ContextualBench
收藏Hugging Face2024-12-06 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/ToughStone/ContextualBench
下载链接
链接失效反馈官方服务:
资源简介:
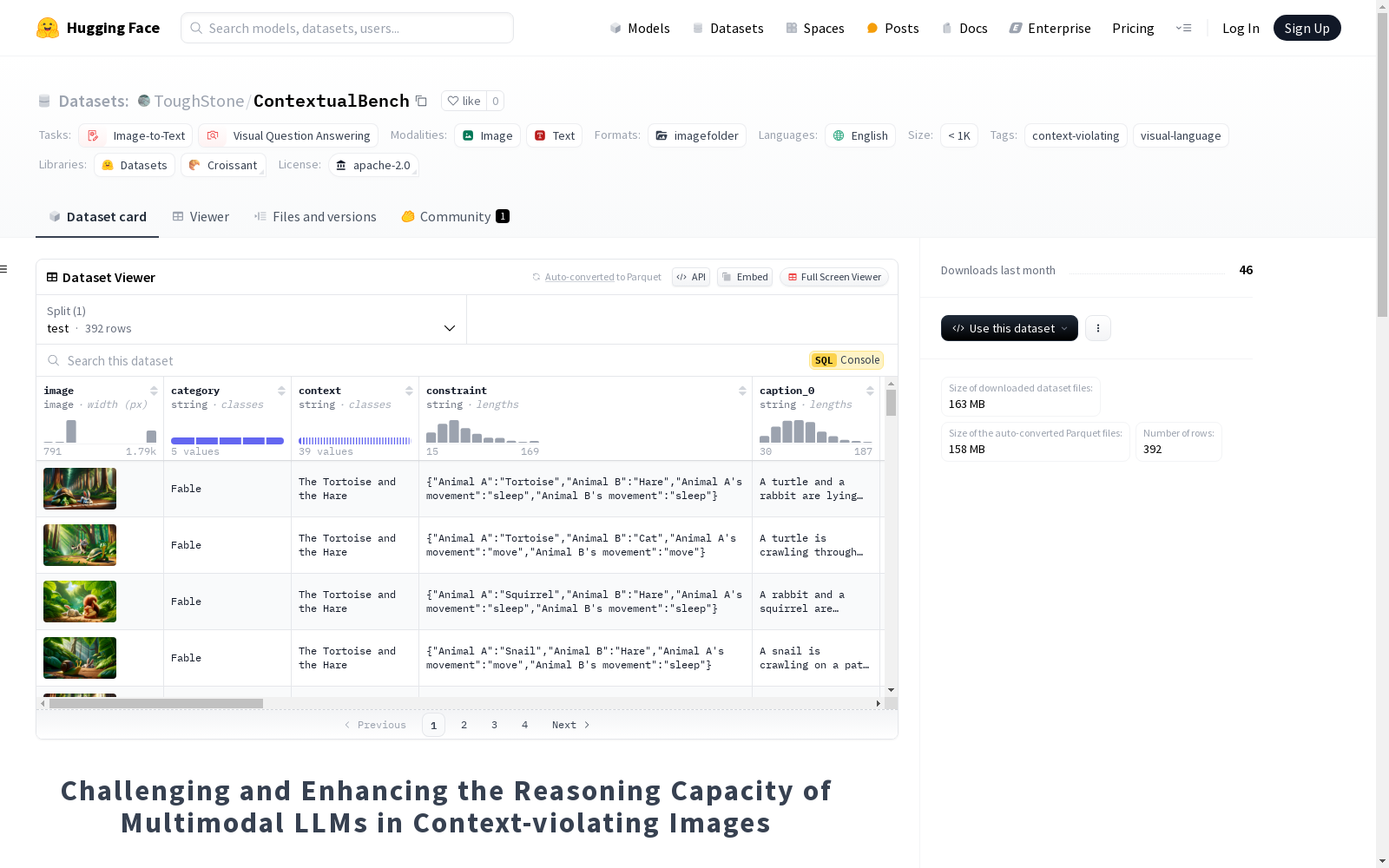
ContextualBench数据集包含72个上下文实例,每个实例包含7张上下文一致的图像和7张上下文违反的图像。数据集设计了4个视觉推理任务,并收集了人工标注。图像生成过程包括从外部数据库收集上下文实例,并使用文本到图像模型生成图像,确保图像符合给定约束、无视觉错觉且无歧义和潜在冒犯性。任务设计包括视觉问答、图像描述、图像识别和图像解释。图像标注方面,图像描述、图像识别和图像解释任务收集了5个不同人的标注,视觉问答任务基于图像描述生成Q-A对。数据集主要用于测试,禁止商业用途作为训练集使用。
创建时间:
2024-12-05
原始信息汇总
ContextualBench 数据集概述
基本信息
- 许可证: Apache 2.0
- 任务类别:
- 图像到文本
- 视觉问答
- 语言: 英语
- 标签:
- 上下文违反
- 视觉语言
- 数据集名称: ContextualBench
数据集描述
- 内容: 包含6个类别 × 12个实例 = 72个上下文实例,每个实例包含7张上下文一致的图像和7张上下文违反的图像。
- 任务设计: 设计了4个视觉推理任务,并收集了人工标注。
数据集构建
图像生成
- 来源: 从外部数据库收集上下文实例,并将其格式化为键值对。
- 生成过程: 使用文本到图像模型生成图像,确保图像符合给定约束、无视觉错觉、无歧义和潜在冒犯性。
任务设计
- 任务类型:
- 视觉问答
- 图像描述
- 图像识别
- 图像解释(仅适用于上下文违反的图像)
图像标注
- 标注方式: 对于图像描述、图像识别和图像解释,收集了5个不同人的标注。对于视觉问答,基于图像描述生成Q-A对。
许可证信息
- 用途: 主要用作测试集。
- 商业用途: 允许作为测试集使用,禁止用作训练集。
- 图像权利: 所有图像的版权由ContextualBench作者保留。
引用信息
plaintext @article{hongxi2024challenging, title={Challenging and Enhancing the Reasoning Capacity of Multimodal LLMs in Context-violating Images}, author={}, journal={}, year={2024} }
搜集汇总
数据集介绍
构建方式
ContextualBench数据集的构建过程严谨而系统,首先从外部数据库中收集上下文实例,并将其形式化为键值对。随后,通过对部分键值对进行编辑,生成上下文违反的图像。图像生成过程严格遵循三个条件:符合给定约束、无视觉错觉、避免歧义和潜在冒犯性。此外,数据集设计了四种视觉推理任务,并收集了人工标注,确保数据集的质量和多样性。
使用方法
ContextualBench数据集主要用于测试多模态大模型的推理能力,特别是在处理上下文违反图像时的表现。用户可以通过访问数据集的官方网站或GitHub代码库获取数据集,并使用提供的视觉推理任务进行模型评估。值得注意的是,该数据集仅限于测试用途,禁止用于商业训练目的,且所有图像的版权均归数据集作者所有。
背景与挑战
背景概述
ContextualBench数据集由北京理工大学的Hongxi Li、Yuyang Chen、Yayun Qi和Xinxiao Wu等研究人员于2024年创建,旨在挑战和增强多模态大语言模型(LLMs)在处理上下文违反图像时的推理能力。该数据集包含了72个上下文实例,每个实例包含7张上下文一致的图像和7张上下文违反的图像,设计了4种视觉推理任务,并收集了人工标注。ContextualBench的推出为多模态模型在复杂视觉语言任务中的表现提供了新的测试基准,尤其在处理上下文违反图像时,模型的推理能力得到了显著提升。
当前挑战
ContextualBench数据集在构建过程中面临多项挑战。首先,生成符合特定约束且无视觉错觉的图像是一个复杂的过程,需确保图像的清晰度和无歧义性。其次,设计多样化的视觉推理任务,如视觉问答、图像描述和图像识别,要求任务设计既能覆盖广泛的应用场景,又能有效评估模型的推理能力。此外,收集高质量的人工标注,确保标注的一致性和准确性,也是数据集构建中的重要挑战。最后,如何在商业应用中合理使用该数据集,避免将其作为训练集使用,也是需要解决的实际问题。
常用场景
经典使用场景
ContextualBench 数据集的经典使用场景主要集中在多模态大语言模型(Multimodal LLMs)的推理能力评估上。该数据集通过提供包含上下文一致和上下文违反的图像,设计了视觉问答、图像描述、图像识别和图像解释等任务,旨在挑战和增强模型在处理复杂视觉信息时的推理能力。
解决学术问题
ContextualBench 数据集解决了多模态大语言模型在处理上下文违反图像时的推理能力不足问题。通过引入上下文违反的图像和相应的视觉推理任务,该数据集为研究者提供了一个标准化的测试平台,有助于评估和提升模型在复杂视觉场景中的表现,推动多模态学习的研究进展。
实际应用
在实际应用中,ContextualBench 数据集可用于开发和测试智能视觉系统,如自动驾驶中的场景理解、医疗影像分析中的异常检测等。通过评估模型在上下文违反图像上的表现,可以提高系统在复杂和异常情况下的鲁棒性和可靠性,从而提升整体应用效果。
数据集最近研究
最新研究方向
在多模态大语言模型(Multimodal LLMs)领域,ContextualBench数据集的最新研究方向聚焦于提升模型在处理上下文违反图像时的推理能力。该数据集通过设计多种视觉推理任务,如视觉问答、图像描述和图像识别,挑战模型在复杂场景下的表现。特别是针对上下文违反图像的解释任务,研究者们旨在增强模型对异常情况的识别与理解能力,从而推动多模态模型在实际应用中的鲁棒性和适应性。这一研究方向不仅有助于提升模型的推理能力,还为未来在自动驾驶、医疗诊断等领域的应用提供了重要的技术支持。
以上内容由遇见数据集搜集并总结生成


