fancyzhx/ag_news
收藏Hugging Face2024-03-07 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/fancyzhx/ag_news
下载链接
链接失效反馈资源简介:
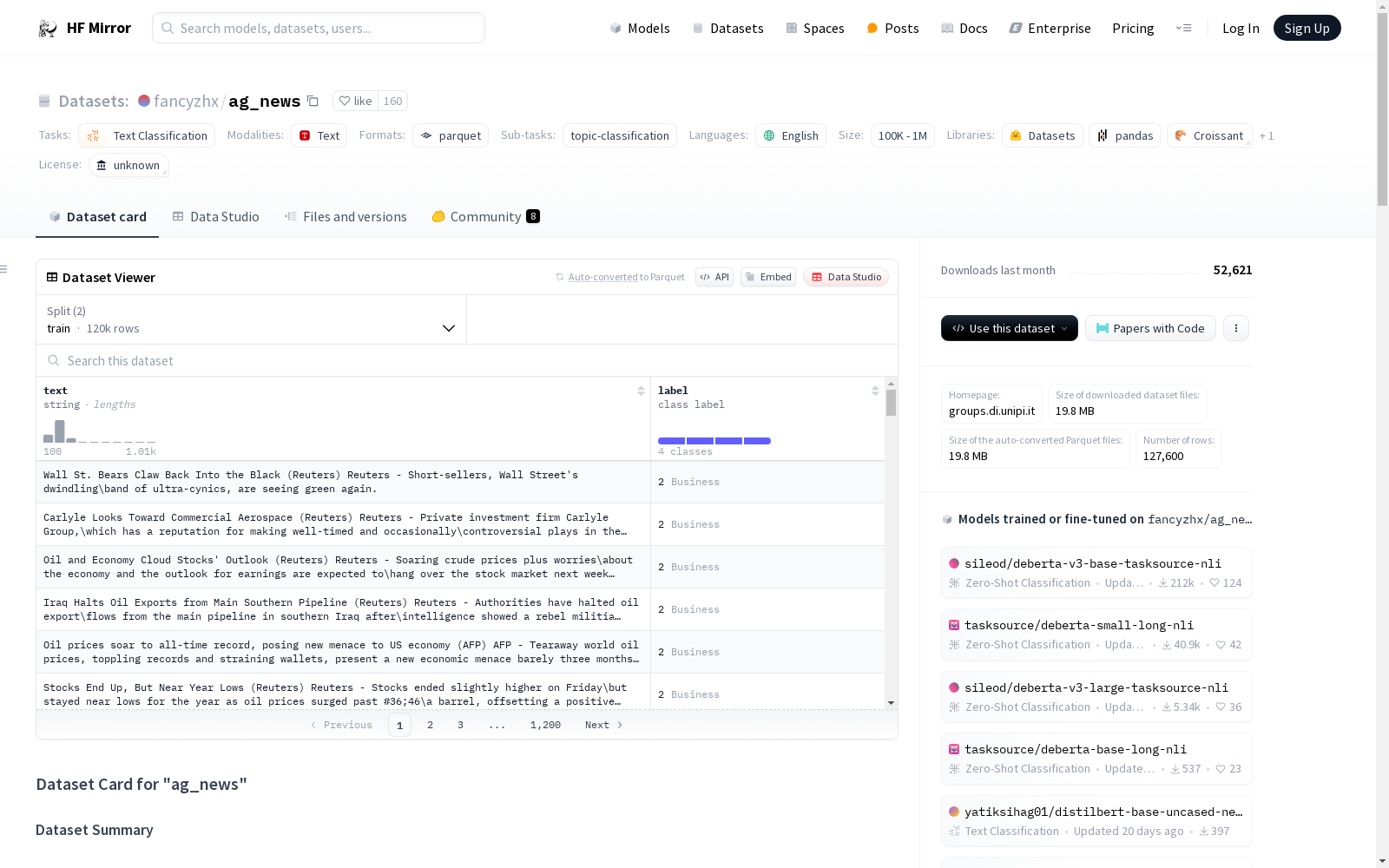
AG新闻语料库是一个包含超过100万条新闻文章的数据集,这些文章来源于2000多个新闻源,由学术新闻搜索引擎ComeToMyHead收集。该数据集由Xiang Zhang等人构建,用于文本分类基准测试,并在NIPS 2015会议上发表的论文中有所描述。数据集包含训练集和测试集,分别有120,000和7,600个样本。每个样本包含文本和标签,标签分为四类:世界、体育、商业和科技。
The AG News Corpus is a dataset containing over one million news articles sourced from more than 2,000 news outlets, collected by the academic news search engine ComeToMyHead. It was constructed by Xiang Zhang et al. for text classification benchmarking, and was described in a paper published at the NIPS 2015 conference. The dataset includes a training set and a test set, with 120,000 and 7,600 samples respectively. Each sample contains text and a label, which falls into four categories: World, Sports, Business, and Technology.
提供机构:
fancyzhx
原始信息汇总
数据集概述
- 名称: AG’s News Corpus
- 别名: ag_news
- ID: ag-news
- 语言: 英语 (en)
- 许可证: 未知
- 多语言性: 单语
- 大小: 100K<n<1M
- 来源: 原始数据
- 任务类别: 文本分类
- 任务ID: 主题分类
数据集结构
数据字段
- text: 字符串类型,文本内容。
- label: 分类标签,包括 World (0), Sports (1), Business (2), Sci/Tech (3)。
数据分割
- 训练集: 120000个样本
- 测试集: 7600个样本
评估指标
- 准确率 (Accuracy)
- F1 宏平均 (F1 macro)
- F1 微平均 (F1 micro)
- F1 加权平均 (F1 weighted)
- 精确率 宏平均 (Precision macro)
- 精确率 微平均 (Precision micro)
- 精确率 加权平均 (Precision weighted)
- 召回率 宏平均 (Recall macro)
- 召回率 微平均 (Recall micro)
- 召回率 加权平均 (Recall weighted)
搜集汇总
数据集介绍
构建方式
AG’s News Corpus数据集是由超过2000个新闻源中收集的超过100万篇新闻文章构成,这些文章由ComeToMyHead学术新闻搜索引擎在一年多的活动中搜集。数据集经过筛选和标注,形成了包含四个主题分类(世界、体育、商业、科技)的文本分类基准数据集。
特点
该数据集具有以下特点:一是数据量大,二是主题分类明确,三是文本来源多样,涵盖了不同领域的新闻内容,适合用于文本分类、信息检索、自然语言处理等研究。此外,数据集的构建旨在服务于学术研究,不含有个人敏感信息。
使用方法
使用该数据集时,用户可以根据自己的需求选择训练集和测试集。数据集以JSON格式存储,每个实例包含文本内容和对应的分类标签。用户可以采用Python等编程语言进行数据加载和预处理,进而应用机器学习模型进行文本分类任务,如使用卷积神经网络等深度学习方法。
背景与挑战
背景概述
AG’s News Corpus(AG新闻语料库)是一组由超过一百万篇新闻文章组成的文本数据集。这些新闻文章源自2000多个新闻来源,由ComeToMyHead学术新闻搜索引擎在一年多的时间里搜集而成。该搜索引擎自2004年7月起运行。该数据集由学术社区提供,主要用于数据挖掘(聚类、分类等)、信息检索(排名、搜索等)、XML、数据压缩、数据流等领域的研究。特别地,Xiang Zhang等人基于此数据集构建了AG新闻主题分类数据集,并在2015年的NIPS会议上发表了相关论文,该数据集成为了文本分类研究的基准数据集。
当前挑战
该数据集在构建和应用过程中面临的挑战包括:确保收集的新闻文章在主题分类上的广泛性和代表性;在数据标注过程中,保证标注质量的一致性和准确性;此外,由于数据集规模庞大,如何有效地进行数据压缩和存储也是一个挑战。在研究领域问题方面,AG新闻数据集解决的领域问题是文本分类,尤其是新闻文本的多类别分类问题。构建过程中的挑战还包括如何处理可能存在的数据偏差,以及如何确保数据的使用不会引发隐私和安全问题。
常用场景
经典使用场景
在文本分类研究领域,AG’s News Corpus数据集被广泛作为基准数据集使用。其包含了超过一百万篇新闻文章,涵盖世界、体育、商业和科技四大主题类别。该数据集的经典使用场景在于评估和比较不同文本分类模型的性能,尤其是字符级卷积网络在文本分类任务中的应用。
实际应用
在实际应用中,AG’s News Corpus数据集可被用于构建新闻聚合系统、智能推荐系统和内容审核系统。这些系统能够根据用户的兴趣和阅读习惯,自动分类和推送相关新闻内容,提高用户体验和信息获取的效率。
衍生相关工作
基于AG’s News Corpus数据集,已经衍生出许多经典工作,如Xiang Zhang等人提出的字符级卷积网络在文本分类中的应用,该工作在NIPS 2015上发表,并成为后续许多研究的基石。此外,该数据集也激发了关于文本表示、特征提取和模型优化等多个方面的研究探索。
以上内容由遇见数据集搜集并总结生成


