National COVID Cohort Collaborative
收藏re3data.org2024-05-31 收录
下载链接:
https://www.re3data.org/repository/r3d100013422
下载链接
链接失效反馈官方服务:
资源简介:
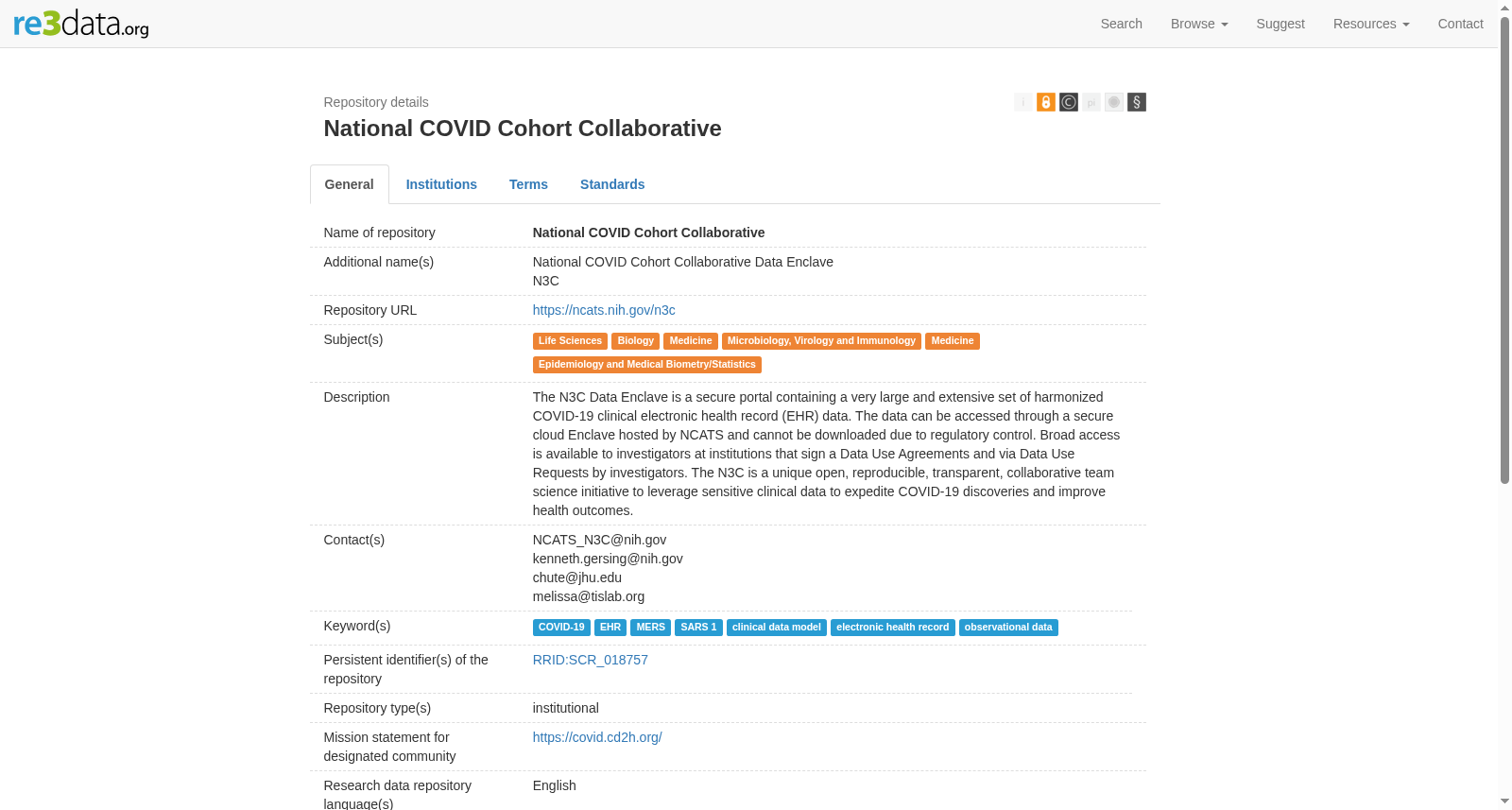
The N3C Data Enclave is a secure portal containing a very large and extensive set of harmonized COVID-19 clinical electronic health record (EHR) data. The data can be accessed through a secure cloud Enclave hosted by NCATS and cannot be downloaded due to regulatory control. Broad access is available to investigators at institutions that sign a Data Use Agreements and via Data Use Requests by investigators. The N3C is a unique open, reproducible, transparent, collaborative team science initiative to leverage sensitive clinical data to expedite COVID-19 discoveries and improve health outcomes.
N3C数据堡垒是一个包含大量且广泛的协调一致的COVID-19临床电子健康记录(EHR)数据的加密门户。该数据可通过由NCATS托管的加密云堡垒进行访问,由于监管控制,无法进行下载。对于签署数据使用协议的机构的研究人员,以及通过数据使用请求的研究人员,均提供广泛访问权限。N3C是一项独特的开放、可复制、透明、协作的团队科学倡议,旨在利用敏感的临床数据,加速COVID-19的发现并提升健康结果。
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个安全门户,包含大量协调的COVID-19临床电子健康记录数据,旨在通过团队科学倡议促进COVID-19研究。访问受限,需通过数据使用协议申请,适用于生命科学、医学和流行病学等领域的研究。
以上内容由遇见数据集搜集并总结生成


