AmodalSynthDrive
收藏arXiv2024-03-11 更新2024-06-21 收录
下载链接:
http://amodalsynthdrive.cs.uni-freiburg.de
下载链接
链接失效反馈官方服务:
资源简介:
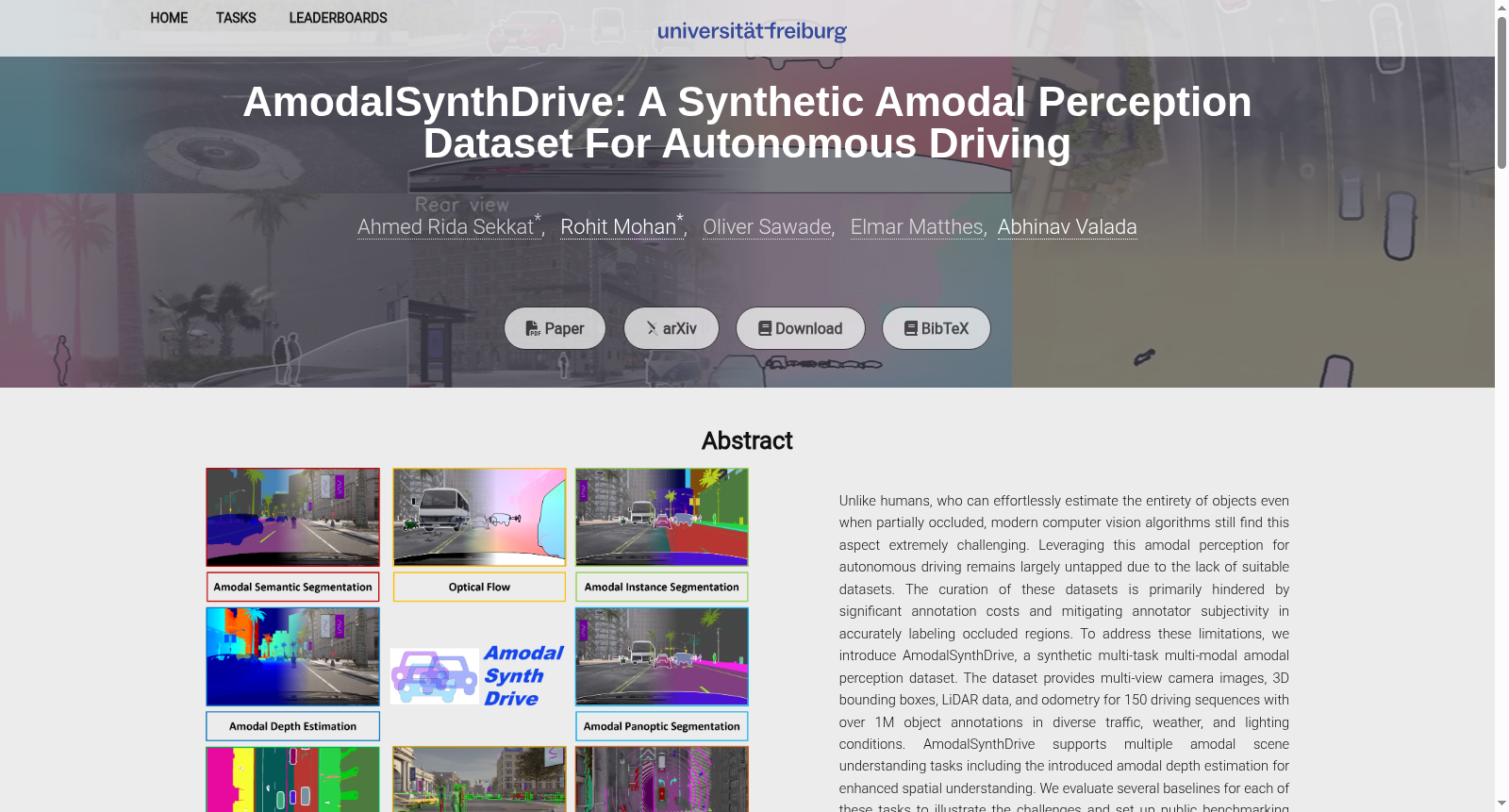
AmodalSynthDrive是一个专为自动驾驶设计的合成模态感知数据集,由IAV GmbH和弗莱堡大学计算机科学系共同创建。该数据集包含150个驾驶序列,涵盖多种交通、天气和光照条件,提供多视角摄像头图像、3D边界框、激光雷达数据和里程计。数据集支持多种模态场景理解任务,包括新引入的模态深度估计,以增强空间理解。AmodalSynthDrive旨在通过提供丰富的视觉线索和精确的标注,推动模态感知领域的研究,特别是在处理复杂环境和提高自动驾驶系统的安全性和效率方面。
AmodalSynthDrive is a synthetic modal perception dataset specifically designed for autonomous driving, jointly created by IAV GmbH and the Department of Computer Science, University of Freiburg. This dataset includes 150 driving sequences covering diverse traffic scenarios, weather and illumination conditions, and provides multi-view camera images, 3D bounding boxes, LiDAR data and odometry. It supports a range of modal scene understanding tasks, including the newly introduced modal depth estimation to enhance spatial understanding. AmodalSynthDrive aims to advance research in the field of modal perception by providing rich visual cues and precise annotations, particularly in addressing complex environments and improving the safety and efficiency of autonomous driving systems.
提供机构:
IAV GmbH, 德国; 计算机科学系, 弗莱堡大学, 德国
创建时间:
2023-09-13
搜集汇总
数据集介绍
构建方式
在自动驾驶领域,全模态感知旨在理解被遮挡物体的完整结构,然而真实世界数据的标注成本高昂且存在主观性偏差。AmodalSynthDrive数据集通过CARLA仿真平台构建,系统化地生成了涵盖多样交通场景、天气与光照条件的150个驾驶序列。构建过程中,利用仿真接口动态切换场景中物体的可见性,逐帧渲染每个物体的完整形态,并同步采集多视角相机图像、激光雷达点云与里程计数据。该方法确保了超过100万个物体标注的精确性,同时提供了包括光流、鸟瞰图在内的丰富视觉线索,为全模态感知研究奠定了可靠的数据基础。
特点
AmodalSynthDrive作为首个面向自动驾驶的大规模合成全模态感知数据集,其核心特点在于多模态与多任务的全面性。数据集包含60,000张高分辨率图像,覆盖18个语义类别,并提供了全模态语义分割、实例分割、全景分割及创新的全模态深度估计任务的标注。区别于现有数据集,它首次引入了全模态深度估计,通过相对遮挡顺序层级化表征场景深度关系,增强了空间理解能力。此外,数据集囊括多种天气条件与光照变化,并包含激光雷达、3D边界框、运动分割等丰富模态,为模型在复杂动态环境中的鲁棒性评估提供了多维度的挑战。
使用方法
该数据集支持全模态感知领域的多项基准任务研究。使用者可基于公开的训练集与验证集开发模型,并通过在线测试服务器评估在全模态分割及深度估计任务上的性能。数据集的结构化划分便于进行模型训练与参数调优,其多模态数据(如图像、激光雷达、光流)可被用于开发单模态或多模态融合方法。对于全模态深度估计任务,研究者需依据相对遮挡顺序预测多层级深度图,并采用加权均方根误差进行量化评估。此外,数据集的合成特性使其可作为预训练资源,通过迁移学习提升模型在真实世界数据集上的泛化能力,推动全模态感知在实际自动驾驶系统中的应用。
背景与挑战
背景概述
在自动驾驶领域,人类具备的完形感知能力——即从部分或遮挡的视觉刺激中感知完整物体的认知过程——对于复杂交通场景的理解至关重要。然而,计算机视觉系统在此方面仍面临显著挑战,主要源于高质量标注数据的匮乏。为填补这一空白,由德国IAV GmbH与弗莱堡大学的研究团队于2023年联合创建的AmodalSynthDrive数据集应运而生。该数据集利用CARLA仿真平台,构建了包含150个驾驶序列、超过100万对象标注的大规模多模态合成数据,涵盖多样化的交通、天气与光照条件。其核心研究问题在于推动自动驾驶系统的完形感知研究,通过提供多视角图像、激光雷达、里程计及完备的完形标注,支持完形语义分割、实例分割、全景分割及创新的完形深度估计等任务,为遮挡推理与空间理解奠定了新的数据基础。
当前挑战
AmodalSynthDrive致力于解决自动驾驶中完形感知的核心挑战:如何准确预测被遮挡物体的完整形态与空间位置。这一领域问题的难点在于遮挡区域的推断本身具有不适定性,且真实传感器无法直接观测被遮挡区域。在数据集构建过程中,研究团队面临两大主要挑战:一是标注成本极高,像素级的遮挡区域人工标注不仅耗时费力,且易受标注者主观判断影响,引入偏差;二是数据生成的复杂性,需通过仿真引擎系统性地切换场景中物体的可见性以提取完整信息,并确保多视角间实例ID的一致性。此外,合成数据与真实场景间的域差异,以及完形深度估计中多层次遮挡关系的建模,均为该数据集应用与算法开发带来了持续的技术挑战。
常用场景
经典使用场景
在自动驾驶的视觉感知研究中,AmodalSynthDrive数据集为处理复杂遮挡场景提供了关键基准。该数据集通过合成技术生成了包含多视角相机图像、激光雷达点云和里程计信息的驾驶序列,并提供了像素级的全模态标注。其最经典的应用场景在于训练和评估全模态感知模型,特别是针对被部分遮挡物体的完整轮廓与深度信息的预测。研究人员利用其丰富的标注和多模态数据,能够系统地探索模型在密集交通、多变天气与光照条件下对遮挡物体的理解能力,从而推动自动驾驶系统在真实复杂环境中的感知鲁棒性。
解决学术问题
AmodalSynthDrive数据集有效解决了自动驾驶领域因遮挡导致的视觉感知不完整这一核心学术难题。传统数据集难以获取被遮挡区域的真实标注,而该合成数据集通过系统性地切换场景中物体的可见性,提供了精确的全模态地面真值,包括被遮挡部分的语义、实例和深度信息。这使研究者能够首次在大规模数据上系统研究全模态语义分割、实例分割、全景分割及深度估计等任务,为建模人类般的完整物体感知能力提供了数据基础,显著降低了标注成本与主观性偏差对研究的影响。
衍生相关工作
AmodalSynthDrive的发布催生并支撑了一系列围绕全模态感知的经典研究工作。在其实验部分,数据集被用于评估和比较如APSNet、PAPS(全模态全景分割)、ASN、BCNet、AISFormer(全模态实例分割)以及amERFNet(全模态语义分割)等前沿方法。更重要的是,该数据集首次定义并引入了“全模态深度估计”这一新任务,并为此提出了ADB-DeepLab、AD-DeepLab等基线模型。这些工作不仅验证了数据集的有效性,也为其在迁移学习中的价值提供了证据,例如在KINS和KITTI-360-APS等真实数据集上通过预训练该数据集提升了模型性能。
以上内容由遇见数据集搜集并总结生成


