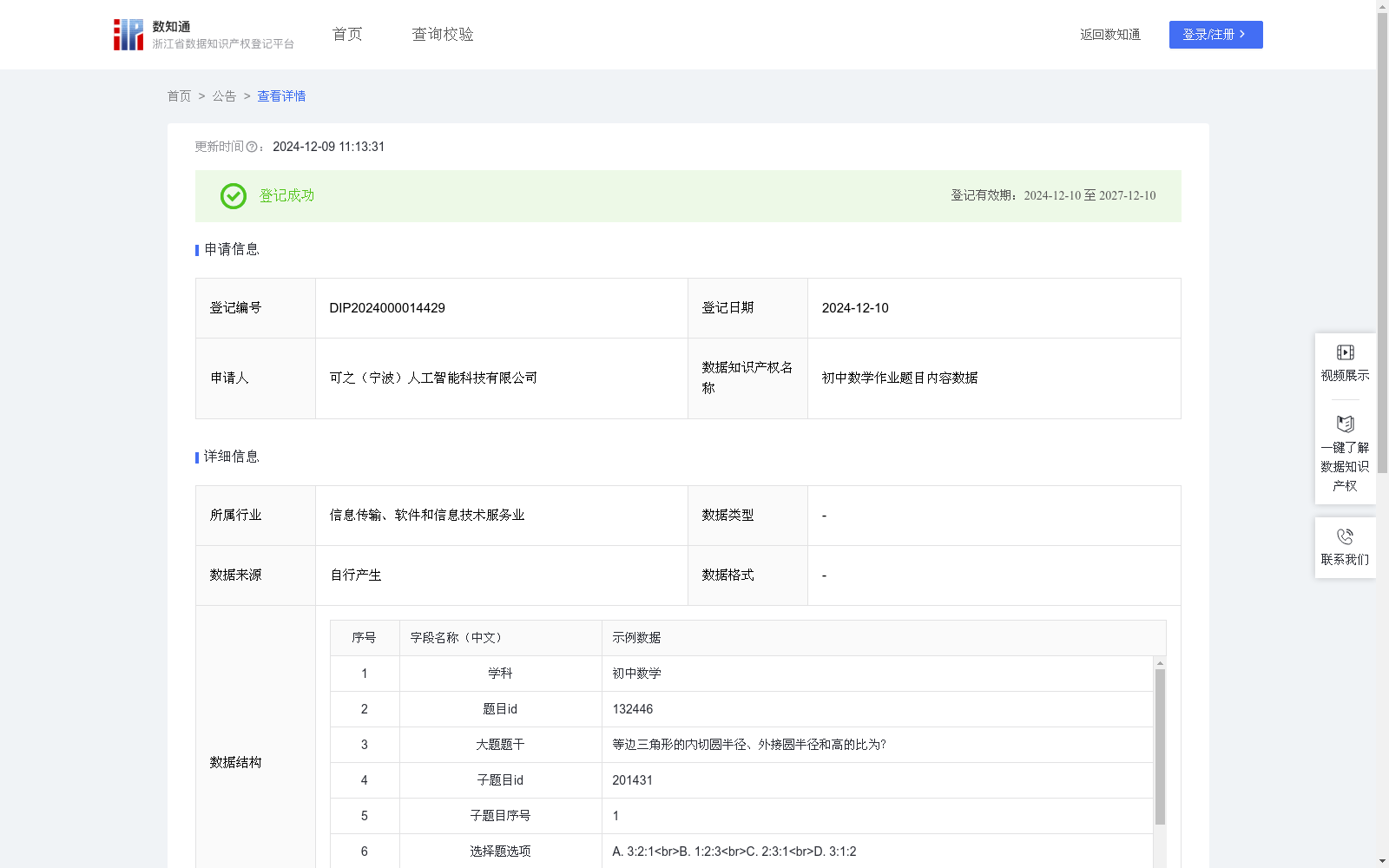
初中数学作业题目内容数据
收藏浙江省数据知识产权登记平台2024-12-09 更新2024-12-10 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/98318
下载链接
链接失效反馈官方服务:
资源简介:
基于收集和预处理的初中数学作业题目内容数据,可以用于构建多个实用的初中数学方面的教育技术应用场景。例如,这些数据可以作为训练自然语言处理模型的物料,用于开发初中数学智能教育助手,帮助学生解答问题或提供个性化学习建议。通过分析初中数学作业题目的难度、题型和知识点,教育工作者可以更好地理解学生的学习进度和难点,进而设计针对性的教学计划。此外,这些数据还能用于开发初中数学自动阅卷系统,提高评分效率和准确性。在教学研究中,数据可以助力研究者分析教学效果,优化教学方法。
1.数据收集与预处理:从公司自研题库筛选收集数学题目数据。去除无效或不完整的数据记录,保证数据质量。2.特征提取:1)文本分割:使用自然语言处理(NLP)技术,将题目文本分割成可识别的字段。2)使用spaCy关键词匹配工具识别题目学科;3)使用Python的re库,通过正则表达式匹配输出题目ID、 子题目ID和子题目序号;4)使用NLP工具进行句子分割,识别输出题目的主体部分作为大题题干和子题题干。5)使用Python的re库,通过识别选项前的标识符(如A、B、C、D)来提取输出选择题选项;3.题型分类,根据题目的格式和结构识别题型,使用Python的difflib库进行模板匹配,并使用训练好的scikit-learn机器学习模型对题型进行分类;4.题目难度识别,使用训练好的朴素贝叶斯分类器机器学习模型根据题目内容预测难度等级(分1-5级,5级最难);5.作答区域高度识别,如题目包含图像,使用图像处理库(如OpenCV)识别作答区域的高度;6.知识点提取,使用NLP技术提取题目中的关键词和概念,并使用内部用Neo4j工具(一种知识图谱构建工具)构建好的知识图谱进行匹配后输出知识点。
Based on the collected and preprocessed junior high school mathematics homework question data, multiple practical educational technology application scenarios in the field of junior high school mathematics can be built. For example, this data can be used as training material for natural language processing models to develop junior high school mathematics intelligent educational assistants, helping students solve problems or provide personalized learning suggestions. By analyzing the difficulty, question types and knowledge points of junior high school mathematics homework questions, educators can better understand students' learning progress and pain points, and then design targeted teaching plans. In addition, this data can also be used to develop junior high school mathematics automatic grading systems to improve grading efficiency and accuracy. In teaching research, the data can help researchers analyze teaching effects and optimize teaching methods.
1. Data Collection and Preprocessing: Screen and collect mathematics question data from the company's self-developed question bank. Remove invalid or incomplete data records to ensure data quality.
2. Feature Extraction:
1) Text Segmentation: Use natural language processing (NLP) technologies to segment question text into identifiable fields.
2) Use the spaCy keyword matching tool to identify the subject of the question;
3) Use Python's re library to match and output the question ID, sub-question ID and sub-question serial number through regular expressions;
4) Use NLP tools to perform sentence segmentation, identify and output the main part of the question as the main question stem and sub-question stem.
5) Use Python's re library to extract and output multiple-choice question options by identifying identifiers before options (such as A, B, C, D);
3. Question Type Classification: Identify question types based on the format and structure of the questions, use Python's difflib library for template matching, and use a trained scikit-learn machine learning model to classify question types;
4. Question Difficulty Recognition: Use a trained Naive Bayes classifier machine learning model to predict the difficulty level based on the question content (graded from 1 to 5, with level 5 being the most difficult);
5. Answer Area Height Recognition: If the question contains images, use image processing libraries (such as OpenCV) to recognize the height of the answer area;
6. Knowledge Point Extraction: Use NLP technologies to extract keywords and concepts in the questions, and use the internal knowledge graph built with Neo4j (a knowledge graph construction tool) for matching to output the knowledge points.
提供机构:
可之(宁波)人工智能科技有限公司
创建时间:
2024-10-31
搜集汇总
数据集介绍
特点
该数据集包含715条初中数学作业题目内容,每日更新,涵盖题目ID、题干、选择题选项、难度、题型和知识点等信息。适用于教育技术应用、智能教育助手开发和自动阅卷系统等场景。
以上内容由遇见数据集搜集并总结生成


