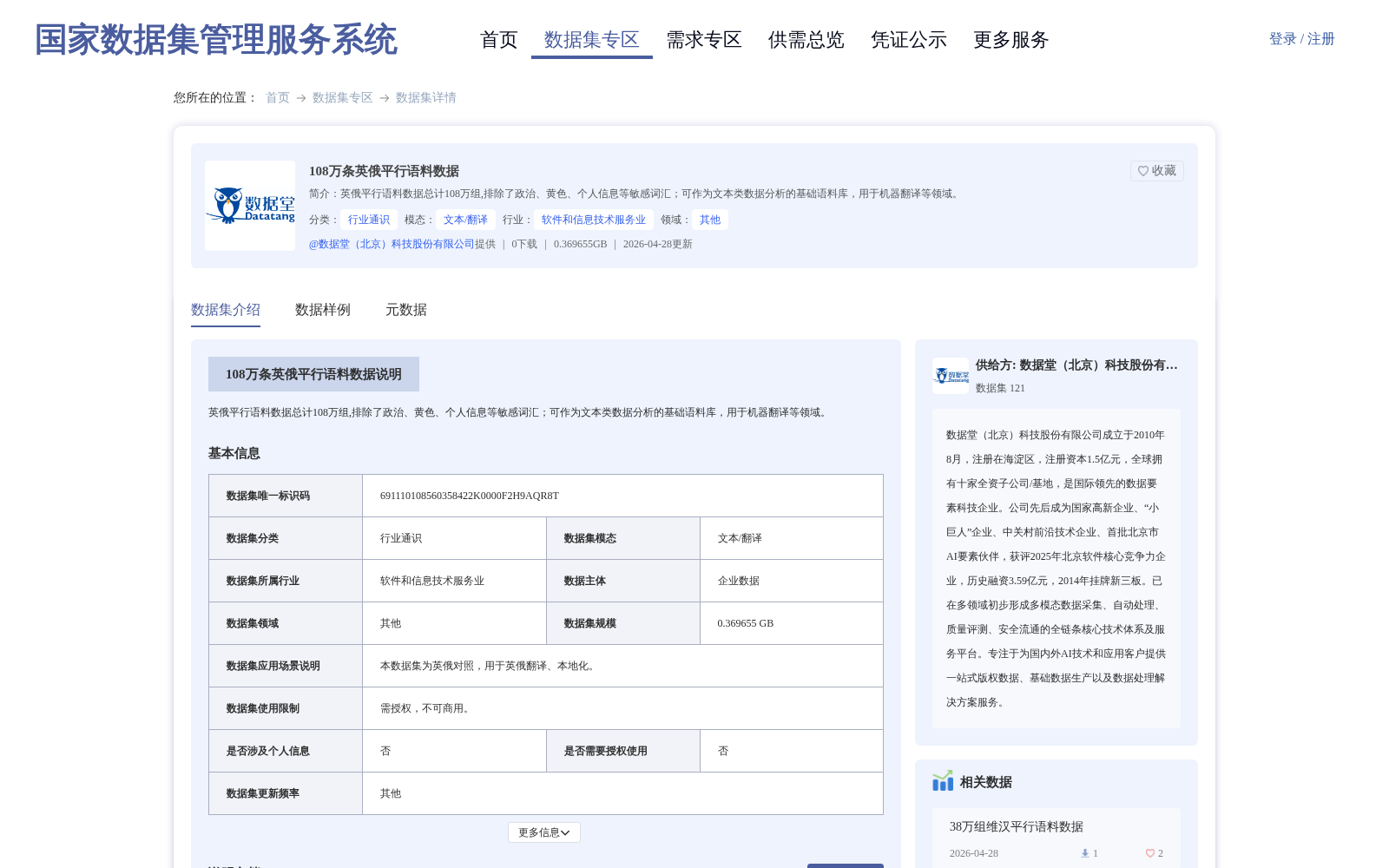
108万条英俄平行语料数据
收藏国家数据集管理服务平台2026-04-28 更新2026-04-29 收录
下载链接:
https://www.ndsms.cn/dataRetrieval/datasetDetail/?id=14e059f0c5c10efb30a6b86e8e182175
下载链接
链接失效反馈官方服务:
资源简介:
英俄平行语料数据总计108万组,排除了政治、黄色、个人信息等敏感词汇;可作为文本类数据分析的基础语料库,用于机器翻译等领域。
The English-Russian parallel corpus totals 1.08 million pairs, with sensitive content including political, pornographic, and personal information excluded. It can serve as a foundational corpus for textual data analysis and be applied in fields such as machine translation.
提供机构:
数据堂(北京)科技股份有限公司
创建时间:
2026-04-28
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集包含108万组英俄平行语料,已过滤敏感信息,适用于机器翻译等文本分析任务。它专门服务于英俄翻译与本地化应用场景,属于文本/翻译模态的数据资源。
以上内容由遇见数据集搜集并总结生成


