MyLalala/data_sample_1000
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/MyLalala/data_sample_1000
下载链接
链接失效反馈官方服务:
资源简介:
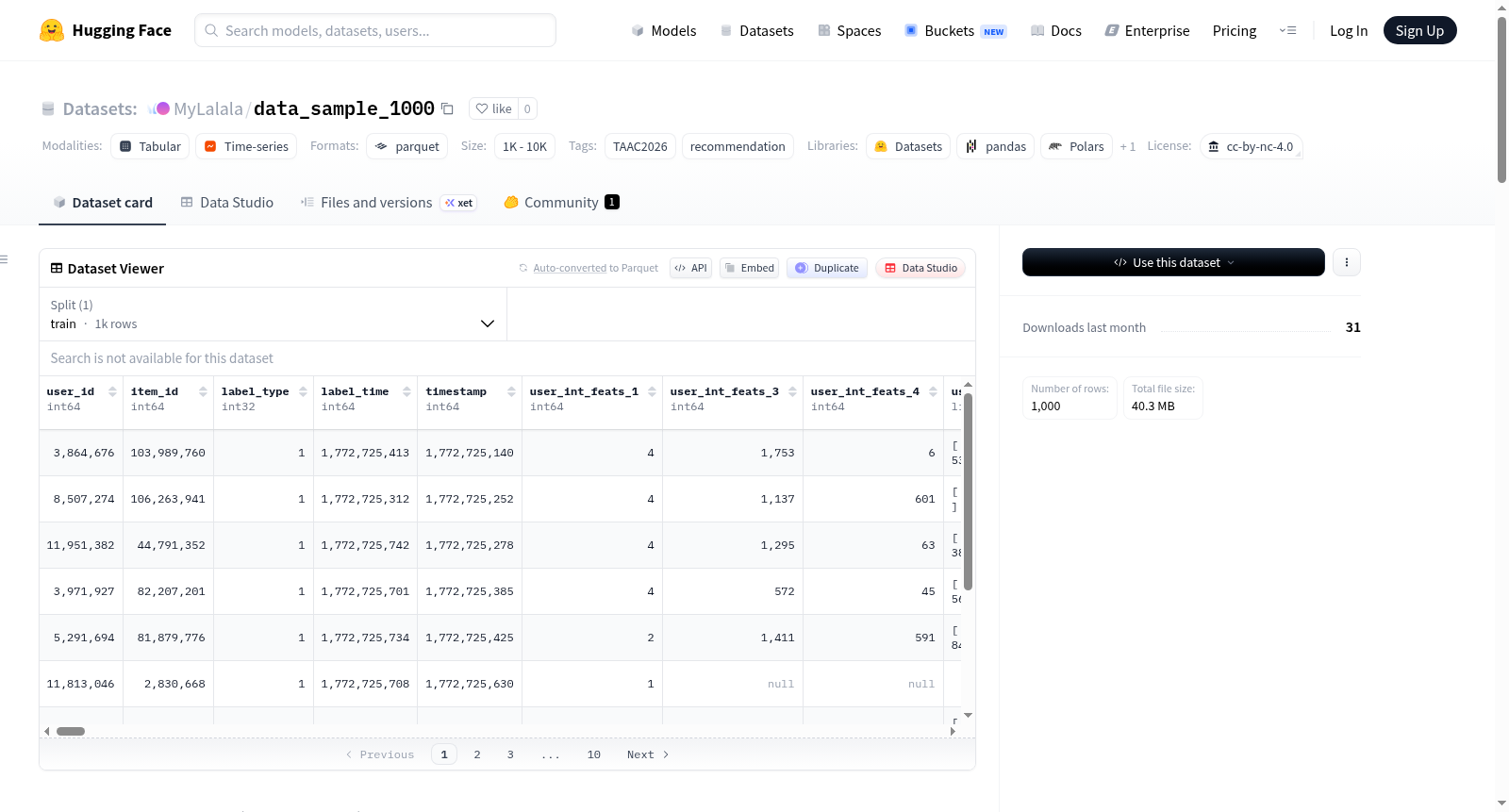
一个包含1000条用户-物品交互记录的样本数据集,用于TAAC2026竞赛。该数据集采用扁平列布局,所有特征都作为单独的顶级列存储,而不是嵌套的结构体或数组。数据集包含120个列,分为6个类别:ID和标签(5列)、用户整数特征(46列)、用户密集特征(10列)、物品整数特征(14列)和领域序列特征(45列)。每个类别都有详细的列描述和数据类型说明。
A sample dataset containing 1000 user-item interaction records for the TAAC2026 competition. This dataset uses a flat column layout — all features are stored as individual top-level columns instead of nested structs/arrays. The dataset contains 120 columns, divided into 6 categories: ID & Label (5 columns), User Int Features (46 columns), User Dense Features (10 columns), Item Int Features (14 columns), and Domain Sequence Features (45 columns). Each category has detailed column descriptions and data type specifications.
提供机构:
MyLalala
搜集汇总
数据集介绍
构建方式
该数据集源自TAAC2026竞赛,精选1000条用户-物品交互记录作为演示样本。数据以Parquet格式存储,采用扁平列布局,所有特征均作为顶层独立列呈现,摒弃了嵌套结构或数组形式。数据集的120个列可划分为六大类别:标识与标签列(5列)、用户整数特征列(46列)、用户稠密特征列(10列)、物品整数特征列(14列)、域序列特征列(45列)。特征命名遵循统一编码规则,如`user_int_feats_{fid}`与`user_dense_feats_{fid}`共享相同fid时,则对齐描述同一实体或信号。
使用方法
使用该数据集时,可通过Python的pandas库直接读取Parquet文件:`pd.read_parquet("demo_1000.parquet")`即可获得包含120列的DataFrame对象。若采用Hugging Face的datasets库,更可通过`load_dataset("TAAC2026/data_sample_1000")`一键加载。值得注意的是,官方已于2026年4月更新版本,建议参与者以最新的扁平列布局Schema为准,避免使用旧版嵌套结构代码。
背景与挑战
背景概述
TAAC2026 Demo Dataset(data_sample_1000)由腾讯算法大赛(TAAC2026)官方于2026年发布,旨在为推荐系统领域的参赛者与研究者提供一个标准化、轻量级的实验样本。该数据集以用户-物品交互记录为核心,涵盖120维特征,包括用户与物品的整数型特征、稠密向量特征,以及跨四个领域的行为序列特征,全面模拟了真实推荐场景中多源异构数据的融合需求。作为TAAC2026竞赛的基线数据,其简洁的扁平列结构便于快速加载与建模,为探索深度推荐模型在多特征融合、序列建模与稀疏交互预测等方向上的表现提供了理想的试验场,对推动推荐系统算法创新与竞赛基准建立具有重要示范意义。
当前挑战
该数据集所解决的领域核心挑战在于推荐系统面临的多模态特征高效融合与跨域序列依赖建模问题,即如何从用户静态属性、物品内容特征与多领域行为序列中提取有效交互信号,以提升稀疏交互下的预测准确率。构建过程中,研发团队需克服三大难点:其一,对来自不同语义空间的46维用户整数特征、10维稠密特征及45维域序列进行对齐与归一化,确保特征间无冲突与信息冗余;其二,将四个行为域的时序序列封装为统一长度的列表特征,同时保留跨域长程依赖;其三,设计扁平化列结构替代传统嵌套格式,在数据易用性与存储效率间取得平衡,使百维特征在39MB内实现高效压缩与快速读取。
常用场景
经典使用场景
在推荐系统研究领域,data_sample_1000数据集作为腾讯TAAC2026竞赛的官方样本数据,其经典使用场景聚焦于用户物品交互行为的建模与预测。该数据集以扁平列式结构组织,整合了用户整数特征、稠密特征、物品属性特征及跨域序列特征,共计120维属性,为研究者提供了一个多模态、多域的行为预测基准。通过这1000条精心采样的交互记录,学者们可以高效地进行推荐算法原型的快速验证,尤其是在深度语义匹配、序列行为挖掘以及多任务学习等前沿方向上开展探索性实验。数据集中包含的4个行为域序列特征,更是为跨域迁移学习和用户长期兴趣演化建模提供了天然的研究素材。
解决学术问题
该数据集在学术层面着力解决了推荐系统中长期存在的冷启动与稀疏性问题。通过提供丰富的用户稠密特征和物品整数特征,研究者得以探索如何在数据稀疏条件下利用特征语义实现准确的行为预测。同时,多域序列特征的引入为攻克用户兴趣的动态漂移和跨域知识迁移这一核心难题提供了标准化测试平台。数据集中标签类型与时间戳的精细设计,使得学者能够深入剖析用户决策的时间依赖性和多类型反馈机制,从而推动因果关系推理在推荐系统中的应用研究。这些问题的突破对于提升推荐系统的泛化能力和鲁棒性具有深远的学术价值。
实际应用
在实际应用层面,data_sample_1000数据集所承载的特征体系与交互模式,能够直接映射至腾讯生态系统中海量用户与内容的匹配场景。基于该数据集训练的推荐模型,可应用于短视频推荐、广告定向投放以及信息流个性化排序等核心业务。数据集中用户稠密特征的连续性设计,使得模型能够捕捉用户偏好的细微变化,进而实现实时动态调整的推荐策略。跨域序列特征的融入,则为构建跨产品线的统一推荐引擎提供了技术路线,有效解决了不同业务场景间的数据孤岛问题,在提升用户体验的同时显著优化了平台商业指标的转化效率。
数据集最近研究
最新研究方向
该数据集作为TAAC2026竞赛的标准化评测样本,聚焦于跨域序列特征与用户-物品交互建模的前沿方向。其120维扁平化特征设计(融合46项用户整数特征、45项跨域行为序列及10项稠密特征)呼应了当前推荐系统领域对多源异构信息融合的迫切需求,尤其在序列推荐与冷启动场景中,通过时间戳对齐的跨域行为序列与密集特征联合建模,为探索用户动态偏好演化提供了结构化基准。该数据集的发布直接关联QQ平台大规模推荐系统的技术迭代热点,其引入的4领域序列特征范式(domain_a/b/c/d_seq)与标签时间戳的精细设计,有望推动基于时间感知的深度学习模型(如双塔序列网络、图神经协同过滤)在工业级多行为预测中的突破。
以上内容由遇见数据集搜集并总结生成


