Synthetic-Diabetes-Dataset
收藏Hugging Face2025-11-24 更新2025-11-25 收录
下载链接:
https://huggingface.co/datasets/MaxPrestige/Synthetic-Diabetes-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
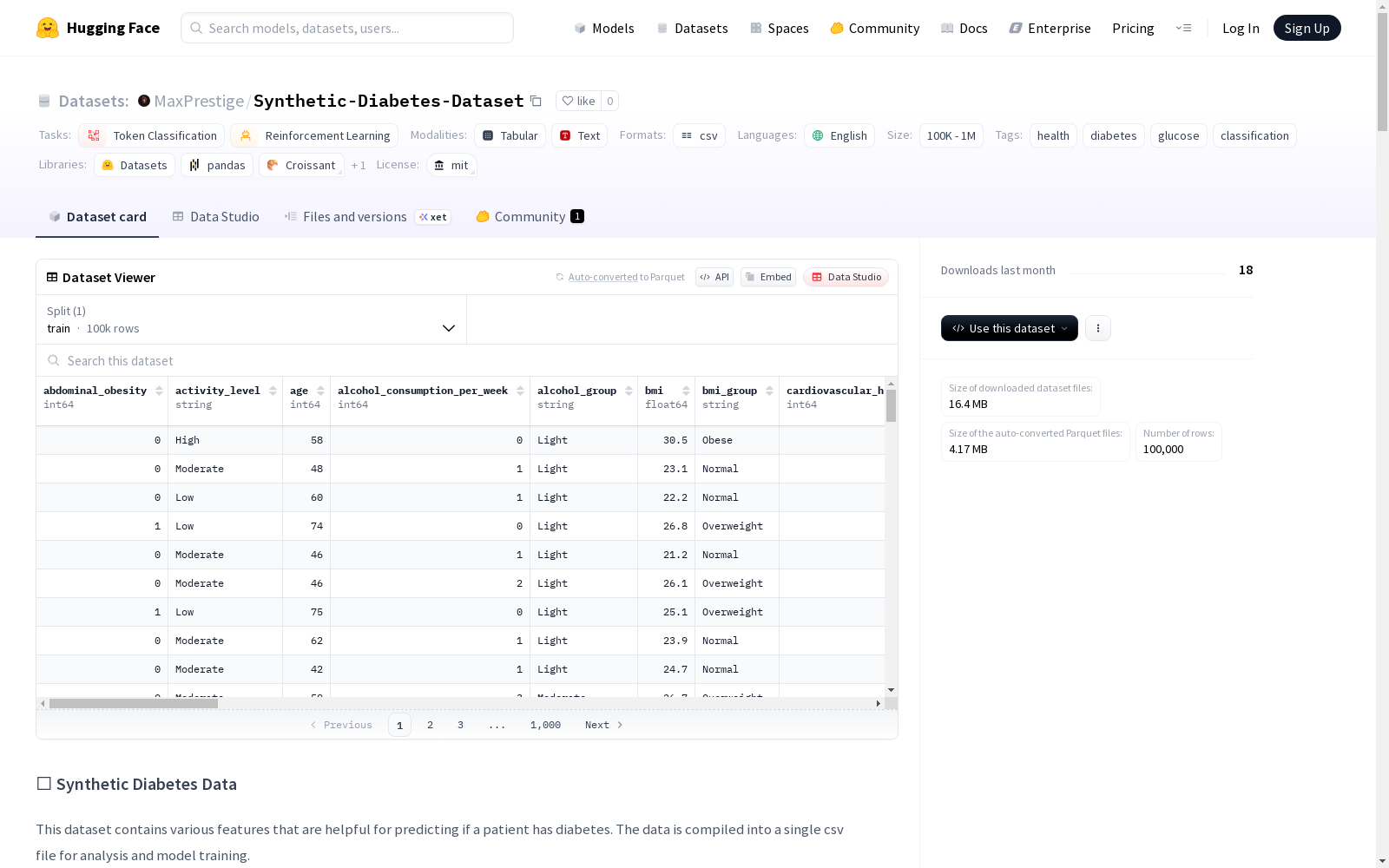
这是一个包含合成病人信息的糖尿病数据集,包含有助于预测病人是否患有糖尿病的各种特征。数据集以单个csv文件的形式编译,用于分析和模型训练。
创建时间:
2025-11-21
原始信息汇总
数据集概述
基本信息
- 数据集名称: Synthetic Diabetes Data
- 许可证: MIT
- 任务类别: 词分类、强化学习
- 语言: 英语
- 标签: 健康、糖尿病、血糖、分类
- 数据规模: 1万-10万条
数据集描述
包含基于合成患者信息的糖尿病预测数据,编译为单个CSV文件用于分析和模型训练。
数据列说明
人口统计学特征
- gender: 患者性别
- ethnicity: 患者种族
- education_level: 教育水平
- employment_status: 就业状况
- income_level: 收入水平
生理指标
- bmi: 身体质量指数
- bmi_group: BMI分类
- abdominal_obesity: 腹部肥胖
- waist_to_hip_ratio: 腰臀比
- systolic_bp: 收缩压
- diastolic_bp: 舒张压
- heart_rate: 心率
- sleep_hours_per_day: 每日睡眠时长
血液检测指标
- glucose_fasting: 空腹血糖
- glucose_postprandial: 餐后血糖
- hba1c: 糖化血红蛋白
- insulin_level: 胰岛素水平
- cholesterol_total: 总胆固醇
- hdl_cholesterol: 高密度脂蛋白胆固醇
- ldl_cholesterol: 低密度脂蛋白胆固醇
- triglycerides: 甘油三酯
生活习惯
- alcohol_consumption_per_week: 每周酒精摄入量
- alcohol_group: 酒精摄入分类
- physical_activity_minutes_per_week: 每周运动时长
- screen_time_hours_per_day: 每日屏幕使用时间
- smoking_status: 吸烟状况
病史与风险因素
- family_history_diabetes: 糖尿病家族史
- cardiovascular_history: 心血管病史
- hypertension_history: 高血压病史
- diabetes_risk_score: 糖尿病风险评分
- diabetes_stage: 糖尿病阶段
目标变量
- diagnosed_diabetes: 糖尿病诊断标签
数据来源
数据来源于: https://huggingface.co/datasets/guyshilo12/diabetes_eda_analysis
搜集汇总
数据集介绍
构建方式
在糖尿病研究领域,合成数据生成技术为模型训练提供了可控且多样化的样本基础。该数据集通过算法模拟生成虚拟患者记录,涵盖生理指标、生活习惯及社会人口学特征等多维度变量。构建过程中严格参照临床医学标准设定参数范围,例如血糖阈值与血脂分类标准,确保生成数据的医学合理性。数据以结构化CSV格式存储,每条记录包含30个特征字段,为机器学习任务提供完整的特征矩阵。
特点
本数据集的核心价值在于其全面覆盖糖尿病相关的生物标记物与风险因子。除基础的空腹血糖和糖化血红蛋白等诊断指标外,创新性地纳入了胰岛素水平动态变化、酒精摄入分组等精细化特征。数据呈现典型的医疗数据集不平衡特性,包含连续型数值变量与分类型序变量的混合分布。特别值得注意的是,所有特征均附带临床医学注释,如胆固醇理想值范围与血压测量意义,为研究者提供专业背景支持。
使用方法
针对机器学习应用场景,该数据集可直接用于分类模型构建与特征重要性分析。建议将'diagnosed_diabetes'列设为预测目标,其余特征作为输入变量。在预处理阶段需注意处理分类变量的编码转换,并对连续型特征进行标准化处理。研究者可基于该数据开发糖尿病早期筛查模型,或通过强化学习探索个性化干预策略。数据集的合成特性使其特别适合用于模型原型开发与算法验证,规避真实医疗数据使用的隐私合规限制。
背景与挑战
背景概述
在糖尿病研究领域,数据驱动的预测模型对早期筛查和风险评估具有重要价值。Synthetic-Diabetes-Dataset作为合成医疗数据集,整合了包括血糖指标、血脂参数、生活习惯等多维度临床特征,通过结构化数据呈现糖尿病相关的生理与行为学标记。该数据集由研究团队基于真实临床参数生成,旨在构建可公开共享的标准化基准数据,为机器学习在慢性病预测领域的应用提供支持。其涵盖的糖化血红蛋白、胰岛素水平等核心生物标志物,反映了当代糖尿病研究对代谢综合征多因素交互作用的深入探索。
当前挑战
糖尿病预测领域面临高维度异质性数据整合的挑战,需平衡临床指标与行为特征的关联性。数据集构建过程中需克服真实患者数据隐私保护与合成数据真实性的矛盾,确保生成的空腹血糖、血脂分型等参数符合医学参考范围。多源特征如心血管病史与睡眠时长等非传统因素的耦合关系,对模型表征能力提出更高要求。合成数据还需解决类别不平衡与时间动态性缺失的问题,避免简化疾病进展的阶段性特征。
常用场景
经典使用场景
在糖尿病研究领域,Synthetic-Diabetes-Dataset通过整合血糖指标、血脂参数及生活方式等多维特征,为机器学习模型构建提供了标准化数据基础。该数据集常被用于训练分类算法,以识别糖尿病风险人群,其结构化特征设计支持从传统逻辑回归到深度神经网络等多种建模方法,有效促进了疾病预测模型的开发与验证。
实际应用
医疗健康机构可借助该数据集构建临床决策支持系统,通过实时分析患者的BMI、血脂谱等参数实现糖尿病风险预警。公共卫生部门则能利用其社会人口学特征,精准定位高危群体并制定针对性干预方案,最终优化医疗资源配置与慢性病管理效能。
衍生相关工作
基于该数据集衍生的经典研究包括融合强化学习的动态风险评估框架,以及结合图神经网络的多指标关联分析模型。这些工作通过挖掘特征间的潜在交互关系,不仅提升了预测精度,还推动了可解释人工智能在医疗诊断领域的应用深化。
以上内容由遇见数据集搜集并总结生成


