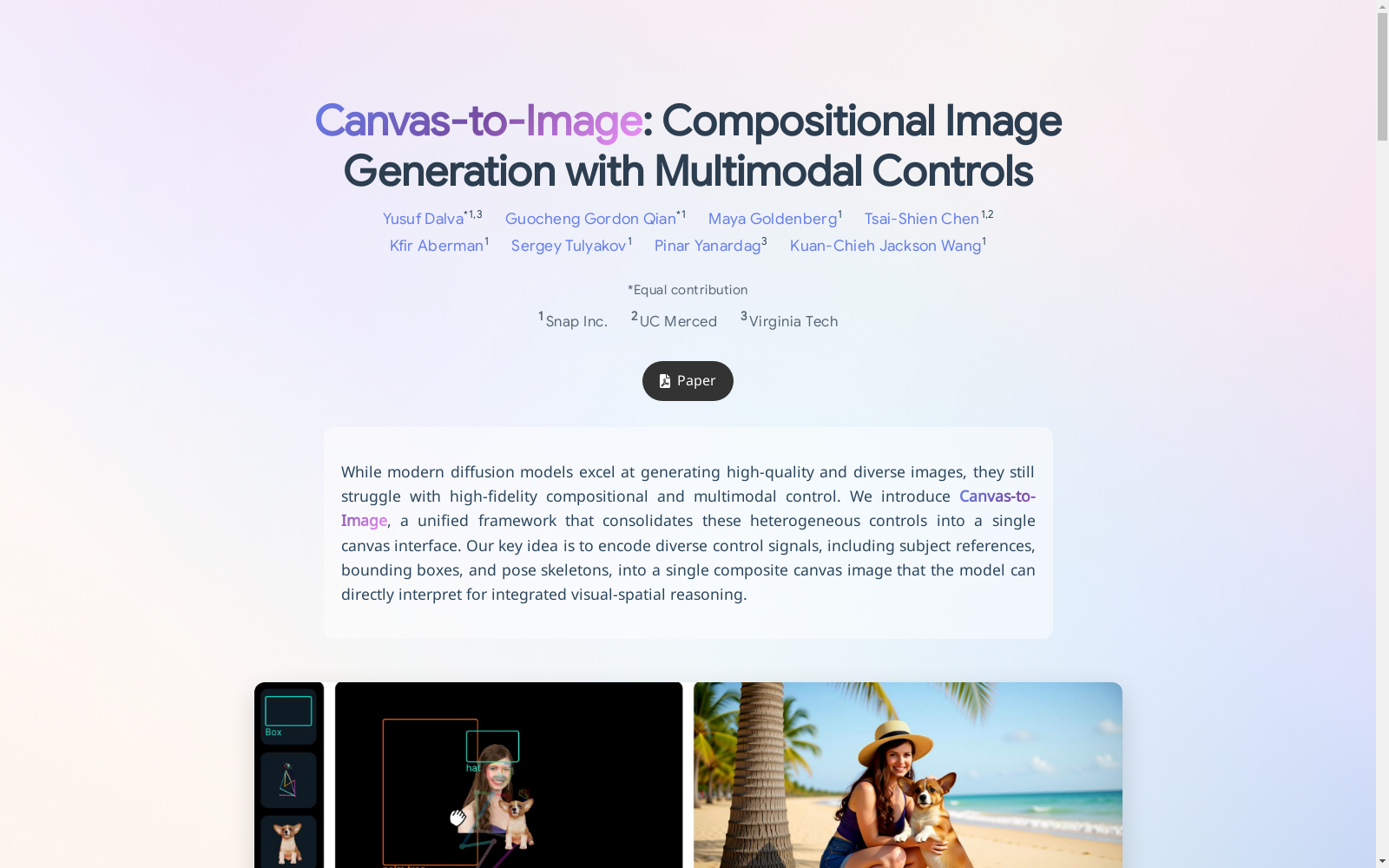
本研究构建的多任务画布数据集是一个大规模以人为中心的跨帧图像集合,包含来自100万个独特身份的600万张图像。该数据集通过跨帧采样策略实现灵活的组合构建,支持空间画布、姿态画布和边界框画布三种变体的生成。数据集主要应用于多模态控制的组合图像生成领域,旨在解决扩散模型在同时处理文本提示、主题参考、空间排列和姿态约束时的协同控制难题,为数字艺术和内容创作提供精准的可控生成能力。
The multi-task canvas dataset constructed in this study is a large-scale human-centric cross-frame image collection, containing 6 million images from 1 million unique identities. This dataset enables flexible composite construction via a cross-frame sampling strategy, and supports the generation of three variants: spatial canvas, pose canvas, and bounding box canvas. The dataset is primarily applied in the field of multimodal-controlled composite image generation, aiming to address the collaborative control challenges faced by diffusion models when simultaneously processing text prompts, subject references, spatial arrangements, and pose constraints, thereby providing precise controllable generation capabilities for digital art and content creation.
提供机构:
Snap公司、弗吉尼亚理工大学、加州大学默塞德分校
创建时间:
2025-11-27
搜集汇总
数据集介绍
构建方式
多任务画布数据集的构建采用跨模态统一表征策略,将空间布局、姿态约束和边界框标注等异构控制信号编码为单一RGB画布图像。通过从大规模内部人像数据集和外部标注数据源中提取语义对齐样本,构建了空间画布、姿态画布和边界框画布三种变体。每种画布变体通过特定视觉编码机制实现控制信号的像素级融合,例如空间画布通过跨帧组合避免复制伪影,姿态画布采用半透明骨架叠加保留结构信息,边界框画布则直接集成文本标注与空间坐标。
特点
该数据集的核心特征在于其多模态协同控制能力,通过统一画布接口实现异构信号的联合解析。数据集涵盖600万张人像样本与100万组场景数据,支持跨帧组合与多任务课程学习。其创新性体现在单任务训练样本可泛化至多控制推理场景,即使训练阶段未出现控制组合,模型仍能保持身份保持度与结构一致性。数据集的视觉语义对齐机制确保了文本提示、空间约束与姿态引导的协同作用,在4P组合、姿态控制等复杂基准测试中展现出卓越的泛化性能。
使用方法
使用该数据集时需遵循多任务画布训练框架,将扩散模型与视觉语言模型架构结合。输入画布经VLM编码为语义嵌入,与VAE潜在表示拼接后作为条件输入。训练阶段采用均匀采样策略平衡各控制任务,通过任务指示符区分画布类型以避免模式混淆。推理阶段支持多控制组合生成,模型基于流匹配损失优化参数,在保持基础模型图像质量的同时,通过低秩适应技术微调注意力与调制层。该使用方法在身份保存、控制遵循等指标上显著优于现有方法,适用于数字艺术创作与内容生成等场景。
背景与挑战
背景概述
多任务画布数据集由Snap研究院与弗吉尼亚理工大学等机构于2025年联合提出,旨在解决扩散模型在多模态组合控制中的核心难题。该数据集通过统一的视觉画布界面,整合了文本提示、空间布局、姿态约束和主体参考等异构控制信号,为创造性图像生成提供了结构化数据支持。其创新性体现在将传统孤立控制任务转化为协同推理范式,显著提升了数字艺术和内容创作领域中对多条件生成任务的处理能力。
当前挑战
该数据集面临的领域挑战在于突破扩散模型在异构控制信号协同推理时的局限性,需同时满足身份保持、姿态对齐和空间布局等多重约束。构建过程中的技术挑战涉及跨模态数据的对齐与融合,包括从大规模人像数据中提取空间构图与姿态标注,以及将边界框注释与文本标签映射到统一画布空间时保持语义一致性。此外,训练策略需平衡单任务学习与多控制泛化能力,避免模型在未见过控制组合时出现模态冲突。
常用场景
经典使用场景
在生成式人工智能领域,多任务画布数据集为文本到图像生成任务提供了统一的视觉界面。该数据集通过整合空间布局、姿态约束和边界框标注等异构控制信号,构建了一个复合RGB画布作为输入表示。这种设计使得扩散模型能够直接解析多种控制模态,在数字艺术创作和内容生成场景中实现精确的多对象组合控制。
实际应用
在商业设计领域,该数据集支撑的生成系统可直接应用于广告创意制作和虚拟场景构建。设计师通过直观的画布界面即可协调人物姿态、物体位置和文本标注的复杂组合,显著提升了数字内容的生产效率。在影视预可视化领域,该系统能够快速生成符合分镜要求的场景构图,为实际拍摄提供可靠的视觉参考。
衍生相关工作
基于该数据集提出的统一画布范式,后续研究衍生出分层控制架构和动态画布生成等创新方向。部分工作将画布扩展为包含透明度通道的RGBA格式,突破了原始RGB画布的信息密度限制。另有研究结合大语言模型的推理能力,实现了从自然语言描述到复杂画布布局的自动转换,进一步拓展了该框架的应用边界。
以上内容由遇见数据集搜集并总结生成


