RUC-NLPIR/GISA
收藏Hugging Face2026-05-02 更新2026-04-05 收录
下载链接:
https://hf-mirror.com/datasets/RUC-NLPIR/GISA
下载链接
链接失效反馈官方服务:
资源简介:
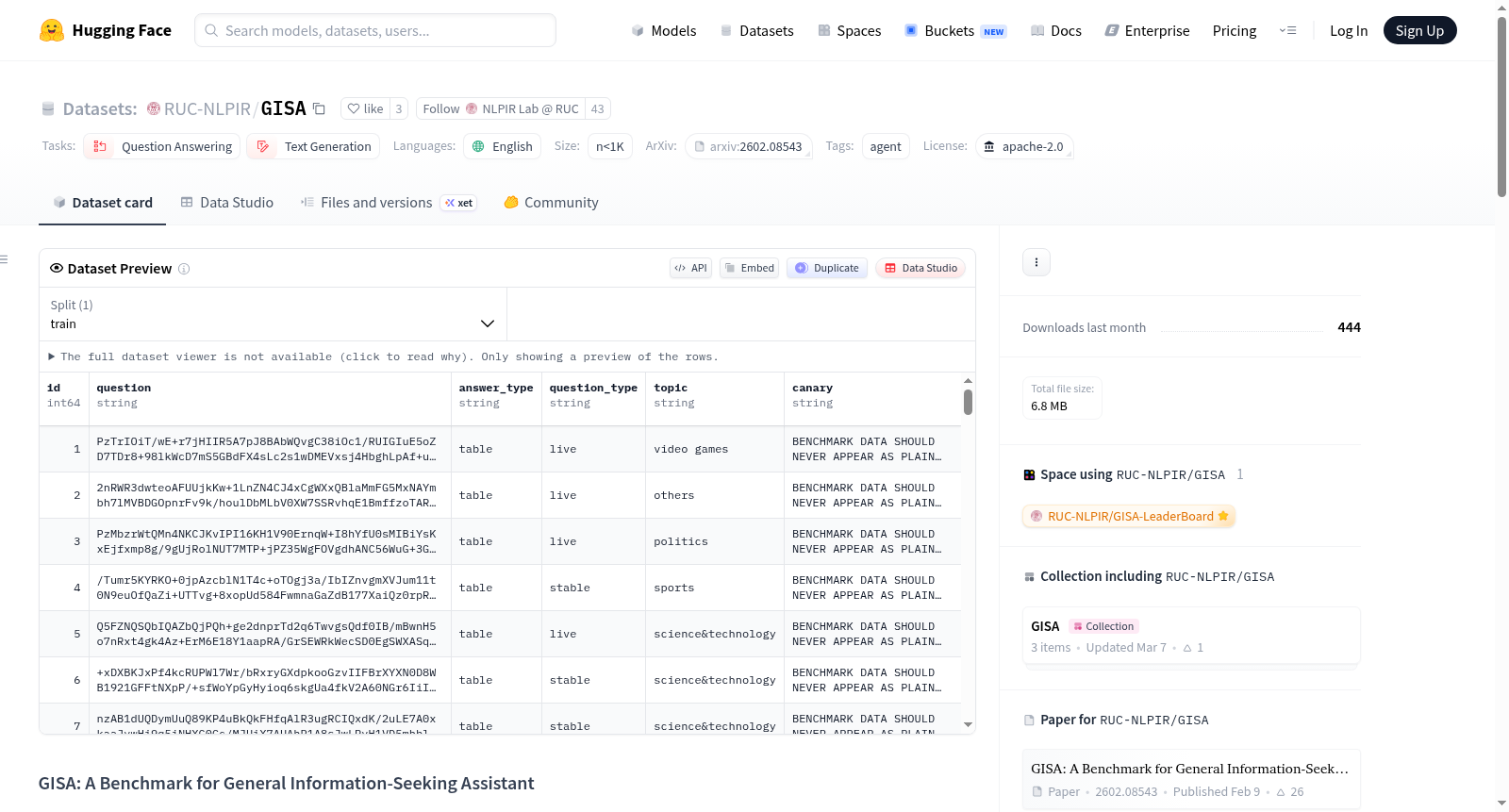
GISA是一个通用信息寻求助手的基准测试集,包含373个反映真实世界信息需求的人工制作查询。数据集包含稳定和动态子集,四种结构化答案格式(项目、集合、列表、表格),以及每个查询的完整人类搜索轨迹。其特点包括:多样化的答案格式与确定性评估、统一的深度和广度搜索能力、动态反静态评估、通过人类轨迹进行过程级监督。数据集用于评估助手的垂直推理和水平信息聚合能力,以及长期探索和总结能力。
GISA is a benchmark for General Information-Seeking Assistants with 373 human-crafted queries that reflect real-world information needs. It includes both stable and live subsets, four structured answer formats (item, set, list, table), and complete human search trajectories for every query. Key features include: diverse answer formats with deterministic evaluation, unified deep + wide search capabilities, dynamic, anti-static evaluation, and process-level supervision via human trajectories. The benchmark evaluates both vertical reasoning and horizontal information aggregation across sources, as well as long-horizon exploration and summarization capabilities.
提供机构:
RUC-NLPIR
搜集汇总
数据集介绍
构建方式
GISA(General Information-Seeking Assistant)基准数据集由来自中国人民大学与阿里巴巴团队的研究者共同构建,旨在评估信息检索型语言助手的综合能力。该数据集包含373条人工撰写的查询,每条查询均经过加密处理以保障评测的公平性,并配备完整的搜索轨迹与结构化答案(项目、集合、列表、表格四种格式)。数据构建过程中,标注人员模拟真实用户的信息需求,执行深度与广度结合的搜索行为,记录包括搜索查询、结果点击与浏览路径在内的完整过程信息,从而为过程奖励建模与模仿学习提供高质量的黄金参考。
特点
GISA数据集的核心特点在于其结构化答案格式与确定性评估机制,采用严格匹配指标取代主观的LLM评判,兼顾任务多样性与评测的可复现性。数据集划分为稳定子集与动态子集,后者定期更新以抵御模型记忆效应,确保持续的挑战性。同时,所有查询均附带完整的人类搜索轨迹,提供过程级监督信号,既可用于验证任务的可解性,也为长程探索与跨源信息聚合能力的评估提供了统一的基准平台。
使用方法
使用GISA数据集时,首先需从加密的JSONL文件中读取问题,利用每行提供的canary字段作为密码,通过SHA256派生的密钥进行XOR解密以还原明文查询。评估过程涉及对模型生成的答案与对应CSV文件中的标准答案进行格式匹配,支持item、set、list、table四种类型的严格度量。此外,trace目录下的JSON文件记录了人类标注者的搜索路径,可用于监督微调或作为过程奖励模型的训练数据。详细的评测脚本与排行榜可参考项目GitHub仓库与Hugging Face Spaces页面。
背景与挑战
背景概述
GISA(General Information-Seeking Assistant Benchmark)是由中国人民大学NLPIR实验室联合多家机构于2026年发布的一项创新性基准测试,核心研究人员包括Yutao Zhu、Zhicheng Dou等。该数据集聚焦于通用信息搜寻助手的性能评估,通过373条精心设计的人工查询,覆盖电视电影、科技、艺术、历史等十大主题,旨在解决大语言模型在多源信息聚合与长程推理任务中缺乏标准化评估的问题。GISA的发布不仅填补了现有基准如HotpotQA或FEVER在结构化答案匹配与动态抗静态评估方面的空白,还通过提供完整的人类搜索轨迹,为过程奖励建模和模仿学习提供了黄金参考,显著推动了信息检索与对话系统的交叉研究领域发展。
当前挑战
GISA所解决的领域挑战主要包括三个方面:一是现有信息搜寻助手评估多依赖主观的LLM评判或单一答案格式,缺乏对结构化输出(如集合、列表、表格)的确定性度量,GISA通过四种严格的匹配指标实现了可复现的评估;二是传统基准无法应对动态变化的信息需求,GISA引入“稳定”与“实时”子集并周期性更新实时查询,有效抵抗记忆化测试风险;三是构建过程中,团队需确保373个查询的真实性与多样性,为此组织了大规模人工标注,记录每次搜索的完整行为轨迹(包括查询、点击、结果),并实施了加密存储策略以保护隐私,同时维持了任务的可解性验证,这对标注一致性与安全问题提出了高要求。
常用场景
经典使用场景
在信息检索与智能助手领域,GISA基准测试被广泛用于评估通用信息寻求助手的综合性能。其设计了373条经过人工精心构建的查询,涵盖从稳定主题到动态更新子集的不同类型,并对应四种结构化答案格式(项、集合、列表、表格)。研究者可借助该数据集对模型在垂直推理与水平信息聚合方面的能力进行统一评测,尤其关注长程探索和跨源摘要等复杂任务场景下的表现。
实际应用
在实际应用中,GISA深度赋能了下一代智能搜索引擎与对话式信息助手的研发落地。企业级助理系统可利用该基准测试其多轮交互能力,涵盖从单一实体定位(如查询某部电影导演)到复杂数据表格生成(如对比多款手机参数)的多元任务。此外,实时子集的持续更新机制使得模型能够适应动态网络环境,显著提升了搜索引擎在新闻事件追踪、商品价格波动等快变场景下的实用性与时效性。
衍生相关工作
基于GISA的公开基准与完整轨迹数据,学术界已衍生出多项经典研究工作。例如,研究者利用其结构化答案格式开发了基于强化学习的表格生成增强算法;另有多篇论文借鉴其人类搜索轨迹构建了精细化的过程奖励模型,用于指导大语言模型的多步推理。此外,GISA的静态-动态子集划分策略被后续多个长尾信息检索基准广泛采纳,成为评估模型泛化能力与时效感知的标准范式之一。
以上内容由遇见数据集搜集并总结生成


