Babelscape/rebel-dataset
收藏Hugging Face2023-06-15 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Babelscape/rebel-dataset
下载链接
链接失效反馈官方服务:
资源简介:
REBEL数据集是为关系抽取任务创建的,通过链接Wikidata和Wikipedia生成数据,并使用自然语言推理(NLI)进行过滤。数据集为英文,来源于英文Wikipedia,包含大量的文本和三元组信息。数据集支持的任务包括文本检索和关系抽取,主要用于训练模型从原始文本中提取三元组(主语、宾语和关系类型)。数据集的结构包括数据实例、数据字段和数据分割,数据实例包含Wikipedia文章的标题、上下文和线性化的三元组。数据集的创建过程涉及自动化的数据收集和注释,数据来源于Wikipedia和Wikidata。使用该数据集时需要考虑其可能反映的Wikipedia和Wikidata中的偏见,并且数据集仅用于非商业研究目的。
The REBEL dataset is developed for the relation extraction task, which is constructed by linking Wikidata and Wikipedia, and filtered via natural language inference (NLI). It is an English-only dataset sourced from English Wikipedia, encompassing substantial volumes of textual data and triple information. The tasks supported by this dataset cover text retrieval and relation extraction, and it is mainly utilized for training models to extract triples (comprising subject, object, and relation type) from raw text. The dataset's structure includes three core components: data instances, data fields, and data splits. Each data instance contains the title, contextual content, and linearized triples of a Wikipedia article. The creation process of the dataset involves automated data collection and annotation, with its source materials originating from Wikipedia and Wikidata. When utilizing the REBEL dataset, users should be mindful of the potential biases present in Wikipedia and Wikidata that the dataset may reflect. Additionally, the dataset is only authorized for non-commercial research purposes.
提供机构:
Babelscape
原始信息汇总
数据集概述
数据集基本信息
- 名称: REBEL-dataset
- 语言: 英语
- 许可证: cc-by-sa-4.0
- 多语言性: 单语种
- 数据来源: 原始数据
- 任务类别: 文本检索、文本生成
- 标签: 关系抽取、条件文本生成
数据集描述
- 概述: 该数据集用于关系抽取,通过链接Wikidata和Wikipedia创建,使用NLI进行过滤。
- 支持任务: 关系抽取,旨在从原始文本中提取三元组(主体、客体和关系类型)。
- 语言: 数据集语言为英语,来源于英文Wikipedia。
数据集结构
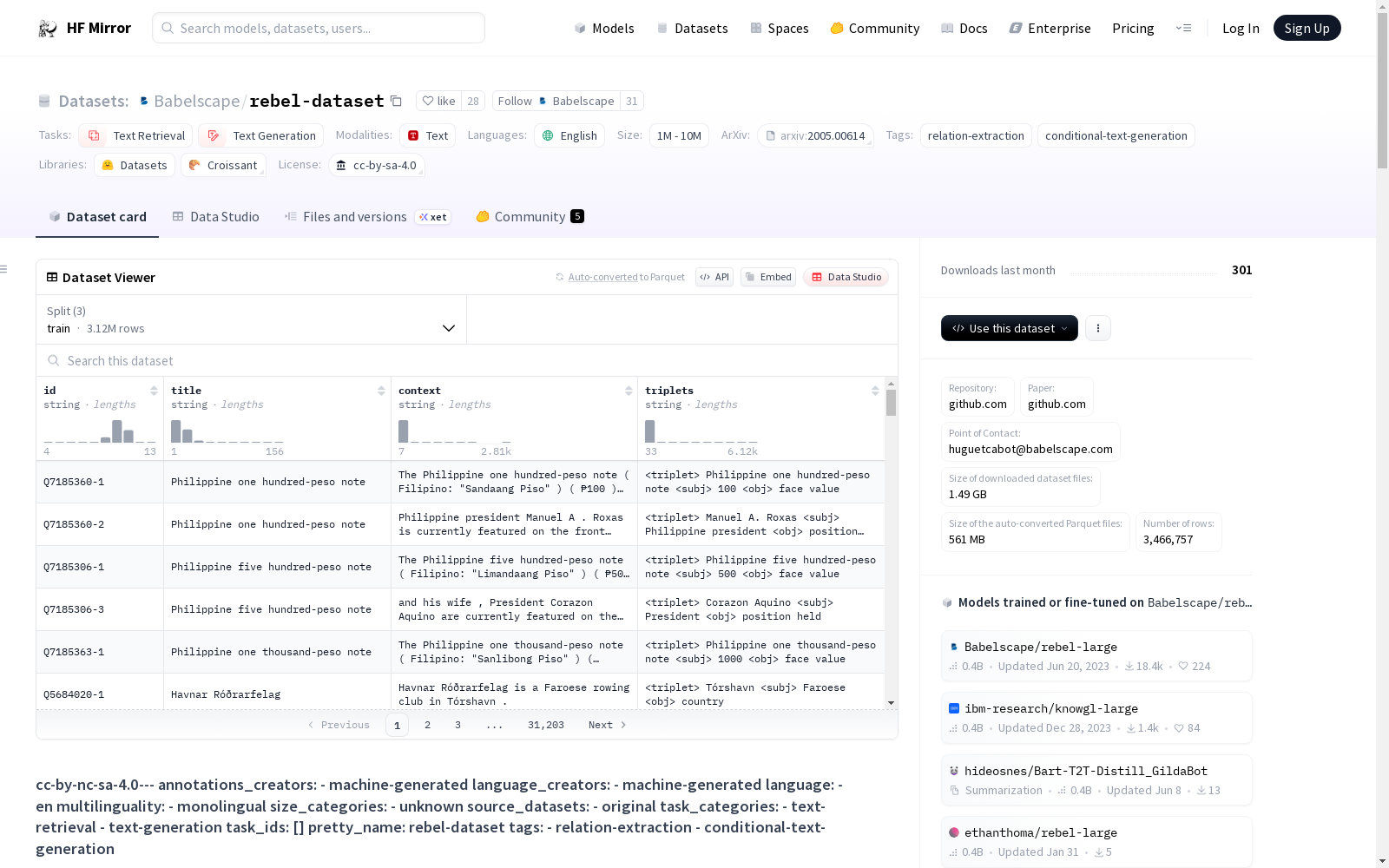
- 数据实例: 数据集包含Wikipedia文章的ID、标题、上下文和三元组信息。
- 数据字段:
id: 实例的唯一ID,与Wikipedia页面匹配。title: Wikipedia页面的标题。context: 用于关系抽取任务的Wikipedia文章内容。triplets: 文本中存在的三元组的线性化版本。
- 数据分割: 测试和验证集各占原始数据的5%。
数据集创建
- 采集与规范化: 数据集通过cRocoDiLe管道从Wikipedia和Wikidata收集和规范化。
- 注释过程: 数据集的注释过程是自动化的。
- 源语言生产者: 任何Wikipedia和Wikidata的贡献者。
使用数据集的考虑
- 社会影响: 数据集作为关系抽取模型的预训练步骤,应谨慎使用。
- 偏见讨论: 数据集可能反映Wikipedia和Wikidata中的偏见。
- 其他已知限制: 目前无其他已知限制。
附加信息
- 数据集管理员: Pere-Lluis Huguet Cabot, Roberto Navigli
- 许可证信息: 数据集内容受Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License (CC BY-NC-SA 4.0)限制。
- 引用信息: 请参考提供的BibTex格式引用。
搜集汇总
数据集介绍
构建方式
REBEL数据集的构建基于对Wikipedia和Wikidata的深度挖掘,采用自动化的数据提取流程cRocoDiLe进行关系抽取,并以自然语言推理(NLI)系统过滤不成立的triplets。该数据集的创建旨在为关系抽取任务提供预训练数据,其核心为通过端到端的文本生成方式进行关系抽取,具体细节可在相关论文中查阅。
特点
该数据集的特点在于其自动化构建过程,以及结合了Wikidata的triplets与Wikipedia的文本内容。数据集包含的triplets经过NLI系统的筛选,确保了与文本的相关性。此外,数据集以英语为语言,专注于单一语言的单语环境,便于特定语言环境下的研究与应用。
使用方法
使用REBEL数据集时,用户需关注其提供的线性化的triplets格式,以及每个实例所包含的上下文信息。数据集分为训练、验证和测试三个部分,其中测试和验证部分各占总数据的5%。用户可通过数据集中的ID字段将数据点映射回对应的Wikipedia页面,便于进一步的分析和应用。
背景与挑战
背景概述
REBEL数据集是由Babelscape公司创建的,旨在通过链接Wikidata和Wikipedia进行关系抽取任务。该数据集的创建时间为2021年,主要研究人员为Pere-Lluis Huguet Cabot和Roberto Navigli,他们分别来自Babelscape公司以及罗马萨皮恩扎大学。REBEL数据集的核心研究问题是自动化地从一个大规模的文本 corpus 中抽取关系,其研究成果对自然语言处理领域的关系抽取任务产生了显著影响。该数据集的创建基于一个自动化的数据提取管道cRocoDiLe,该管道利用NLI过滤技术,从Wikipedia和Wikidata中提取关系三元组。
当前挑战
REBEL数据集在构建过程中遇到的挑战主要包括:1) 如何自动化地处理大规模的Wikipedia和Wikidata数据,以实现高效的关系抽取;2) 如何利用NLI技术对提取的关系三元组进行有效过滤,以确保数据质量;3) 数据集可能存在的偏差问题,因为数据源自动采集自Wikipedia和Wikidata,可能反映了这些来源的内在偏差。此外,数据集的银标准标注特性可能导致训练出的模型产生幻觉现象。
常用场景
经典使用场景
在自然语言处理领域,Babelscape/rebel-dataset 数据集的经典使用场景是作为训练素材,用于构建和优化关系提取模型。该数据集通过将Wikidata和Wikipedia进行关联,为模型训练提供了丰富的三元组(主体、关系、客体)实例,助力模型理解和识别文本中的语义关系。
衍生相关工作
基于Babelscape/rebel-dataset 数据集,研究者已经开展了一系列相关工作,如进一步探索关系提取的模型架构,提升模型对复杂语义的理解能力,以及结合其他任务(如实体识别、文本分类)进行多任务学习,以实现更全面的自然语言处理系统。
数据集最近研究
最新研究方向
Babelscape/rebel-dataset 数据集近期研究方向主要聚焦于利用该数据集进行关系抽取任务,尤其是通过端到端的语言生成模型进行预训练。该数据集通过结合Wikidata和Wikipedia的数据,采用自动化的数据提取流程构建而成,旨在为模型训练提供支持。前沿研究不仅探索了模型在关系抽取方面的性能,还关注了数据集可能存在的偏差和局限性,以及如何通过该数据集促进模型对关系抽取任务的理解。这些研究对于提升自然语言处理模型在知识图谱构建和文本理解方面的能力具有重要意义。
以上内容由遇见数据集搜集并总结生成


