MiChao
收藏魔搭社区2025-11-26 更新2024-06-01 收录
下载链接:
https://modelscope.cn/datasets/Shanghai_AI_Laboratory/MiChao
下载链接
链接失效反馈官方服务:
资源简介:
## 简介
**蜜巢·花粉1.0**开源数据集为文本数据集。数据集由互联网公开可访问网站2022年历史数据收集整理而成,数据总量超过1亿条。数据集具备来源可靠,数据质量高,可持续稳定更新等特点。蜜巢·花粉数据集已被应用于多个大模型的训练,为媒体垂直领域提供基于材料的知识问答与内容生成、分析报告自动生成、文稿内容审校与润色改写等各类智能生成式服务。
## 数据内容
### 数据组成
蜜巢·花粉1.0语料均来源于公开可访问的中文互联网数据,领域包括新闻、政务等。通过关键词过滤、图片抽取、规则过滤、格式转换等一系列数据处理流程,形成了一批高质量的文本大模型语料集。最终清洗后的数据达7000余万条,同时包括100余万个图片链接,文件大小超 240 GB。
### 数据样例
数据样例如下:
```json
{
"id": "Bk-EeyvxK4tBHfZxh20R",
"img_list": [
{
"url": "https://upload.jsw.com.cn/2022/0106/1641451086336.png"
},
{
"url": "https://upload.jsw.com.cn/2022/0106/1641451097332.jpg"
}
],
"title": "江苏镇江:“农家书屋”丰富生活 乡村“文化粮仓”润情润心",
"post_date": "2022-01-06",
"content": "\n\n金山网讯 “农家书屋”建设是加强农村基层文化建设、完善社会主义公共文化服务体系的时代要求。为进一步推进党史学习教育开展,深入开展“我为群众办实事”实践活动,推动全民阅读氛围营造,江苏省镇江市丹徒区上党镇积极推进“农家书屋”建设,丰富村民文化生活,打造乡村的“文化粮仓”。\n走进上党镇上党村的农家书屋,一面墙的书籍映入眼帘,有文化类、科技类、生活类……而另一面墙则更加令人眼前一亮,上面印着“书香上党 农家书屋 有声阅读”大字样,还板块清晰配了8个二维码,每个二维码都对应一个专辑,具体涵盖了党的发展历程、乡村振兴、种植养殖、经典名著、亲子教育、健康养生等8个方面。目前,上党镇拥有1个镇级、15个村级农家书屋,为广大群众提供阅读书籍、学习知识、交流思考的空间,并配备了管理员为群众提供图书借阅及农家书屋活动服务。\n“我在书屋里面借阅了一本《陈云家风》,用手机在墙上扫码,‘听书’很方便。”一名在农家书屋借了书的村民高高兴兴地说。随着时代变迁,上党镇农家书屋工作人员大胆创新,勇于尝试,建立“互联网+农家书屋”“大讲堂+自习室”的书屋模式,使书屋成为助力乡村振兴的新支点、为民办事的新起点。\n随着全民阅读氛围的提高,上党镇农家书屋也越来越受村民的喜爱,成了更多村民的“精神”书屋。\n上党镇的交通设施、教育资源较之市区有些落后,“买书难、借书难、读书难”的问题困扰着村民,农家书屋的出现,将知识“搬”到村民家门口,补齐了乡村的阅读短板,保障了农民最基本的文化权益,缩小了城市与农村的阅读差距,使文化共享更上一阶层。\n“农民富裕了,家乡变美了,生活水平高了。”这是上党镇村民们共同的心声,农家书屋的建设使公共文化资源触手可及,点亮了村民的书香生活。"
}
```
**字段说明**
- **id**:【字符串类型】文档的唯一ID。
- **img_list**:【数组类型】,文档内包含的图片url列表。
- **title**: 【字符串类型】文档的标题,格式为普通Text格式或Markdown格式。
- **post_date**: 【字符串类型】文档发布日期。
- **content**: 【字符串类型】文档的内容,格式为普通Text格式或Markdown格式。
### 数据处理过程
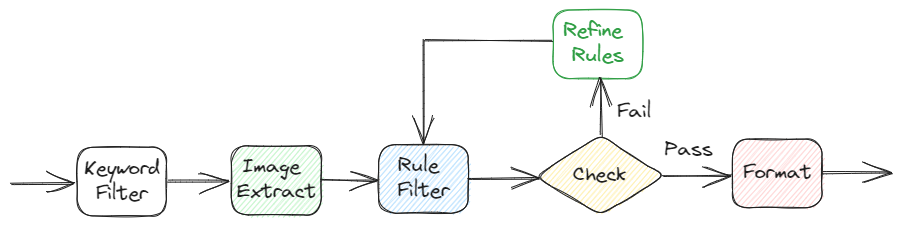
1. **关键词过滤**:首先通过关键词库进行过滤,去除包含敏感词的语料内容。
2. **图片抽取**:采用 xpath 抽取图片链接,保存为数组字段。
3. **规则过滤**:
- 使用 xpath 去除网页中的html标签
- 过滤文本长度小于 200 字符的语料
4. **质检**:通过人工抽检+模型检测的方式进行数据质检。
5. **细化规则**:对于不符合要求的数据,细化规则,并沉淀至规则库。
6. **格式化**:生成保留图片链接的标准 MarkDown 格式。
## 许可
蜜巢·花粉1.0整体采用[CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/)许可协议。
## 特别注意事项
请注意,本数据集的某些子集可能受制于其他协议规定。在使用特定子集之前,请务必仔细阅读相关协议,确保合规使用。更为详细的协议信息,请在特定子集的相关文档或元数据中查看。
OpenDataLab作为非盈利机构,倡导和谐友好的开源交流环境,若在开源数据集内发现有侵犯您合法权益的内容,可发送邮件至(OpenDataLab@pjlab.org.cn),邮件中请写明侵权相关事实的详细描述并向我们提供相关的权属证明资料。我们将于3个工作日内启动调查处理机制,并采取必要的措施进行处置(如下架相关数据)。但您应确保您投诉的真实性,否则采取措施后所产生的不利后果应由您独立承担。
## 引文
```
@misc{liu2023michaohuafen,
title={MiChao-HuaFen 1.0: A Specialized Pre-trained Corpus Dataset for Domain-specific Large Models},
author={Yidong Liu and FuKai Shang and Fang Wang and Rui Xu and Jun Wang and Wei Li and Yao Li and Conghui He},
year={2023},
eprint={2309.13079},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
#### 下载方法
:modelscope-code[]{type="sdk"}
:modelscope-code[]{type="git"}
## Overview
**MiChao·HuaFen 1.0** is an open-source text dataset. It is collected and organized from the historical data of publicly accessible websites in 2022, with a total of over 100 million entries. The dataset features reliable sources, high data quality, and sustainable and stable updates. The MiChao-HuaFen dataset has been applied to the training of multiple large language models (LLMs), providing various intelligent generative services for the vertical media domain, including material-based knowledge QA and content generation, automatic analysis report generation, manuscript proofreading, polishing and rewriting, etc.
## Data Content
### Data Composition
The corpus of MiChao·HuaFen 1.0 is all sourced from publicly accessible Chinese Internet data, covering domains such as news and government affairs. After a series of data processing procedures including keyword filtering, image extraction, rule-based filtering, and format conversion, a high-quality text corpus for large language models has been formed. The final cleaned data amounts to over 70 million entries, including more than 1 million image URLs, with a total file size exceeding 240 GB.
### Data Samples
The data samples are as follows:
json
{
"id": "Bk-EeyvxK4tBHfZxh20R",
"img_list": [
{
"url": "https://upload.jsw.com.cn/2022/0106/1641451086336.png"
},
{
"url": "https://upload.jsw.com.cn/2022/0106/1641451097332.jpg"
}
],
"title": "Jiangsu Zhenjiang: 'Farm Book House' Enriches Rural Life, 'Cultural Granary' Nourishes Hearts and Minds",
"post_date": "2022-01-06",
"content": "

Jinshan Net News: The construction of 'Farm Book Houses' is a requirement of the times for strengthening rural grassroots cultural construction and improving the socialist public cultural service system. To further advance Party history learning and education, deeply carry out the practical activities of 'I Do Practical Things for the Masses', foster a national reading atmosphere, and promote the development of 'Farm Book Houses' in Shangdang Town, Dantu District, Zhenjiang City, Jiangsu Province, so as to enrich villagers' cultural lives and build rural 'cultural granaries'.
Entering the Farm Book House in Shangdang Village of Shangdang Town, a wall of books comes into view, covering categories such as culture, technology, daily life... The other wall is even more striking, printed with the large characters 'Shangdang Book Farm House Audio Reading', and clearly equipped with 8 QR codes, each corresponding to an album covering 8 aspects including the development history of the Party, rural revitalization, planting and breeding, classic masterpieces, parent-child education, health preservation, etc. At present, Shangdang Town has 1 town-level and 15 village-level Farm Book Houses, providing spaces for the masses to read books, learn knowledge, communicate and reflect, and equipped with administrators to offer book borrowing and Farm Book House activity services for the public.
'I borrowed a copy of *Chen Yun's Family Style* from the book house, and scanned the code on the wall with my mobile phone to 'listen to the book', which is very convenient,' said a villager who borrowed a book from the Farm Book House happily. With the passage of time, the staff of the Farm Book Houses in Shangdang Town have boldly innovated and dared to experiment, establishing the 'Internet + Farm Book House' and 'Lecture Hall + Study Room' models, making the book houses a new fulcrum for supporting rural revitalization and a new starting point for serving the people.
With the improvement of the national reading atmosphere, the Farm Book Houses in Shangdang Town are increasingly popular among villagers, becoming the 'spiritual book house' for more villagers.
The transportation facilities and educational resources in Shangdang Town are relatively backward compared with urban areas, and the problems of 'difficulty in buying books, borrowing books, and reading' have plagued the villagers. The emergence of Farm Book Houses has brought knowledge to the villagers' doorsteps, making up for the reading shortcomings in rural areas, protecting farmers' basic cultural rights and interests, narrowing the reading gap between urban and rural areas, and advancing cultural sharing to a new level.
'Farmers have become richer, their hometowns have become more beautiful, and their living standards have improved.' This is the common aspiration of the villagers in Shangdang Town. The construction of Farm Book Houses has made public cultural resources readily accessible, lighting up the book-filled lives of the villagers."
}
**Field Descriptions**
- **id**: [String type] Unique ID of the document.
- **img_list**: [Array type] List of image URLs contained in the document.
- **title**: [String type] Title of the document, in plain Text or Markdown format.
- **post_date**: [String type] Publication date of the document.
- **content**: [String type] Content of the document, in plain Text or Markdown format.
### Data Processing Pipeline

1. **Keyword Filtering**: First, filter out corpus containing sensitive words via a keyword library.
2. **Image Extraction**: Extract image links using XPath and save as an array field.
3. **Rule-based Filtering**:
- Remove HTML tags from web pages using XPath
- Filter out corpus with text length less than 200 characters
4. **Quality Inspection**: Conduct data quality inspection via manual spot-check combined with model detection.
5. **Rule Refinement**: For non-compliant data, refine rules and add them to the rule base.
6. **Formatting**: Generate standard Markdown format that retains image links.
## License
The entire MiChao·HuaFen 1.0 dataset is licensed under [CC BY-SA 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
## Special Notes
Please note that some subsets of this dataset may be subject to other agreements. Before using a specific subset, please carefully read the relevant agreements to ensure compliant usage. For more detailed license information, please refer to the relevant documentation or metadata of the specific subset.
OpenDataLab, as a non-profit organization, advocates a harmonious and friendly open-source communication environment. If you find content in the open-source dataset that infringes your legitimate rights and interests, please send an email to `OpenDataLab@pjlab.org.cn`. In the email, please provide a detailed description of the infringement facts and relevant ownership certification materials. We will launch an investigation and handling mechanism within 3 working days and take necessary measures such as removing the relevant data. However, you must ensure the authenticity of your complaint; otherwise, you shall bear all adverse consequences resulting from the measures taken.
## Citation
@misc{liu2023michaohuafen,
title={MiChao-HuaFen 1.0: A Specialized Pre-trained Corpus Dataset for Domain-specific Large Models},
author={Yidong Liu and FuKai Shang and Fang Wang and Rui Xu and Jun Wang and Wei Li and Yao Li and Conghui He},
year={2023},
eprint={2309.13079},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
## Download Method
:modelscope-code[]{type="sdk"}
:modelscope-code[]{type="git"}
提供机构:
maas
创建时间:
2024-05-28


