Galgame_Speech_SER_16kHz
收藏Hugging Face2024-11-10 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/litagin/Galgame_Speech_SER_16kHz
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是一个从日本视觉小说(Galgames)中提取的日语语音、文本和情感数据集,旨在用于训练语音情感识别(SER)模型。它包含3,746,131个音频文件,总计5,353小时,大小为104GB。每个音频文件都带有情感标签,这些标签是通过本地大型语言模型(LLM)使用文本转录进行注释的。情感标签范围从0到9,涵盖愤怒、厌恶、尴尬、恐惧、快乐、悲伤、惊讶、中性、性场景声音(aegi声音)和口交场景声音(chupa声音)。数据集采用WebDataset格式,每个tar文件包含约32,768个音频-文本-cls三元组。该数据集不适用于商业用途,且使用该数据集训练的模型必须开源。
This dataset is a Japanese speech, text, and emotion dataset extracted from Japanese visual novels (Galgames), intended for training Speech Emotion Recognition (SER) models. It contains 3,746,131 audio files, totaling 5,353 hours, with a total size of 104 GB. Each audio file is paired with an emotion label, which was annotated using text transcriptions via a local Large Language Model (LLM). The emotion labels range from 0 to 9, covering anger, disgust, embarrassment, fear, happiness, sadness, surprise, neutral, sexual scene sounds (aegi sounds), and oral sex scene sounds (chupa sounds). The dataset is stored in WebDataset format, with each tar file containing approximately 32,768 audio-text-cls triplets. This dataset is not intended for commercial use, and models trained using this dataset must be open-source.
创建时间:
2024-11-10
原始信息汇总
Galgame_Speech_SER_16kHz 数据集概述
基本信息
- 语言: 日语
- 许可证: GPL-3.0
- 多语言性: 单语种
- 名称: Galgame_Speech_SER_16kHz
- 大小: 1M<n<10M
- 任务类别:
- 自动语音识别
- 音频分类
- 标签:
- 语音
- 音频
- 情感
- 语音情感识别
- 文本
- 日语
- 动漫
- 声音
- 视觉小说
- 美少女游戏
数据集描述
- 规模:
- 3,746,131 个音频文件
- 5,353 小时
- 104GB
- 格式:
- 16kHz, 16-bit, 单声道 OGG 文件
- WebDataset 格式
- 语言: 日语
情感标签
- 标签映射:
- 0: "Angry"
- 1: "Disgusted"
- 2: "Embarrassed"
- 3: "Fearful"
- 4: "Happy"
- 5: "Sad"
- 6: "Surprised"
- 7: "Neutral"
- 8: "Sexual1" (aegi 声音)
- 9: "Sexual2" (chupa 声音)
数据集结构
- 格式: WebDataset
- 文件:
- galgame-speech-ser-16kHz-train-{000000..000114}.tar
- 每个 tar 文件包含音频 (OGG)、文本 (TXT) 和标签 (cls) 文件
使用方法
- 加载数据集: python from datasets import load_dataset dataset = load_dataset("litagin/Galgame_Speech_SER_16kHz", streaming=True)
数据集创建
- 动机:
- 需要大规模的日语动漫风格语音数据集,带有情感标签,用于训练语音情感识别模型。
- 需要包含性场景(aegi 和 chupa 声音)的标签。
偏差、风险和限制
- 情感标签: 由本地 LLM 仅通过文本标注,可能不准确。
- 数据来源: 来自美少女游戏,语音与日常生活中的语音有很大差异。
- 内容: 包含 NSFW 音频和台词,不适合所有受众。
- 音频质量: 不适合用于文本到语音合成和语音转换,因为音频质量较低(16kHz)。
- 性别偏差: 数据集中女性声音多于男性声音,可能导致性别偏差。
搜集汇总
数据集介绍
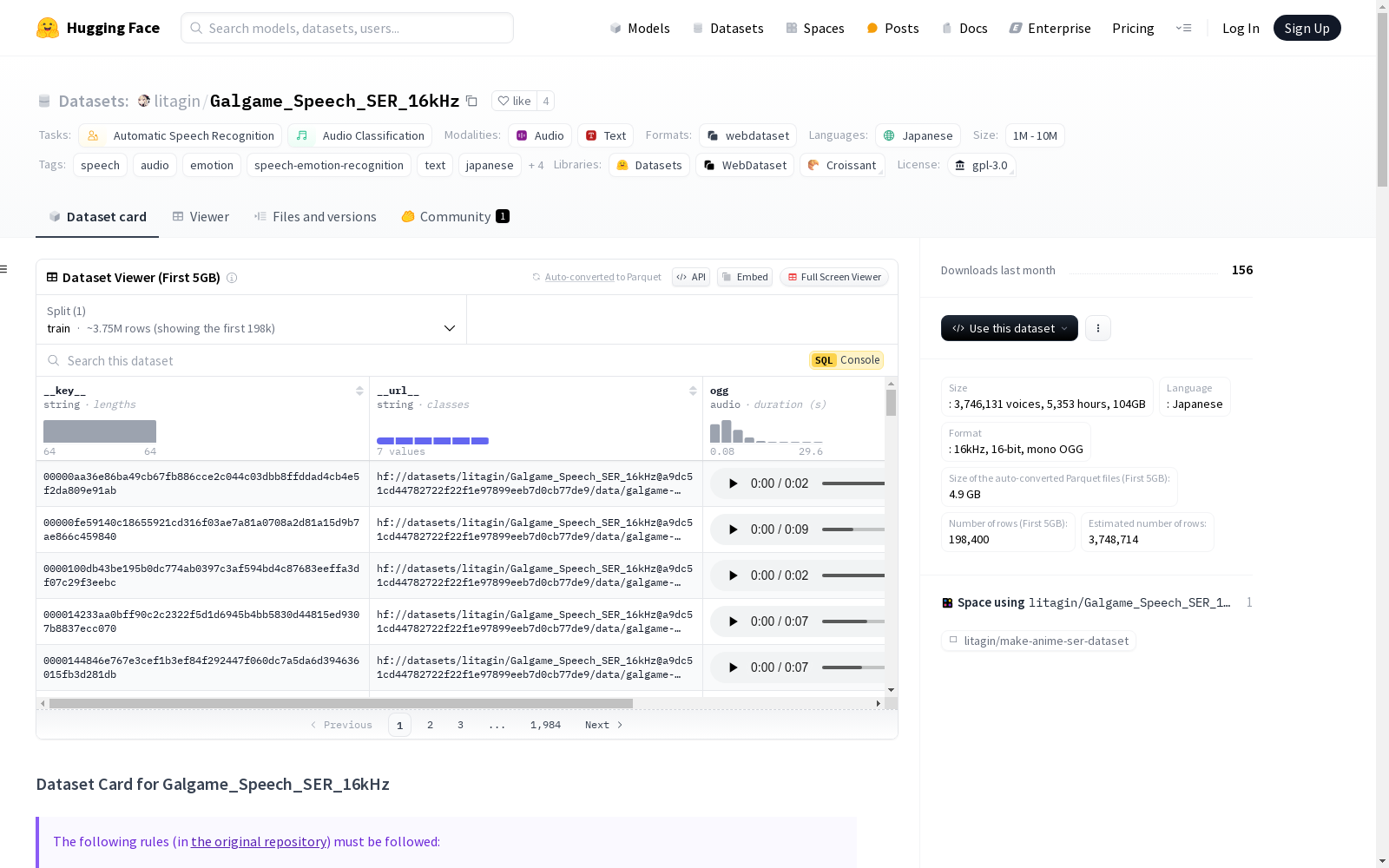
构建方式
Galgame_Speech_SER_16kHz数据集的构建基于日本视觉小说(Galgame)中的语音和文本数据,旨在为语音情感识别(SER)模型的训练提供支持。该数据集在litagin/Galgame_Speech_ASR_16kHz的基础上增加了情感标签,这些标签通过本地LLM(Ministral-8B-Instruct-2410)仅基于文本进行标注,尽管标注质量未经验证,但由于数据集规模庞大且语音情感丰富,预计这些标签仍对SER模型的训练具有参考价值。数据集采用WebDataset格式,包含3,746,131个音频文件,总计5,353小时,容量为104GB。
特点
Galgame_Speech_SER_16kHz数据集的特点在于其大规模性和多样性。数据集包含3,746,131个音频文件,覆盖了从愤怒、厌恶、尴尬到恐惧、快乐、悲伤等多种情感类别,甚至包括特定场景下的声音(如性爱场景中的喘息声)。所有音频文件均为16kHz、16位单声道OGG格式,并配有对应的文本转录和情感标签。尽管情感标签由LLM自动生成,可能存在一定误差,但其丰富的语音情感和多样化的场景使其成为SER模型训练的理想选择。
使用方法
使用Galgame_Speech_SER_16kHz数据集时,可通过Hugging Face的Datasets库加载数据。用户只需调用`load_dataset`函数并设置`streaming=True`以避免一次性下载整个数据集。数据集采用WebDataset格式,适用于PyTorch等深度学习框架。由于数据集包含NSFW内容,使用时需注意其适用场景。此外,用户可根据需求对情感标签进行手动校正,以提升标注质量。
背景与挑战
背景概述
Galgame_Speech_SER_16kHz数据集是一个专注于日语视觉小说(Galgame)语音情感识别(SER)的大规模数据集,旨在为语音情感识别模型的训练提供支持。该数据集由litagin/Galgame_Speech_ASR_16kHz扩展而来,新增了情感标签,这些标签通过本地大型语言模型(LLM)基于文本自动标注。数据集包含3,746,131个音频文件,总计5,353小时,容量达104GB,涵盖了从愤怒到性场景等多种情感类别。该数据集的创建源于对大规模日语动漫风格语音数据的需求,特别是在情感识别和性场景标签方面的研究需求。
当前挑战
Galgame_Speech_SER_16kHz数据集面临的主要挑战包括情感标签的准确性问题和数据集的适用性限制。由于情感标签是通过文本自动标注的,其准确性无法完全保证,尤其是在复杂情感场景中可能出现偏差。此外,数据集主要来源于动漫风格的视觉小说,语音内容与日常生活中的自然语音存在显著差异,可能影响模型在真实场景中的泛化能力。数据集中包含的NSFW(不适合所有受众)音频内容也限制了其应用范围。最后,数据集中女性语音数量远多于男性,可能导致训练模型时出现性别偏差问题。
常用场景
经典使用场景
Galgame_Speech_SER_16kHz数据集在语音情感识别(SER)领域具有广泛的应用。该数据集包含了来自日本视觉小说(Galgame)的大量语音和文本数据,特别适合用于训练和评估SER模型。通过丰富的语音样本和情感标签,研究人员可以深入探索语音信号与情感表达之间的关系,进而提升情感识别的准确性和鲁棒性。
衍生相关工作
基于Galgame_Speech_SER_16kHz数据集,许多经典研究工作得以展开。例如,研究人员利用该数据集开发了多种SER模型,并在情感分类任务中取得了显著进展。此外,该数据集还启发了对特定场景情感(如性感情感)的深入研究,推动了情感识别技术在多样化场景中的应用。这些工作不仅丰富了语音情感识别的研究内容,也为相关领域的技术创新提供了有力支持。
数据集最近研究
最新研究方向
在语音情感识别(SER)领域,Galgame_Speech_SER_16kHz数据集的引入为研究者提供了一个独特的资源,尤其是在日本视觉小说(Galgame)语音情感分析方面。该数据集不仅包含了大量的日语语音数据,还通过本地大型语言模型(LLM)为每段语音标注了情感标签,涵盖了从愤怒、悲伤到性场景声音的多种情感类别。尽管这些标签的准确性有待验证,但其丰富的情感类别和大规模的数据量为SER模型的训练提供了宝贵的实验材料。近年来,随着深度学习技术的进步,SER模型在跨文化和多语言环境中的应用逐渐成为研究热点。Galgame_Speech_SER_16kHz数据集的发布,不仅推动了日语语音情感识别技术的发展,还为跨文化情感分析提供了新的视角。此外,该数据集的开源性质和非商业用途的限制,确保了其在学术研究中的广泛使用,同时也为未来的情感识别研究奠定了坚实的基础。
以上内容由遇见数据集搜集并总结生成


