FVQ-20K
收藏arXiv2025-04-12 更新2025-04-17 收录
下载链接:
https://github.com/wsj-sjtu/FVQ
下载链接
链接失效反馈官方服务:
资源简介:
FVQ-20K是第一个大规模野外人脸视频质量评估数据集,由上海交通大学研究团队创建。该数据集包含20000个野外人脸视频,涵盖各种空间和时间域的失真,以及多样性的人脸属性。数据集通过35名大学生的主观评分进行高质量MOS注释,旨在推进人脸视频质量评估算法的发展。
FVQ-20K is the first large-scale in-the-wild face video quality assessment dataset developed by the research team from Shanghai Jiao Tong University. This dataset contains 20,000 in-the-wild face videos, covering various spatial and temporal domain distortions as well as diverse facial attributes. It is annotated with high-quality Mean Opinion Score (MOS) via subjective scoring from 35 college students, aiming to advance the development of face video quality assessment algorithms.
提供机构:
上海交通大学
创建时间:
2025-04-12
搜集汇总
数据集介绍
构建方式
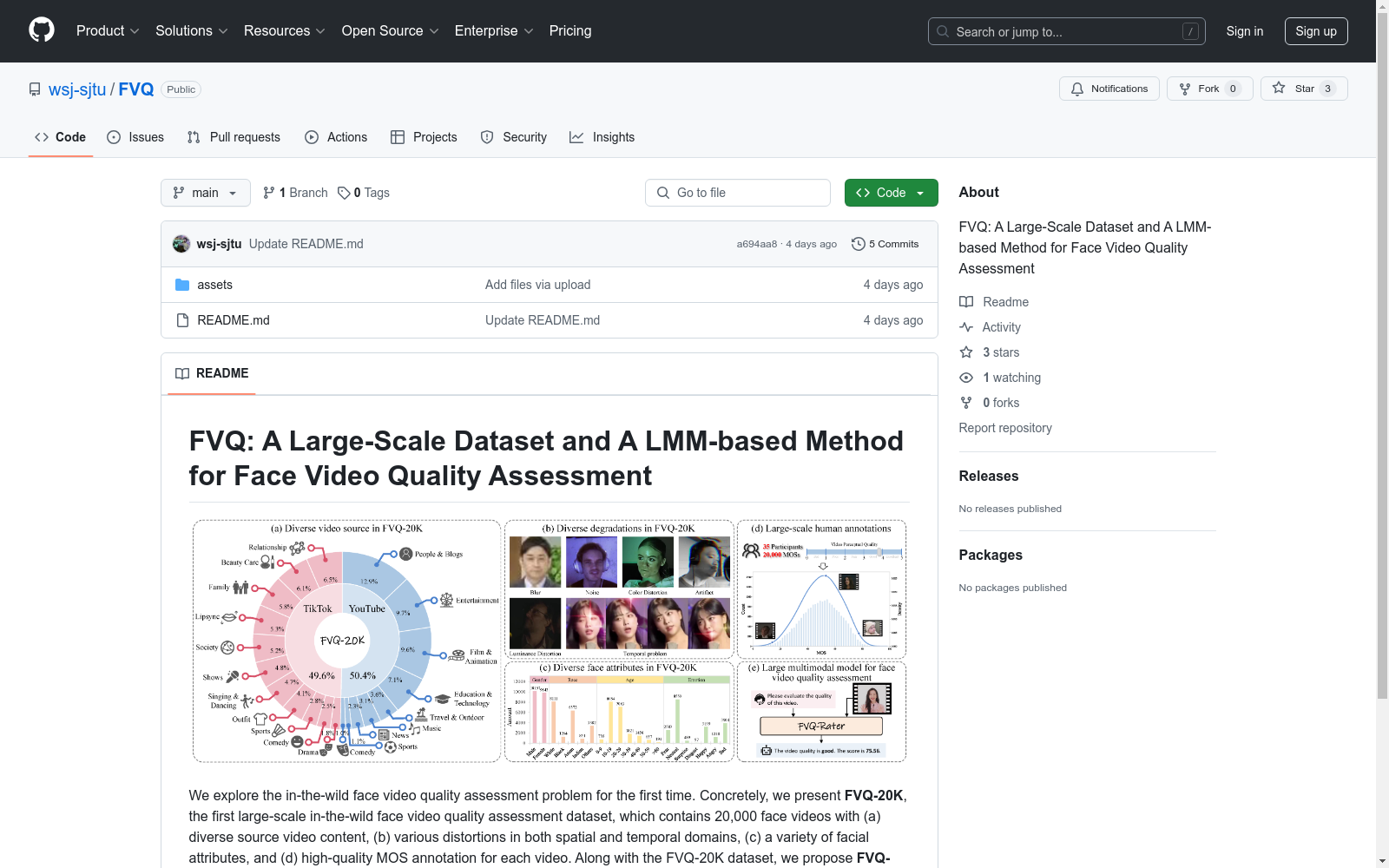
FVQ-20K数据集作为首个大规模野外人脸视频质量评估数据集,其构建过程体现了严谨的科学设计。研究团队从TikTok和YouTube两大社交媒体平台采集了20,000段人脸视频,涵盖11种短视频类别和9种传统视频类别。通过MTCNN和face-alignment算法进行人脸检测与对齐,确保每段5秒视频包含有效面部区域。视频筛选过程采用去重和时长标准化处理,最终形成包含空间失真、时间伪影和多样化人脸属性的样本库。主观实验环节严格遵循ITU-BT.500标准,由35名经过培训的评估者进行Mean Opinion Score(MOS)标注,并通过Z-score标准化和离群值剔除确保数据质量。
特点
该数据集的核心价值体现在三个维度:内容多样性方面,覆盖20种视频类别、5个人种和7种情感状态,包含从360p到4K的多分辨率样本;失真类型方面,系统性地收录了模糊、噪声、色彩失真、亮度异常和时间域伪影等真实场景退化;标注质量方面,通过实验室环境下的受控主观实验获得高可靠性MOS分数,其分布呈现与人类视觉感知高度一致的五级质量分层。特别值得注意的是,数据集通过面部特征分析解耦了主观审美偏好与客观质量评价,为建立专用于人脸视频的质量评估基准提供了理想条件。
使用方法
FVQ-20K数据集支持端到端的视频质量评估模型训练与验证。使用时建议将20,000个样本按80:5:15比例划分为训练、验证和测试集。对于传统VQA方法,可直接提取视频的空间-时间特征进行MOS回归;针对基于LMM的新方法,数据集提供的多维度标注支持质量感知预训练和指令微调。评估时应采用SRCC、PLCC和KRCC三项指标,同时关注不同平台(TikTok/YouTube)子集的跨域性能。为充分发挥数据集价值,推荐结合论文提出的FVQ-Rater框架,整合SlowFast时空特征与FaceNet面部嵌入特征进行多模态质量预测。
背景与挑战
背景概述
FVQ-20K是由上海交通大学的研究团队于2025年提出的首个大规模野外人脸视频质量评估数据集,旨在填补该领域数据资源的空白。随着社交媒体平台上人脸视频内容的爆炸式增长,视频质量评估(VQA)的重要性日益凸显。然而,传统VQA数据集主要针对通用视频内容,忽视了人类视觉系统(HVS)对人脸的特殊感知机制。FVQ-20K包含20,000个从TikTok和YouTube平台采集的多样化人脸视频,涵盖了不同性别、种族、年龄和情感的面部属性,以及包括模糊、噪声、亮度失真等多种真实场景中的退化类型。每个视频均配有经过严格主观实验获得的平均意见分数(MOS),为开发专门针对人脸视频的质量评估算法提供了重要基础。
当前挑战
FVQ-20K面临的挑战主要体现在两个方面:领域问题方面,传统VQA方法难以准确评估人脸视频质量,因为人类对人脸的感知机制与通用视频存在显著差异,且现有VQA数据集中人脸视频占比极低;数据构建方面,收集具有代表性的野外人脸视频需要平衡内容多样性与质量退化类型的覆盖,而大规模MOS标注需要设计严谨的主观实验流程,包括参与者培训、异常值检测等环节以确保标注可靠性。此外,视频中面部属性的多样性(如不同种族的面部特征差异)也给质量评估模型的泛化能力提出了更高要求。
常用场景
经典使用场景
FVQ-20K数据集作为首个大规模野外人脸视频质量评估数据集,其经典使用场景主要集中在计算机视觉与多媒体领域的研究中。该数据集通过整合来自TikTok和YouTube平台的20,000段多样化人脸视频,涵盖了丰富的空间和时间域失真类型,为研究者提供了评估人脸视频质量的基准。其多维度特征(如空间特征、时间特征和面部特定特征)的提取与标注,使得该数据集在训练和验证视频质量评估模型时表现出色,尤其是在处理复杂真实场景下的失真问题时。
衍生相关工作
围绕FVQ-20K数据集已衍生出多项经典工作,包括首个人脸视频质量评估方法FVQ-Rater,该方法创新性地融合了大型多模态模型(LMM)与低秩自适应(LoRA)技术。此外,该数据集还促进了通用视频质量评估方法(如VSFA、FastVQA)在人脸视频上的迁移研究,以及人脸图像质量评估方法(如DSL-FIQA)向视频域的扩展。这些工作共同推动了人脸视频质量评估领域的算法进步与基准完善。
数据集最近研究
最新研究方向
随着社交媒体平台中面部视频内容的爆炸式增长,面部视频质量评估(FVQA)已成为计算机视觉和多媒体领域的重要研究方向。FVQ-20K数据集的推出填补了该领域大规模数据集的空白,为研究者提供了丰富的真实场景面部视频资源。当前研究热点集中在利用多模态大模型(LMM)整合空间、时间和面部特异性特征,通过低秩自适应(LoRA)技术实现高效指令微调,以模拟人类视觉系统对面部质量的感知机制。这一方向不仅推动了面部视频质量评估的精准化,也为视频修复、超分辨率和增强等应用提供了重要基础。数据集的多源采集策略(TikTok和YouTube)和多样化标注(性别、种族、年龄等)进一步拓展了研究的广度和深度,使其成为面部视频质量评估领域的前沿标杆。
相关研究论文
- 1FVQ: A Large-Scale Dataset and A LMM-based Method for Face Video Quality Assessment上海交通大学 · 2025年
以上内容由遇见数据集搜集并总结生成


