NYU VINN
收藏github2025-03-21 收录
下载链接:
https://jyopari.github.io/VINN/
下载链接
链接失效反馈官方服务:
资源简介:
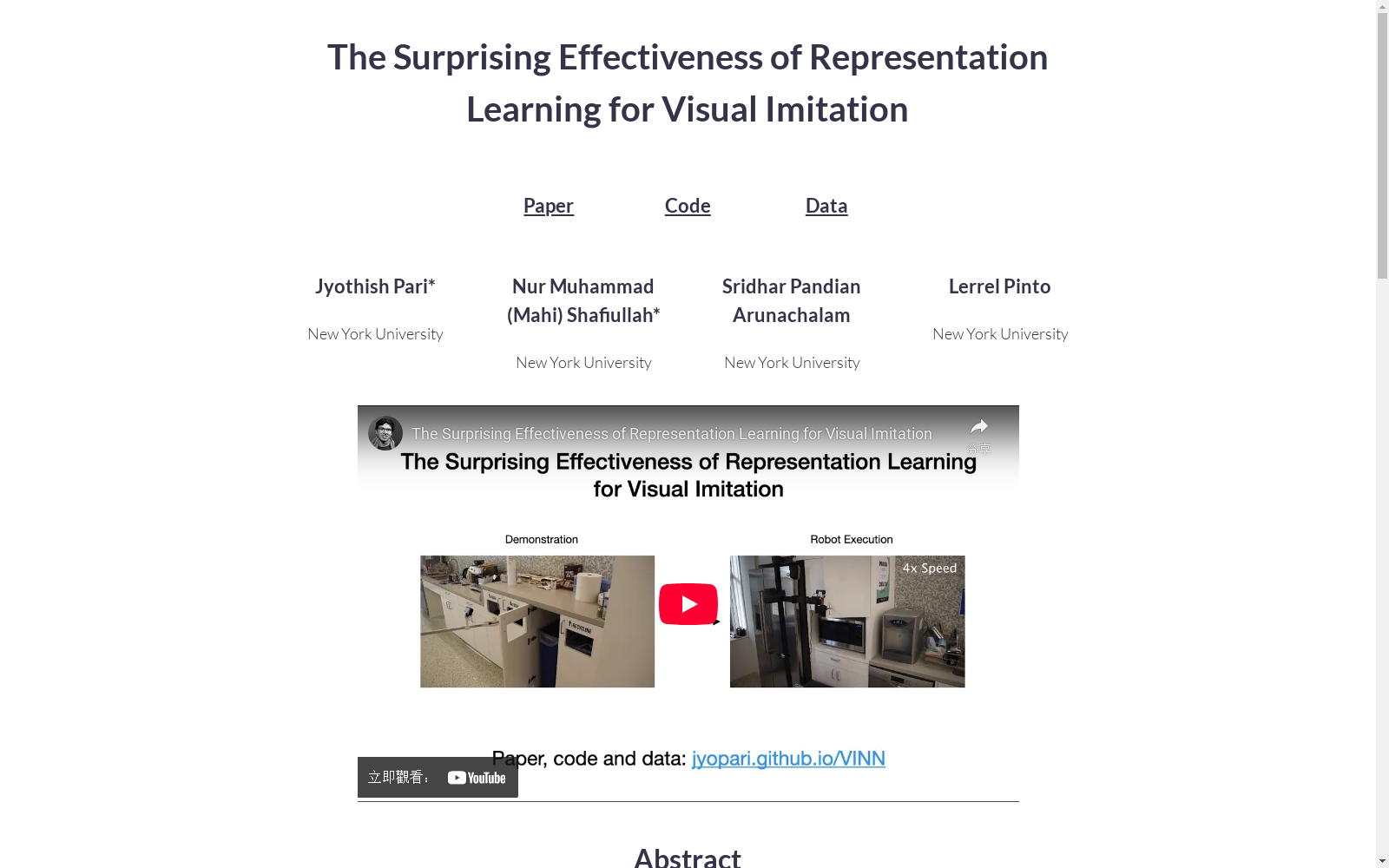
该数据集由纽约大学(NYU)的研究团队创建,旨在支持视觉模仿学习的研究。数据集包含三个主要任务的数据:推动物体、堆叠物体和打开门。其中,推动物体和堆叠物体任务的数据分别包含约 750 和 930 条演示轨迹,而打开门任务的数据包含 71 条训练演示和 21 条测试演示。数据来源为人类专家通过遥操作机器人收集的视觉演示数据,涵盖了多种背景和物体的场景。数据集的创建过程基于遥操作工具收集的视频数据,通过结构化运动(SfM)方法重建三维运动轨迹,提取动作标签。该数据集的应用领域主要集中在机器人视觉模仿学习,旨在提高机器人在复杂视觉环境中的任务执行能力,特别是在数据量有限的情况下实现更好的泛化性能。
This dataset was created by a research team at New York University (NYU) to support research in visual imitation learning. It contains data for three core tasks: object pushing, object stacking, and door opening. Specifically, the datasets for the object pushing and object stacking tasks include approximately 750 and 930 demonstration trajectories respectively, while the door opening task dataset has 71 training demonstrations and 21 test demonstrations. The data originates from visual demonstration data collected by human experts via teleoperated robots, covering scenarios with diverse backgrounds and objects. The dataset is constructed based on video data collected through teleoperation tools, where 3D motion trajectories are reconstructed and action labels are extracted using the Structure from Motion (SfM) method. The main application scope of this dataset focuses on robotic visual imitation learning, aiming to enhance robots' task execution capabilities in complex visual environments, particularly to achieve better generalization performance under limited data conditions.
提供机构:
纽约大学
搜集汇总
数据集介绍
构建方式
NYU VINN数据集的构建基于深度学习与计算机视觉领域的前沿研究需求,旨在为自动驾驶和机器人导航提供高质量的视觉惯性导航数据。该数据集通过多传感器融合技术,结合高精度IMU(惯性测量单元)和RGB-D相机,采集了丰富的室内外环境数据。数据采集过程中,研究人员精心设计了多种场景和运动模式,以确保数据的多样性和代表性。所有数据均经过严格的时间同步和空间校准,确保了数据的一致性和可靠性。
使用方法
使用NYU VINN数据集时,研究人员可通过其提供的API接口轻松加载和处理数据。数据集支持多种格式,包括图像序列、深度图和IMU数据流,便于不同研究需求的灵活应用。用户可以根据具体任务选择单模态或多模态数据,结合提供的标注信息进行算法训练和测试。此外,数据集还附带详细的文档和示例代码,帮助用户快速上手并深入理解数据结构和应用场景。
背景与挑战
背景概述
NYU VINN数据集由纽约大学的研究团队于2020年创建,旨在推动视觉与语言交互领域的研究。该数据集的核心研究问题集中在如何通过自然语言指令控制机器人执行复杂的视觉任务。研究人员通过多模态数据(包括图像、视频和文本指令)的融合,探索了机器人在真实环境中的自主决策能力。该数据集在机器人学、计算机视觉和自然语言处理领域产生了广泛影响,为多模态学习与智能交互提供了重要的实验平台。
当前挑战
NYU VINN数据集在解决视觉与语言交互问题时面临多重挑战。首先,自然语言指令的多样性和模糊性使得机器人在理解任务意图时容易产生歧义。其次,真实环境中的视觉数据往往包含噪声和复杂背景,增加了任务执行的难度。此外,数据集的构建过程中,研究人员需要协调多模态数据的采集与标注,确保数据的一致性和高质量。这些挑战不仅考验了算法的鲁棒性,也对数据集的规模和质量提出了更高要求。
常用场景
经典使用场景
NYU VINN数据集在计算机视觉领域中被广泛用于研究视频实例分割和对象跟踪。该数据集提供了丰富的视频序列和详细的标注信息,使得研究人员能够深入探索视频中对象的动态行为和交互模式。通过使用NYU VINN,研究者可以开发和测试先进的算法,以实现在复杂场景下的精确对象识别和跟踪。
解决学术问题
NYU VINN数据集解决了视频分析领域中对象实例分割和跟踪的挑战。它提供了高质量的视频数据和精确的标注,帮助研究者克服了在动态场景中对象遮挡、形变和快速运动等问题。该数据集的使用显著提升了视频分析算法的鲁棒性和准确性,推动了计算机视觉技术的发展。
实际应用
在实际应用中,NYU VINN数据集被用于开发智能监控系统、自动驾驶技术和人机交互系统。通过利用该数据集,研究人员能够训练出更加智能和高效的算法,实现对复杂环境中对象的实时监控和跟踪。这些技术在城市安全、交通管理和智能家居等领域具有广泛的应用前景。
数据集最近研究
最新研究方向
在计算机视觉与机器人领域,NYU VINN数据集的最新研究方向聚焦于视觉导航与场景理解的深度融合。随着自动驾驶和智能机器人技术的快速发展,如何使机器在复杂环境中实现高效、准确的导航成为研究热点。NYU VINN数据集通过提供丰富的室内场景图像和深度信息,支持了基于深度学习的视觉导航算法的开发与优化。近年来,研究者们利用该数据集探索了多模态感知、语义分割与路径规划的联合优化方法,显著提升了机器在动态环境中的自主决策能力。这一研究方向不仅推动了智能系统的实际应用,也为未来人机协作与智慧城市建设提供了重要技术支撑。
以上内容由遇见数据集搜集并总结生成


