nonverbalspeech38k
收藏Hugging Face2025-08-08 更新2025-08-09 收录
下载链接:
https://huggingface.co/datasets/nonverbalspeech/nonverbalspeech38k
下载链接
链接失效反馈官方服务:
资源简介:
NVS-38K数据集是从野外的音频来源,如电影、动画片和有声读物中构建的,包含总共38,718个样本,大约131小时,标注有10个非言语类别。该数据集旨在支持非言语语音生成和非言语语音理解任务。
创建时间:
2025-08-06
原始信息汇总
NonVerbalSpeech-38K 数据集概述
基本信息
- 许可证: CC BY-NC 4.0
- 任务类别: 文本转语音、自动语音识别
- 语言: 中文 (zh)、英文 (en)
- 标签: 非语言、副语言、表达性
- 数据规模: 10K < n < 100K
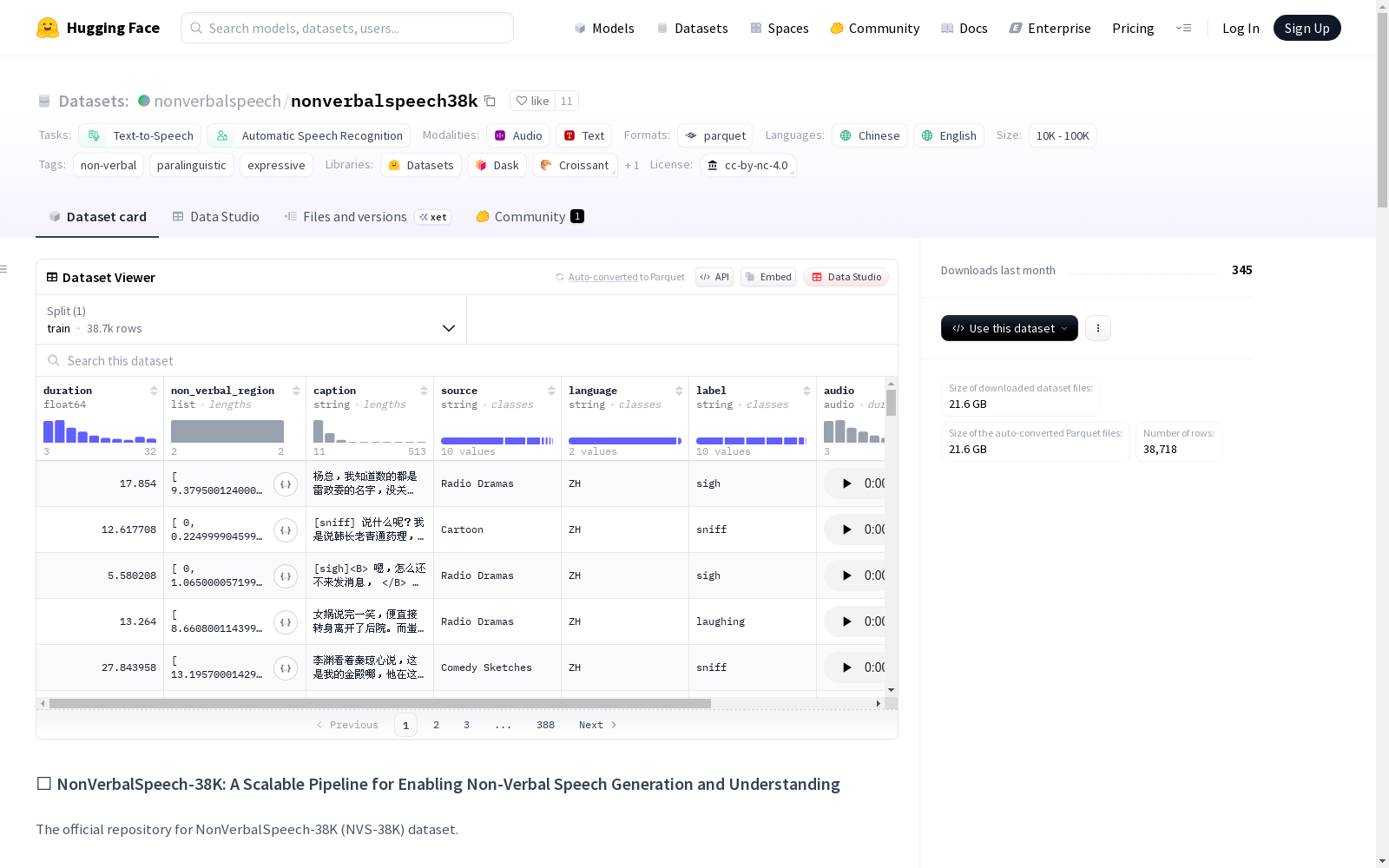
数据集结构
- 配置名称: default
- 数据文件:
- 训练集: data/train-*
- 特征:
- duration (float64): 音频时长
- non_verbal_region (list: float64): 非语言区域时间戳
- caption (string): 音频描述文本
- source (string): 数据来源
- language (string): 语言
- label (string): 非语言标签
- audio (audio): 音频数据
- 训练集统计:
- 样本数: 38,718
- 总字节数: 22,585,812,712.942
- 下载大小: 21,614,995,156
数据集内容
- 总样本数: 38,718
- 总时长: 约131小时
- 非语言类别: 10类
- [snore], [throatclearing], [crying], [breath], [sniff], [laughing], [coughing], [gasp], [yawn], [sigh]
- 特殊标签: <B> 和 </B> 表示非语言表达与口语重叠
数据来源分布
| 来源 | 原始时长 (小时) | NVS-38K 样本数 |
|---|---|---|
| Radio Dramas | 17,400 | 21,668 |
| Comedy Sketches | 7,200 | 7,273 |
| Cartoon | 3,600 | 5,019 |
| Variety Shows | 1,400 | 1,217 |
| Short Plays | 1,200 | 809 |
| Speeches | 1,079 | 158 |
| Documentaries | 600 | 105 |
| Movies | 500 | 1,090 |
| Audiobooks | 263 | 1,375 |
| Toy Unboxing | 9 | 4 |
使用示例
python from datasets import load_dataset ds = load_dataset("nonverbalspeech/nonverbalspeech38k")
注意事项
- 数据集不拥有音频文件的版权,仅限非商业研究使用。
- 当前版本可能存在音频与字幕的轻微对齐问题。
- 非语言表达已扩展到子句级别以减少对齐问题。
参考
- 引用文献: Coming Soon...
搜集汇总
数据集介绍
构建方式
NonVerbalSpeech-38K数据集通过从电影、卡通和有声读物等真实音频源中采集数据构建而成,涵盖了38,718个样本,总时长约131小时。数据标注过程包括10种非语言类别的精细标记,如打鼾、清喉、哭泣等,并采用特殊标签处理非语言表达与口语重叠的情况。数据来源多样,包括广播剧、喜剧小品、卡通等多种类型,确保了数据的广泛性和代表性。
使用方法
使用NonVerbalSpeech-38K数据集时,可通过Hugging Face的`datasets`库直接加载,支持快速访问音频文件及其对应的标注信息。数据集中每个样本包含音频、持续时间、非语言区域时间戳、文本描述及类别标签,便于进行非语言语音生成或识别任务的模型训练。用户需注意数据仅限非商业研究使用,并遵守CC BY-NC 4.0许可协议。
背景与挑战
背景概述
NonVerbalSpeech-38K(NVS-38K)数据集是由研究人员从电影、卡通和有声读物等真实音频源中构建的大规模非言语语音数据集,涵盖约131小时的38,718个样本,并标注了10种非言语类别。该数据集旨在支持非言语语音生成和理解任务,为语音合成和自动语音识别领域提供了丰富的研究资源。其多源数据构成和精细标注体系,显著提升了非言语语音研究的深度和广度,对推动人机交互和情感计算等领域的发展具有重要意义。
当前挑战
NVS-38K数据集面临的主要挑战包括两方面:在领域问题层面,非言语语音的多样性和复杂性使得准确分类和生成面临较大难度,尤其是重叠言语与非言语区域的精确标注;在构建过程中,基于自动语音识别(ASR)的时间戳对齐存在轻微偏差,影响了音频与文本标注的同步性。尽管通过子句级扩展策略尝试改善对齐问题,但效果有限,未来仍需进一步优化标注精度和时间戳对齐技术。
常用场景
经典使用场景
在语音合成与识别领域,NonVerbalSpeech-38K数据集为研究者提供了丰富的非语言语音样本,涵盖10种非语言类别,如叹息、咳嗽、笑声等。这些样本广泛应用于非语言语音生成任务,例如在语音合成系统中模拟真实对话中的非语言表达,增强合成语音的自然度和情感表现力。此外,该数据集还支持非语言语音理解任务,帮助研究者开发更精准的非语言语音识别模型。
解决学术问题
NonVerbalSpeech-38K数据集解决了语音处理领域中对非语言表达系统性研究的缺失问题。通过提供大量标注的非语言语音样本,该数据集为研究者提供了分析非语言表达与语言内容交互的基础,推动了情感计算、语音合成和语音识别等领域的发展。其多语言特性(中文和英文)进一步扩展了跨语言非语言表达研究的可能性。
实际应用
在实际应用中,NonVerbalSpeech-38K数据集被用于开发更具表现力的语音助手和虚拟角色。例如,在影视配音和游戏角色语音生成中,利用该数据集可以模拟更真实的非语言表达,提升用户体验。此外,该数据集还可用于医疗领域,帮助开发基于非语言语音的情感识别工具,辅助心理健康诊断和干预。
数据集最近研究
最新研究方向
在语音合成与识别领域,非言语表达的研究正逐渐成为热点。NonVerbalSpeech-38K数据集以其丰富的非言语标注和多样化的数据来源,为研究者提供了探索非言语表达生成与理解的宝贵资源。当前,该数据集的前沿研究方向主要集中在非言语表达的多模态融合、跨语言非言语表达的迁移学习,以及非言语表达在情感计算中的应用。特别是在情感识别和人机交互领域,非言语表达的研究为提升语音合成系统的自然度和情感表达能力提供了新的思路。此外,该数据集还被广泛应用于语音合成系统的评测基准,推动了非言语表达生成技术的发展。随着多模态交互技术的兴起,NonVerbalSpeech-38K数据集在跨模态对齐和非言语表达生成方面的潜力正逐渐被挖掘,为未来智能语音系统的研发奠定了重要基础。
以上内容由遇见数据集搜集并总结生成


