CFSDD
收藏Hugging Face2026-04-07 更新2026-04-08 收录
下载链接:
https://huggingface.co/datasets/Izzyzlin/CFSDD
下载链接
链接失效反馈官方服务:
资源简介:
CFSDD是一个针对电信诈骗场景的中文语音深度伪造基准数据集。与传统的语音深度伪造数据集不同,CFSDD从风险导向的角度设计,同时考虑声学真实性和语义意图。该数据集明确区分真实的良性语音和伪造的欺诈性语音,适用于研究真实电信诈骗条件下的语音深度伪造检测。数据集包含两类样本:真实的良性语音(来自MagicData-RAMC)和合成的欺诈性语音(文本来自TeleAntiFraud-28k)。数据集总时长为766小时,包含394,908条语音,663名说话人,平均每条语音时长为6.98秒,涉及10种TTS系统。数据集分为训练集、开发集和测试集,其中测试集进一步分为干净测试数据、噪声添加、噪声抑制和编解码处理四个子集,以模拟真实通话条件。
创建时间:
2026-04-01
原始信息汇总
CFSDD数据集概述
数据集基本信息
- 数据集名称: CFSDD
- 许可证: Apache-2.0
- 主要语言: 中文 (zh)
- 标签: audio, text, speech-deepfake-detection, telecom-fraud
- 数据规模: 100K < n < 1M
数据集简介
CFSDD是一个面向电信诈骗场景的中文语音深度伪造检测基准数据集。与主要关注声学真实性的传统语音深度伪造数据集不同,CFSDD从风险导向的视角设计,同时考虑了声学真实性和语义意图。该基准明确区分了真实的良性语音和伪造的欺诈性语音,适用于研究真实电信诈骗条件下的语音深度伪造检测。
数据集包含两类样本:
- 真实良性语音: 具有良性语义内容的真实语音,源自MagicData-RAMC。
- 伪造欺诈语音: 具有欺诈内容的合成语音,其文本转录源自TeleAntiFraud-28k。
数据结构与组织
数据划分
数据集组织为三个划分:
train: 训练集dev: 开发集test: 测试集
test集聚合了四个评估子集:
test_clean: 干净测试数据test_noise: 噪声添加处理后的输出test_ns: 噪声抑制处理后的输出test_codec: 编解码处理后的输出
此组织遵循论文中描述的面向扰动的评估协议。干净的测试数据通过一个由噪声添加、噪声抑制和编解码处理组成的顺序流程进行扩展,以更好地逼近真实的语音通话条件。
模拟真实通话条件
为模拟真实通话条件,面向扰动的测试子集使用了以下外部资源:
噪声添加: Audioset, Freesound, RIR噪声抑制: DeepFilterNet编解码处理: Opus
数据集特征
数据文件格式
- 格式: Parquet
- 配置文件:
main
特征字段
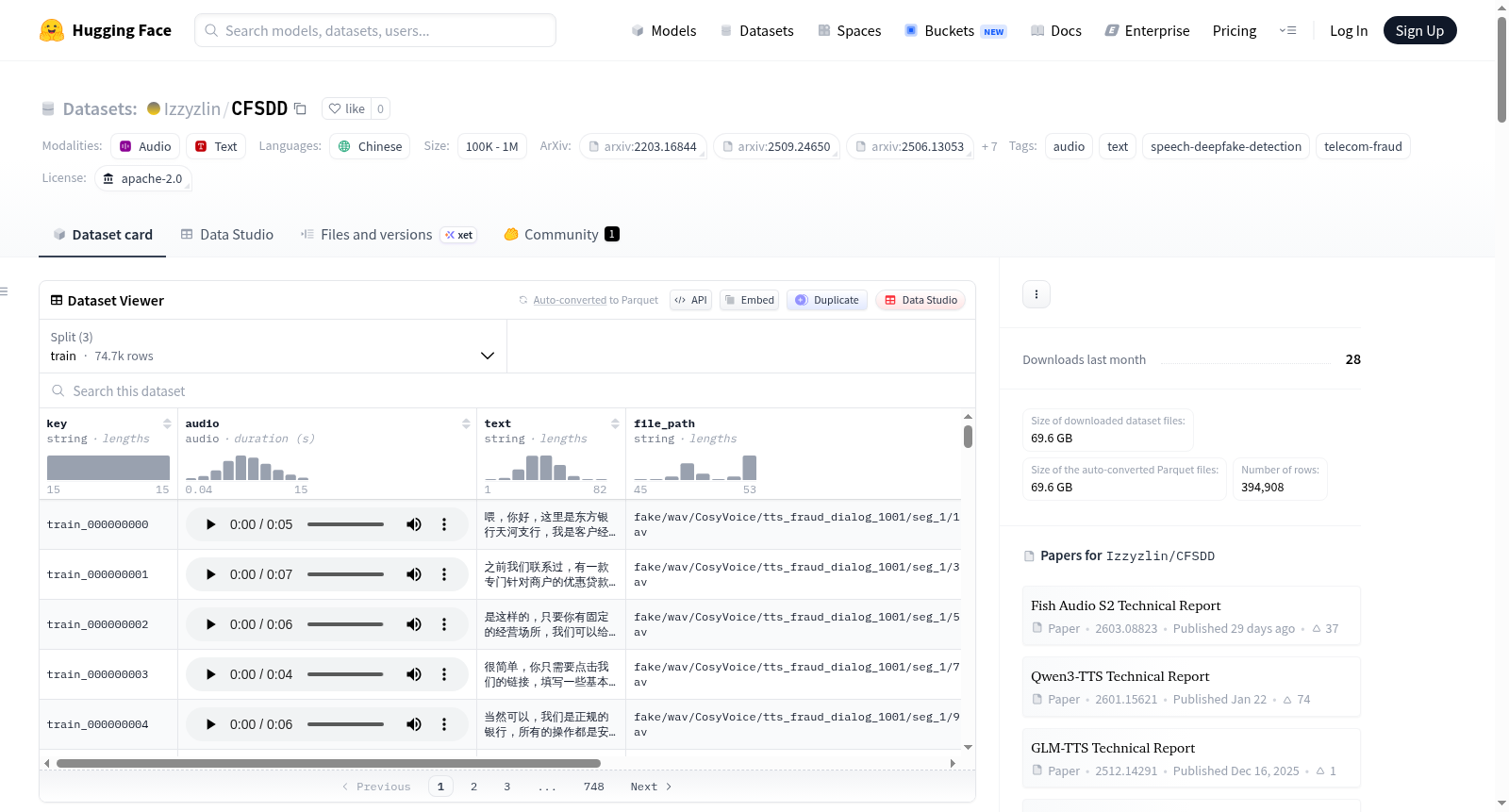
key: 字符串类型,样本标识。audio: 音频类型,音频数据。text: 字符串类型,文本转录。file_path: 字符串类型,文件路径。speaker: 字符串类型,说话人标识。gender: 字符串类型,性别。method: 字符串类型,生成方法。label: 字符串类型,样本标签。
数据集统计信息
CFSDD总共包含766小时的语音,394,908条话语,663名说话人,平均话语时长为6.98秒,涉及10个TTS系统。训练集、开发集和测试集中的说话人严格不相交。有5个TTS系统出现在所有划分中,其余5个保留在测试集中,用于评估对未知生成器的泛化能力。
各划分详细统计
| 划分 | 时长 (小时) | 话语数量 | 说话人数量 | 系统数量 |
|---|---|---|---|---|
| Train | 139 | 74,737 | 300 | 5 |
| Dev | 49 | 25,893 | 100 | 5 |
| Test | 578 | 294,278 | 263 | 10 |
| Total | 766 | 394,908 | 663 | 10 |
分布信息
- 类别、性别和测试条件的分布情况。
- TTS系统和话语时长的分布情况。
使用示例
python from datasets import load_dataset ds = load_dataset("Izzyzlin/CFSDD", "main") train_ds = ds["train"] dev_ds = ds["dev"] test_ds = ds["test"]
致谢与引用
CFSDD建立在有价值的公共资源之上。如果使用此数据集,请考虑引用原始数据源以及用于构建伪造欺诈语音的TTS系统。
数据源
- MagicData-RAMC
- TeleAntiFraud-28k
TTS系统
- F5-TTS
- VoxCPM
- ZipVoice
- IndexTTS2
- Spark-TTS
- CosyVoice 3
- GLM-TTS
- Qwen3-TTS
- FireRedTTS-2
- Fish Audio S2
搜集汇总
数据集介绍
构建方式
在电信诈骗检测领域,构建高质量的数据集对于推动语音深度伪造识别技术至关重要。CFSDD数据集的构建采用了风险导向的设计理念,其真实良性语音样本源自MagicData-RAMC开源对话语料,确保了语音的自然性与语义的正当性;而伪造欺诈语音则通过整合TeleAntiFraud-28k中的欺诈性文本转录,并利用包括F5-TTS、VoxCPM在内的十种前沿文本转语音系统合成生成。这种构建方式不仅关注声学层面的真实性,更将语义意图纳入统一考量,从而在数据源头实现了对现实诈骗场景中声纹伪造与恶意内容结合的综合模拟。
特点
该数据集的核心特点在于其面向真实电信诈骗场景的评估体系与丰富的扰动测试子集。CFSDD总计包含766小时语音,近40万条话语,严格划分了训练集、开发集和测试集,且说话人与部分TTS系统在不同集合间完全隔离,以评估模型对未知说话人与合成器的泛化能力。尤为突出的是,其测试集被精心组织为清洁测试数据及经过噪声添加、噪声抑制与编解码处理的扰动子集,这些扰动模拟了实际通话中的信道变异与环境干扰,为模型在复杂现实条件下的鲁棒性评估提供了坚实基础。
使用方法
研究人员可通过Hugging Face的datasets库便捷加载CFSDD数据集进行模型开发与评估。使用`load_dataset`函数指定数据集名称与配置后,即可访问训练、开发和测试分割。测试分割中包含了以`key`字段区分的多个扰动子集,用户可通过过滤操作分别提取`test_clean`、`test_noise`、`test_ns`和`test_codec`数据,以系统性地评估模型在不同失真条件下的性能。这种结构化的访问方式支持端到端的实验流程,便于在贴近实际的语音通信环境中进行深度伪造检测算法的训练与全面验证。
背景与挑战
背景概述
随着深度伪造技术的迅猛发展,语音合成系统在电信诈骗等恶意场景中的滥用已成为严峻的社会与安全挑战。CFSDD数据集应运而生,作为一个面向电信诈骗场景的中文语音深度伪造检测基准,其设计超越了传统仅关注声学真实性的范式,转而采用风险导向的视角,同时考量声学真实性与语义意图。该数据集由研究团队于近年构建,核心研究问题在于如何有效区分真实良性语音与伪造欺诈性语音,从而推动在真实通话环境下语音深度伪造检测技术的发展。通过整合MagicData-RAMC的真实语音与TeleAntiFraud-28k衍生的欺诈性文本合成语音,CFSDD为学术界提供了大规模、高质量且贴近实际风险的评估资源,显著提升了该领域研究的实用性与针对性。
当前挑战
在语音深度伪造检测领域,核心挑战在于模型需同时应对声学伪造痕迹的识别与语义欺诈意图的判别,而传统数据集往往仅侧重于前者。CFSDD所针对的电信诈骗检测问题,要求系统在复杂真实环境中保持鲁棒性,例如对抗背景噪声、编码压缩及降噪处理等常见通讯干扰。在数据集构建过程中,研究者面临多重挑战:其一,需确保语音样本在说话人、性别及合成系统上的严格划分,以评估模型对未见过的合成器的泛化能力;其二,模拟真实通话条件需引入多源噪声、降噪算法及编解码处理,构建扰动导向的测试子集,这一流程涉及大量外部资源的整合与质量控制,以保持数据的一致性与评估的有效性。
常用场景
经典使用场景
在电信诈骗检测领域,CFSDD数据集作为首个面向风险的中文语音深度伪造基准,其经典使用场景在于评估和开发语音深度伪造检测模型。该数据集通过整合真实良性语音与合成欺诈语音,并引入噪声添加、噪声抑制和编解码处理等多种扰动测试子集,能够模拟真实通话环境下的复杂声学条件。研究人员通常利用该数据集训练深度学习模型,以区分语音的真实性与语义意图的欺诈性,从而在对抗性场景中验证模型的鲁棒性和泛化能力。
实际应用
该数据集的实际应用直接关联电信反欺诈系统的构建与优化。金融机构、通信运营商及网络安全机构可利用基于CFSDD训练的检测模型,实时筛查可疑通话中的合成欺诈语音,从而预警并阻断诈骗行为。其模拟的噪声、抑制和编解码条件,确保了模型能够适应移动网络通话中的音质衰减和背景干扰,为部署在呼叫中心或移动终端的反欺诈解决方案提供了可靠的性能基准与测试依据。
衍生相关工作
围绕CFSDD数据集,已衍生出一系列专注于鲁棒语音深度伪造检测的经典研究工作。这些工作通常探索多模态融合方法,结合音频波形特征与文本语义信息以提升检测精度;部分研究则专注于域自适应技术,以应对未见过的TTS生成系统或新的声学扰动。这些衍生模型不仅推动了检测算法在对抗样本上的进步,也为构建更安全的语音通信生态系统提供了关键技术支撑。
以上内容由遇见数据集搜集并总结生成


