21-EuroParl
收藏arXiv2025-10-23 更新2025-11-05 收录
下载链接:
https://hf-mirror.com/datasets/PaulLerner/21-EuroParl
下载链接
链接失效反馈官方服务:
资源简介:
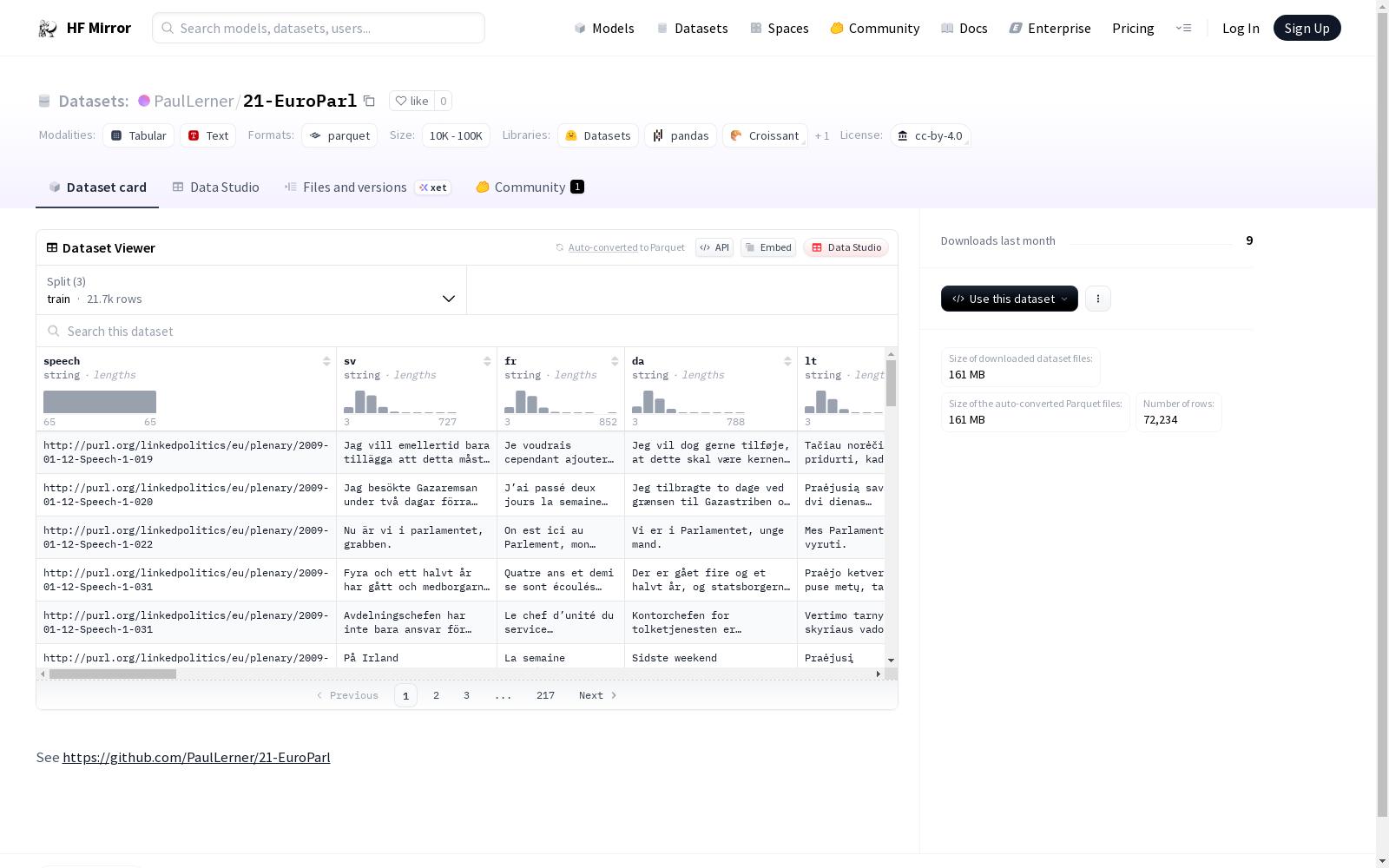
21-EuroParl是一个多语言并行语料库,它基于欧洲议会(EP)的议会程序,包含了每位发言人的政治隶属关系信息。该数据集由1.5M个句子组成,总计4千万个单词和2.49亿个字符。它覆盖了从2009年到2011年的三年时间,来自27个国家的1000多名发言者,12个欧盟政党,25个欧盟委员会和数百个国内政党。数据集以句子级别进行对齐,并包含了丰富的元数据,如发言人的政治隶属关系(国家和欧盟政党)、日期和语言。这个数据集的创建过程涉及了对LinkedEP数据集的查询、清洗、句子对齐等步骤。21-EuroParl旨在用于研究多语言大型语言模型(LLMs)的政治公平性,特别是通过机器翻译来评估LLMs是否存在政治偏见。
21-EuroParl is a multilingual parallel corpus based on the parliamentary proceedings of the European Parliament (EP), which contains the political affiliation information of each speaker. The dataset consists of 1.5 million sentences, totaling 40 million words and 249 million characters. It spans a three-year period from 2009 to 2011, with over 1,000 speakers from 27 countries, 12 EU political parties, 25 EU committees, and hundreds of national political parties. The dataset is aligned at the sentence level and includes rich metadata, such as the speakers' political affiliations (national and EU political parties), dates, and languages. The creation of this dataset involves steps including querying, cleaning, and sentence alignment of the LinkedEP dataset. 21-EuroParl is designed for research on political fairness of multilingual large language models (LLMs), particularly to evaluate whether LLMs exhibit political biases via machine translation.
提供机构:
法国巴黎索邦大学、法国国家科学研究中心、ISIR实验室
创建时间:
2025-10-23
搜集汇总
数据集介绍
构建方式
21-EuroParl数据集基于欧洲议会辩论记录构建,通过整合LinkedEP知识图谱中的多语言演讲内容与元数据,形成21种语言的句级对齐语料。构建过程中采用Bertalign工具进行句子对齐,利用LaBSE句子嵌入计算双语对齐分数,仅保留一对一且相似度阈值高于0.8的高质量对齐实例。最终从原始37,799篇演讲中筛选出72,234个多语言对齐实例,涵盖2009至2011年间的议会辩论内容,确保语料在时间跨度和政治代表性上的完整性。
特点
该数据集具备显著的多语言并行特性,涵盖保加利亚语至瑞典语等21种欧盟官方语言,形成420个语言对组合。其独特价值在于融合了丰富的政治元数据,包括演讲者所属的欧盟政党、国家政党、欧盟委员会及国籍信息,覆盖12个欧盟政党、25个委员会和272个国家政党。数据集规模达150万句、4000万词量级,按年份划分为训练、验证和测试集,为研究政治语境下的多语言处理提供了结构化基准。
使用方法
该数据集适用于多语言机器翻译质量评估与政治偏见分析研究。使用者可基于其句级对齐特性,通过零样本提示模板驱动大语言模型生成翻译结果,并利用sBLEU与COMET指标进行质量评估。针对政治公平性研究,可采用基于Borda计数的方法聚合不同政党语料的翻译质量排名。数据集按时间划分的测试集支持跨语言对的系统性比较,其元数据结构支持从政党归属、原始语言等维度开展翻译质量差异的归因分析。
背景与挑战
背景概述
21-EuroParl数据集由巴黎索邦大学研究团队于2025年创建,旨在解决传统欧洲议会语料库的双语平行局限性。该数据集基于欧洲议会2009至2011年间的辩论记录,构建了涵盖21种语言的多元平行语料,包含7.2万条句子级对齐文本及完整的政治元数据。其核心价值在于首次实现了跨语言的政治立场可比分析,为研究多语言大模型的政治公平性提供了关键数据支撑,推动了计算社会科学与自然语言处理的交叉融合。
当前挑战
该数据集主要面临双重挑战:在领域问题层面,需解决多语言机器翻译中因政治立场差异导致的系统性偏差,例如主流政党与边缘政党文本的翻译质量差异;在构建过程中,需克服21种语言句子级对齐的技术难题,包括处理语言识别错误、翻译重复文本过滤,以及通过Bertalign工具实现高精度跨语言对齐时面临的语义相似度阈值设定等工程挑战。
常用场景
经典使用场景
在机器翻译研究领域,21-EuroParl数据集以其21种语言的句级对齐特性成为评估多语言模型性能的基准工具。该数据集通过覆盖欧洲议会三年间的政治演讲内容,为研究者提供了跨语言对比分析的理想素材。其多语言平行语料特别适用于探究翻译质量与政治倾向的关联性,成为检测算法公平性的重要实验平台。
解决学术问题
该数据集有效解决了多语言机器翻译领域缺乏政治倾向标注资源的难题。通过提供演讲者政党归属等元数据,使研究者能够系统分析翻译系统对不同政治立场文本的处理差异。其实证研究表明主流政党演讲的翻译质量显著优于边缘政党,这为构建更公平的机器翻译模型提供了数据支撑,推动了算法公平性研究向多语言场景的拓展。
衍生相关工作
基于该数据集的政治公平性研究催生了多语言模型评估新范式,相关成果已延伸至语言资源建设领域。研究者利用其丰富的元数据开发了基于Borda排序的公平性度量方法,这种方法后被应用于其他多语言语料的偏见检测。该数据集还促进了跨语言表示学习研究,为构建政治立场感知的翻译模型奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


