ICE-Bench
收藏arXiv2025-03-19 更新2025-03-20 收录
下载链接:
https://ali-vilab.github.io/ICE-Bench-Page/
下载链接
链接失效反馈官方服务:
资源简介:
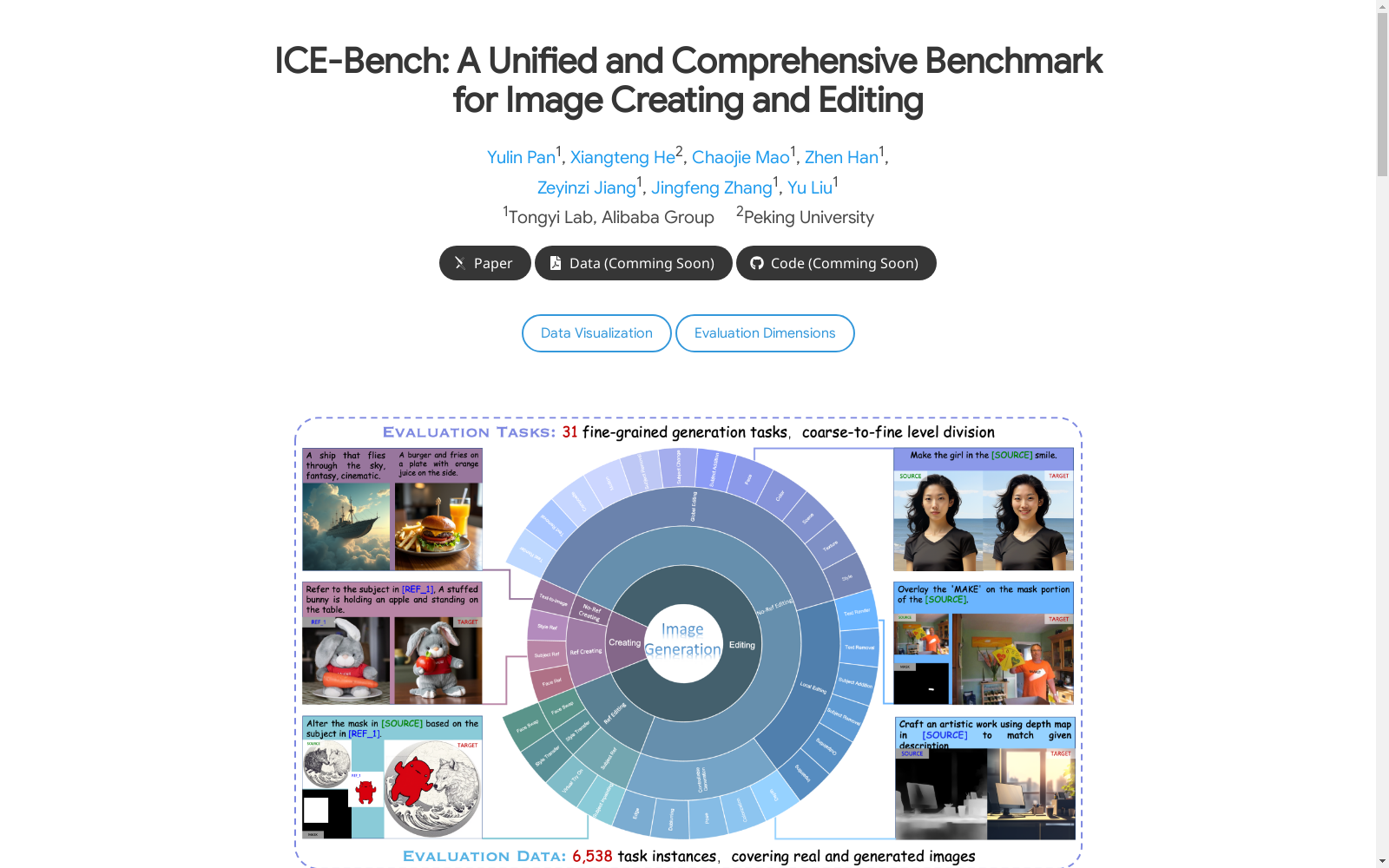
ICE-Bench是由阿里巴巴集团推出的统一和全面的图像生成评估基准。该数据集涵盖了31个细粒度的生成任务,分为无参考/有参考的图像创建/编辑四大类别,旨在全面评估图像生成模型的能力。数据集由真实场景和虚拟生成的图像混合构成,有效提高了数据多样性,减轻了模型评估中的偏差问题。它包含了6538个任务实例,旨在解决图像生成模型自动评估的挑战,推动该领域的研究进展。
ICE-Bench is a unified and comprehensive image generation evaluation benchmark launched by Alibaba Group. This dataset encompasses 31 fine-grained generation tasks, categorized into four groups: reference-free and reference-based image creation and editing, with the goal of comprehensively evaluating the capabilities of image generation models. The dataset comprises a mix of real-world scenes and virtually generated images, effectively boosting data diversity and mitigating bias issues in model evaluation. It contains 6538 task instances, aiming to address the challenges of automatic evaluation of image generation models and advance research progress in this field.
提供机构:
阿里巴巴集团
创建时间:
2025-03-19
搜集汇总
数据集介绍
构建方式
ICE-Bench数据集的构建过程结合了大规模预训练模型与人工标注的协同工作。首先,从混合数据源(如MSCOCO、LAION-5B等)中手动选择源图像和参考图像,随后利用大语言模型(VLLM)生成图像描述和任务特定的指令模板。在此基础上,标注人员根据源图像和参考图像,结合指令模板,为每个案例生成独特的指令。最后,通过VLLM生成理想目标图像的详细描述。整个数据集包含6,538个任务实例,涵盖了真实和生成图像,确保了数据的多样性和评估的全面性。
使用方法
ICE-Bench数据集的使用方法主要围绕其多层次任务和多维度评估展开。研究人员可以通过该数据集对图像生成模型进行细粒度任务评估,涵盖从文本到图像生成到复杂图像编辑的多种场景。评估时,模型的表现将通过6个维度的11个指标进行量化,包括美学质量、成像质量、提示跟随、源一致性、参考一致性和可控性。数据集还提供了详细的评估脚本和模型,支持自动化的评估流程。通过ICE-Bench,研究人员可以全面分析现有模型的生成能力,识别其在不同任务和维度上的优势与不足,从而推动图像生成技术的进一步发展。
背景与挑战
背景概述
ICE-Bench是由阿里巴巴集团通义实验室与北京大学的研究团队于2025年提出的一个统一且全面的图像生成与编辑基准测试。该基准测试旨在解决当前图像生成模型评估中的诸多挑战,特别是在多模态引导下的图像生成任务中。ICE-Bench通过系统化的任务分解,将图像生成能力划分为31个细粒度任务,涵盖了从无参考图像生成到基于参考图像的编辑等多种复杂场景。其核心研究问题在于如何全面评估图像生成模型在美学质量、成像质量、提示跟随、源一致性、参考一致性和可控性等多个维度上的表现。ICE-Bench的提出为图像生成领域的研究提供了新的评估标准,推动了该领域的技术进步。
当前挑战
ICE-Bench面临的挑战主要体现在两个方面。首先,图像生成与编辑任务的复杂性使得模型在生成高质量图像时,必须同时满足多个约束条件,如美学要求、提示的精确跟随以及源图像与参考图像的一致性。这种多目标优化问题使得模型在生成过程中难以平衡各项指标,尤其是在处理复杂场景或高分辨率图像时,模型的表现往往不尽如人意。其次,数据集的构建过程也面临巨大挑战。为了确保数据的多样性和代表性,ICE-Bench采用了混合数据源,包括真实场景和虚拟生成图像。然而,如何确保这些数据的质量、避免偏差,并在大规模任务中保持数据的一致性,仍然是一个亟待解决的问题。此外,评估指标的设计也需要兼顾自动化与人类主观评价之间的平衡,以确保评估结果的客观性和可靠性。
常用场景
经典使用场景
ICE-Bench作为一个统一的图像生成与编辑基准,广泛应用于评估生成模型在多种任务中的表现。其经典使用场景包括从文本到图像的生成、基于参考图像的风格迁移、局部编辑(如修复、扩展)以及全局编辑(如颜色调整、场景变换)。通过31个细粒度任务的划分,ICE-Bench能够全面覆盖图像生成与编辑的多样化需求,为研究人员提供了一个标准化的评估平台。
解决学术问题
ICE-Bench解决了图像生成领域中的多个关键学术问题。首先,它通过引入多维度评估指标(如美学质量、成像质量、提示跟随、源一致性、参考一致性和可控性),弥补了现有评估框架的不足。其次,ICE-Bench通过混合数据(真实场景与虚拟生成图像)提升了数据多样性,减少了模型评估中的偏差问题。此外,其细粒度任务划分和多维度评估方法为生成模型的改进提供了明确的方向,推动了图像生成技术的进一步发展。
实际应用
在实际应用中,ICE-Bench为图像生成与编辑技术的落地提供了重要支持。例如,在广告设计领域,ICE-Bench可以用于评估生成模型在风格迁移和局部编辑任务中的表现,帮助设计师快速生成符合需求的图像。在虚拟试衣和虚拟现实场景中,ICE-Bench的参考一致性评估能力能够确保生成图像与参考图像的高度一致,提升用户体验。此外,ICE-Bench还可用于图像修复、去模糊等实际任务,为图像处理技术的优化提供数据支持。
数据集最近研究
最新研究方向
近年来,图像生成领域取得了显著进展,尤其是在生成对抗网络(GANs)、变分自编码器(VAEs)和扩散模型(Diffusion Models)等技术的推动下。然而,如何全面评估图像生成模型的性能仍然是一个重大挑战。为此,ICE-Bench应运而生,作为一个统一且全面的基准测试工具,旨在通过31个细粒度的生成任务和多维度的评估指标,系统评估图像生成模型的能力。ICE-Bench不仅涵盖了从无参考图像生成到基于参考的图像编辑的广泛任务,还引入了11个评估指标,包括美学质量、成像质量、提示跟随、源一致性、参考一致性和可控性等维度。特别是,ICE-Bench引入了VLLM-QA这一创新指标,利用大语言模型评估图像编辑的成功率。此外,ICE-Bench的数据集结合了真实场景和虚拟生成图像,有效提升了数据多样性,缓解了模型评估中的偏差问题。通过ICE-Bench,研究人员能够更全面地分析现有生成模型的优缺点,推动图像生成技术的进一步发展。
相关研究论文
- 1ICE-Bench: A Unified and Comprehensive Benchmark for Image Creating and Editing阿里巴巴集团 · 2025年
以上内容由遇见数据集搜集并总结生成


