TEXTBOOKREASONING, MEGASCIENCE
收藏arXiv2025-07-23 更新2025-08-14 收录
下载链接:
https://huggingface.co/datasets/MegaScience/TextbookReasoning
下载链接
链接失效反馈官方服务:
资源简介:
TEXTBOOKREASONING 数据集是从近 12,000 本大学水平的科学教材中提取的,包含 650,000 个推理问题,涵盖 7 个科学领域。MEGASCIENCE 数据集是一个包含 1,250,000 个实例的大型混合数据集,由高质量的开源数据集组成。这两个数据集旨在推动科学推理研究的发展,并为训练大型语言模型提供支持。
The TEXTBOOKREASONING dataset is extracted from nearly 12,000 college-level science textbooks, containing 650,000 reasoning questions spanning 7 scientific domains. The MEGASCIENCE dataset is a large-scale mixed dataset with 1,250,000 instances, constructed from high-quality open-source datasets. These two datasets aim to advance scientific reasoning research and provide support for training large language models.
提供机构:
上海交通大学 SII, GAIR 实验室
创建时间:
2025-07-23
搜集汇总
数据集介绍
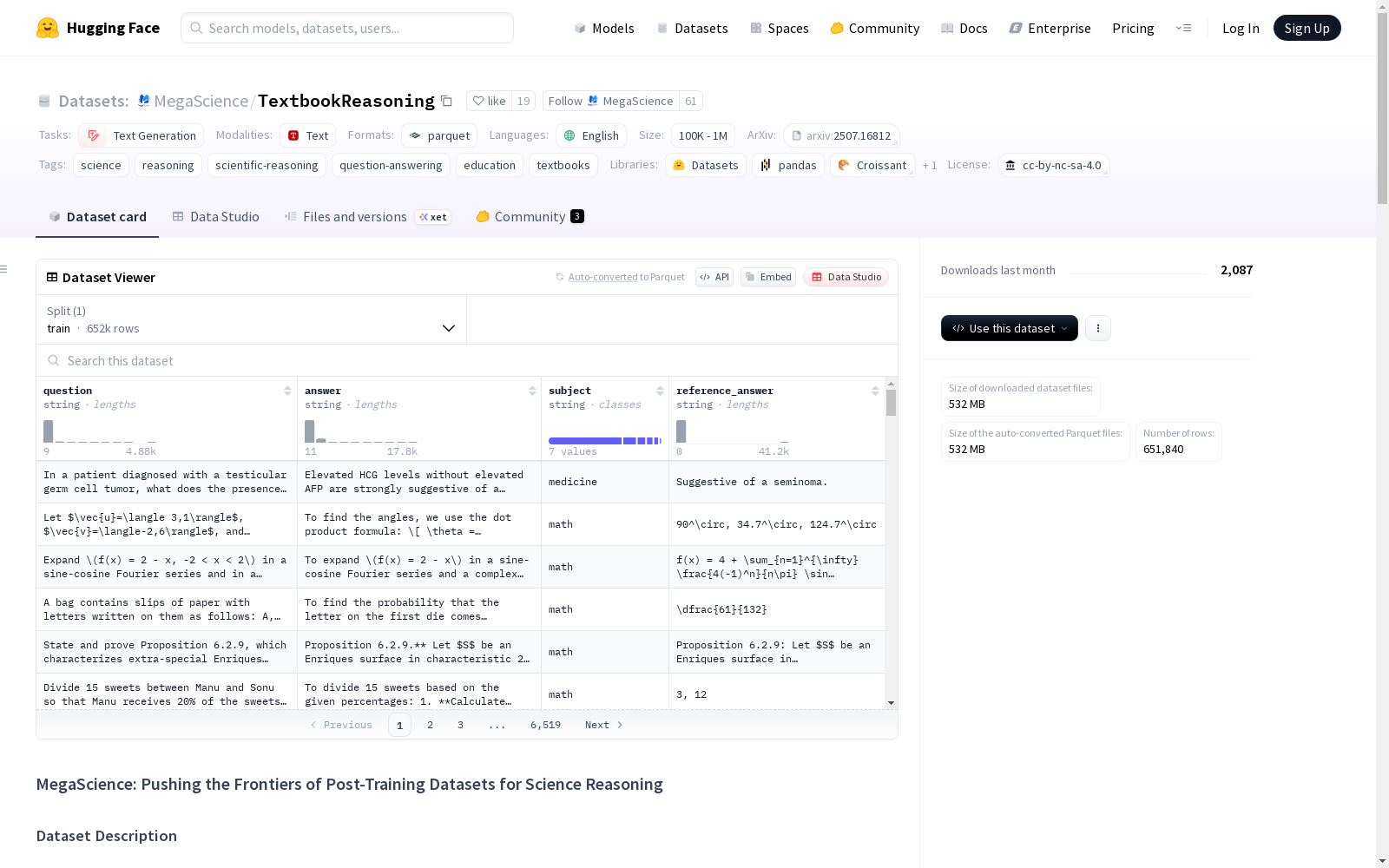
构建方式
TEXTBOOKREASONING数据集通过系统化的流程构建,首先从12,800本大学科学教材中提取内容,经过数字化处理后,采用双重问答对提取策略(高标准与低标准)从教材中挖掘问题与答案。随后,通过去重、问答对精炼、过滤和基于大语言模型的去污染处理,确保数据的高质量和可靠性。MEGASCIENCE数据集则整合了多个公开科学数据集,通过系统的消融研究选择最优数据子集,最终形成包含125万实例的大规模混合数据集。
特点
TEXTBOOKREASONING数据集覆盖物理学、生物学、化学、医学、计算机科学、数学和经济学等7个学科,包含65万道推理问题,其答案均来自权威教材,确保了科学性和准确性。MEGASCIENCE数据集通过优化数据选择方法,显著提升了训练效率和模型性能,其特点是响应长度更短(平均410至721个标记),同时在科学推理任务上达到领先水平。
使用方法
该数据集适用于大语言模型的监督微调,特别是在科学推理任务上。用户可通过开源的数据处理流程和评估框架,复现实验结果并进行公平的模型比较。数据集支持多种评估场景,包括选择题、计算题等,并提供了全面的答案提取策略以确保评估指标的准确性。此外,训练后的模型在Llama3.1、Qwen2.5和Qwen3系列上表现优异,显著优于官方指导模型。
背景与挑战
背景概述
TEXTBOOKREASONING和MEGASCIENCE数据集由上海交通大学SII-GAIR实验室的研究团队于2025年推出,旨在填补开源社区在科学推理数据领域的空白。这两个数据集的核心研究问题是提升大型语言模型在科学领域的推理能力,支持AI科学家的发展和自然科学研究的前沿探索。TEXTBOOKREASONING包含从12k大学级科学教科书中提取的65万条推理问题,覆盖物理、生物、化学等7个学科;MEGASCIENCE则整合了125万条高质量开源数据,通过系统消融研究优化数据选择方法。这些数据集显著提升了模型在科学任务上的性能,尤其在计算类问题中表现突出,推动了开源社区在科学推理领域的研究进展。
当前挑战
该领域面临多重挑战:1) 评估可靠性方面,现有科学基准多采用选择题形式,简化了科学推理的复杂性,导致模型在计算任务中表现不佳;2) 数据净化技术脆弱,传统n-gram方法易被轻微表述变化规避,难以确保评估完整性;3) 参考答案质量参差,网络抓取内容受AI生成文本污染,LLM生成答案存在幻觉问题;4) 知识蒸馏方法表面化,直接使用大模型生成思维链易产生过度思考,影响小模型训练效率。构建过程中,团队需应对教科书数字化、双重QA对提取、去重、答案精炼等多环节挑战,并通过LLM实现自动化流程以确保数据质量与规模。
常用场景
经典使用场景
TEXTBOOKREASONING和MEGASCIENCE数据集在科学推理领域具有广泛的应用场景,特别是在大学级别的科学教育和高阶认知任务中。这些数据集通过从权威教科书中提取的650k推理问题和1.25百万实例,覆盖了物理学、生物学、化学、医学、计算机科学、数学和经济学等多个学科。其经典使用场景包括训练和评估大型语言模型(LLMs)在科学推理任务中的表现,例如解决复杂的计算问题、进行多步推理和验证科学知识的准确性。
衍生相关工作
TEXTBOOKREASONING和MEGASCIENCE数据集衍生了许多相关经典工作,特别是在科学推理和语言模型优化领域。例如,基于这些数据集训练的Llama3.1、Qwen2.5和Qwen3系列基础模型在科学任务中显著优于官方指导模型。此外,这些数据集还推动了科学推理评估框架的发展,如Language Model Open Science Evaluation系统,该系统覆盖了15个基准测试,支持多样化的科学任务评估。
数据集最近研究
最新研究方向
TEXTBOOKREASONING和MEGASCIENCE数据集在科学推理领域的最新研究方向主要集中在提升大型语言模型(LLM)的科学推理能力。通过从大学级科学教科书中提取真实参考答案,构建了包含650k推理问题的TEXTBOOKREASONING数据集,并进一步整合了1.25百万实例的MEGASCIENCE数据集。这些数据集通过系统化的数据选择方法和解决方案标注技术,显著提升了模型在科学任务上的性能。实验表明,基于这些数据集训练的模型在多个科学基准测试中表现优异,尤其是在计算推理任务上。此外,研究还发现,MEGASCIENCE数据集对于更大更强的模型表现出更好的扩展效益,为科学推理领域的前沿研究提供了重要支持。
相关研究论文
- 1MegaScience: Pushing the Frontiers of Post-Training Datasets for Science Reasoning上海交通大学 SII, GAIR 实验室 · 2025年
以上内容由遇见数据集搜集并总结生成


