AndyReas/frontpage-news
收藏Hugging Face2023-04-28 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/AndyReas/frontpage-news
下载链接
链接失效反馈官方服务:
资源简介:
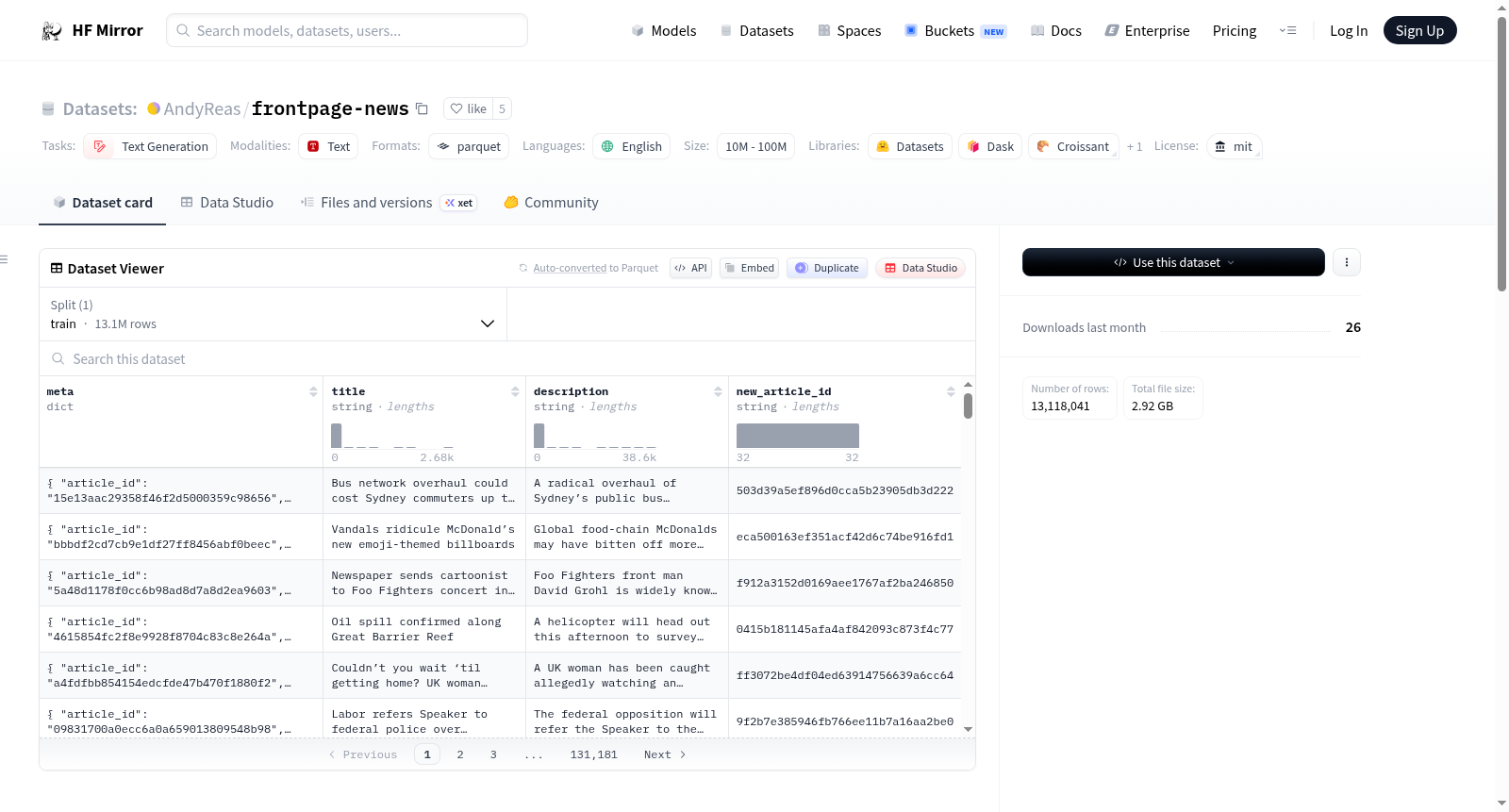
Frontpage News数据集包含约13,000,000篇英文文章,来源于约90个新闻媒体,时间跨度为2015年7月18日至2020年10月17日。数据经过多次清洗,包括去重、移除重复的媒体标签、移除非自然句子中的日期标签、移除HTML元素、替换HTML转义字符以及移除低质量文章等。尽管进行了清洗,但仍存在一些未完全清理的媒体标签和特殊字符。数据集的特征包括标题、描述、元数据(如文章ID、日期、媒体来源)以及新的文章ID。
Frontpage News数据集包含约13,000,000篇英文文章,来源于约90个新闻媒体,时间跨度为2015年7月18日至2020年10月17日。数据经过多次清洗,包括去重、移除重复的媒体标签、移除非自然句子中的日期标签、移除HTML元素、替换HTML转义字符以及移除低质量文章等。尽管进行了清洗,但仍存在一些未完全清理的媒体标签和特殊字符。数据集的特征包括标题、描述、元数据(如文章ID、日期、媒体来源)以及新的文章ID。
提供机构:
AndyReas
原始信息汇总
数据集概述
数据来源
- 数据集包含约13,000,000篇英文文章,来源于约90个新闻出口。
- 文章收集自Sciride News Mine,并经过额外的清洗和处理。
- 文章时间跨度为2015-07-18至2020-10-17。
数据处理
- 移除重复文章。
- 移除重复的“出口标签”。
- 移除非自然句子部分的日期。
- 移除因日期导致重复的文章。
- 移除遗漏的HTML元素。
- 将HTML字符替换为常规字符。
- 移除“垃圾”文章,如空文章或长度低于特定阈值的文章。
数据集特征(列)
- title: 新闻标题。
- description: 新闻副标题。
- meta:
- article_id: 原始Sciride新闻矿的文章ID,由原始标题和描述哈希生成。
- date: 文章出现在首页的日期。
- outlet: 发布文章的新闻出口。
- new_article_id: 新的文章ID,由标题和描述哈希生成,可能与article_id不同,因为清洗过程中标题和描述可能发生改变。
数据集规模
- 数据集大小:10M<n<100M。
语言
- 英语。
许可证
- MIT许可证。
任务类别
- 文本生成。
搜集汇总
数据集介绍
构建方式
在新闻文本挖掘领域,大规模语料库的构建需兼顾广度与质量。Frontpage News数据集源自Sciride新闻挖掘项目,涵盖2015年至2020年间约90家主流英文媒体的1300万篇头条新闻。通过多阶段清洗流程,系统剔除了重复条目、非语义日期标签及残留HTML元素,并对特殊字符进行标准化处理,旨在提升文本的纯净度与一致性,为自然语言处理任务提供结构化基础。
特点
该数据集以时间跨度为脉络,覆盖政治、经济、文化等多领域新闻,呈现全球媒体视角的多样性。其核心特征在于每篇新闻均包含标题、摘要及元数据(如媒体来源、日期及唯一标识符),且经过去重与清洗,有效减少了噪声干扰。尽管清洗过程未能完全消除部分媒体标签或特殊字符残留,但整体结构清晰、字段完整,为研究媒体叙事演变、信息传播模式提供了高颗粒度的文本资源。
使用方法
Frontpage News适用于文本生成、时序分析与媒体研究等任务。使用者可通过标题与摘要字段训练摘要生成模型,或利用元数据中的时间与媒体标签进行跨周期、跨机构的对比分析。数据以标准表格形式组织,支持直接加载至主流机器学习框架。需注意部分残留噪声可能影响分词效果,建议在使用前根据具体任务进行针对性预处理,以充分发挥其大规模语料的价值。
背景与挑战
背景概述
在数字新闻学与自然语言处理领域,大规模新闻语料库的构建对于推动文本生成、内容分析及媒体研究具有关键意义。Frontpage News数据集由AndyReas于2020年发布,汇集了2015年至2020年间来自约90家英语新闻媒体的1300万篇头条新闻文章。该数据集源自Sciride News Mine项目,经过系统清洗与处理,旨在为研究者提供高质量、跨平台的新闻文本资源,以支持新闻趋势分析、自动摘要生成及媒体偏见检测等核心研究问题,对计算新闻学与语言模型训练产生了深远影响。
当前挑战
Frontpage News数据集致力于解决新闻文本生成与内容理解中的挑战,包括跨媒体风格差异、时间动态建模及信息冗余问题。在构建过程中,数据清洗面临多重困难:重复文章的识别与去除因日期标签变异而复杂化;HTML元素残留与特殊字符编码错误导致文本标准化不足;不同媒体机构的版面标签格式不一致,如“|”与“--”的混用,影响了元数据的纯净性。这些未完全解决的清理问题可能对下游任务的模型性能构成潜在限制。
常用场景
经典使用场景
在自然语言处理领域,大规模新闻文本数据集为模型训练提供了丰富的语料资源。Frontpage News数据集以其涵盖2015年至2020年间约1300万篇英文新闻文章的规模,成为文本生成任务中的经典基准。该数据集经过精细的去重和清洗处理,确保了语料质量,特别适用于训练语言模型学习新闻标题与内容的关联性,以及捕捉不同媒体机构的写作风格和叙事模式。
衍生相关工作
围绕该数据集衍生的经典工作包括基于Transformer架构的新闻标题生成模型、跨媒体对比学习框架以及时序感知的文本表示研究。例如,部分研究利用其元数据探索媒体偏见量化方法,另一些工作则结合文章日期与来源信息构建事件演化图谱。这些成果不仅推动了自然语言处理技术的进步,也为数字人文研究提供了方法论借鉴。
数据集最近研究
最新研究方向
在新闻媒体与自然语言处理交叉领域,Frontpage News数据集凭借其涵盖2015至2020年间约1300万篇英文新闻文章的规模,正成为前沿研究的重要资源。该数据集整合了来自全球约90家主流媒体的头条新闻,经过清洗处理,为分析新闻传播动态、媒体偏见及叙事演变提供了丰富语料。当前研究热点聚焦于利用该数据集训练大规模语言模型,以提升新闻摘要生成、事实核查及多源信息融合的准确性,同时探索跨媒体、跨时间维度的舆情模式识别,助力虚假新闻检测和媒体公信力评估。这些进展不仅推动了计算新闻学的发展,也为信息生态治理提供了数据驱动的洞察。
以上内容由遇见数据集搜集并总结生成


