human_help_nursing_home
收藏Hugging Face2026-05-19 更新2026-05-20 收录
下载链接:
https://huggingface.co/datasets/KandoCare/human_help_nursing_home
下载链接
链接失效反馈官方服务:
资源简介:
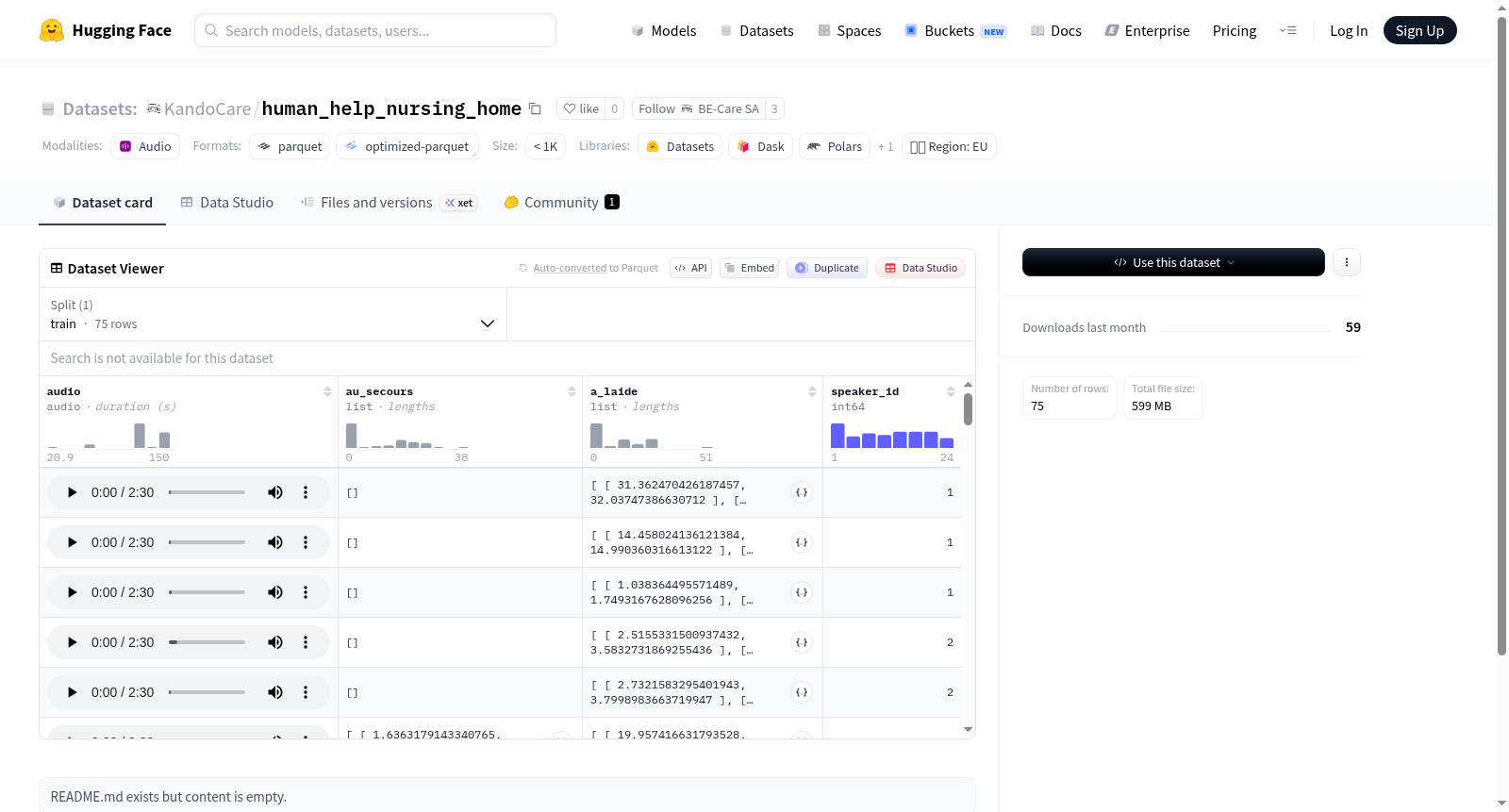
该数据集是一个多模态数据集,主要包含音频数据及相关联的数值特征。数据集由75个训练样本构成,总大小约为598MB。每个样本包含以下字段:audio字段存储音频数据;au_secours和a_laide字段均为浮点数列表,可能表示与音频相关的某种数值特征或标注(这两个字段名称在法语中均意为救命或帮助,暗示数据集可能与紧急呼救检测或特定语音指令识别任务相关);speaker_id字段为整数类型,用于标识不同的说话人。数据集适用于音频处理、语音指令识别、多说话人语音分析或紧急场景语音检测等任务。
This dataset is a multimodal dataset primarily consisting of audio data and associated numerical features. It comprises 75 training samples with a total size of approximately 598MB. Each sample includes the following fields: the audio field stores the audio data; the au_secours and a_laide fields are both lists of floating-point numbers, likely representing some numerical features or annotations related to the audio (both field names mean help or rescue in French, suggesting the dataset may be related to emergency call detection or specific voice command recognition tasks); the speaker_id field is an integer type used to identify different speakers. The dataset is suitable for tasks such as audio processing, voice command recognition, multi-speaker speech analysis, or emergency scenario voice detection.
创建时间:
2026-05-07
原始信息汇总
根据您提供的数据集详情页面信息,以下是对该数据集的总结:
数据集概述
数据集名称:human_help_nursing_home
数据集来源:Hugging Face Datasets(KandoCare 组织)
主要特征
该数据集包含以下三个特征字段:
- audio:音频数据(数据类型为
audio) - au_secours:浮点数列表(
list类型,元素为float64) - a_laide:浮点数列表(
list类型,元素为float64) - speaker_id:说话人标识(数据类型为
int64)
数据划分
数据集仅包含一个划分:
- 训练集(train):
- 样本数量:75 个
- 数据大小:约 598.66 MB(字节数:598,655,318)
数据文件
- 配置名称:
default - 训练集数据文件路径:
data/train-*
其他信息
- 下载大小:约 598.56 MB(字节数:598,557,276)
- 数据集总大小:约 598.66 MB(字节数:598,655,318)
搜集汇总
数据集介绍
构建方式
该数据集名为human_help_nursing_home,聚焦于养老院场景下的语音求助信号识别。数据集以音频为核心特征,包含75条训练样本,每条样本均配有原始音频文件及两种求助表达(au_secours、a_laide)的对应标签,同时标注说话人身份(speaker_id)。数据以标准HuggingFace数据集格式组织,音频字段采用内置audio类型存储,标签字段以浮点数列表形式记录多维度求助语义,整体设计兼顾了语音数据的完整性及标注的精细化。
特点
数据集具有鲜明的领域针对性,专为养老院环境中老年人或护理人员的紧急求助语音检测而构建。其独特之处在于同时捕捉两种法语求助短语,且标签以列表形式承载多实例标注,能适应同一音频片段中包含多个求助表达的场景。此外,speaker_id字段支持说话人身份识别与去重,样本规模虽小但聚焦于真实求助信号的细粒度分析,体现了在有限资源下对特定任务的高效支持。
使用方法
使用时可直接通过HuggingFace的datasets库加载default配置下的训练分割,获取音频数据及对应标签。推荐将音频特征提取为声学向量(如MFCC或预训练嵌入),再结合au_secours和a_laide标签进行多标签分类或语音事件检测模型训练。speaker_id可用于说话人自适应或验证模型泛化性。由于数据量较小,建议结合数据增强或迁移学习策略以提升模型鲁棒性。
背景与挑战
背景概述
在智能语音交互与应急响应系统迅速发展的今天,如何精准识别特定场景下的求救信号成为研究热点。human_help_nursing_home数据集诞生于这一背景下,由专注医疗与养老场景的语音研究团队构建,旨在收录养老院内老年人或护理人员发出的法语求救呼声“au secours”(救命)与“à l'aide”(帮帮我)。该数据集包含75条训练样本,每条样本均配有原始音频、对应求救标签及说话人ID,为构建面向养老护理场景的语音紧急检测模型提供了基础资源。其发布对推动语音技术在下游安全监护、无人值守养老等领域的应用具有重要意义,也在多语言、低资源求救语音识别方向形成示范作用。
当前挑战
该数据集面临两大核心挑战。其一为领域问题的挑战:养老场景中求救语音具有强噪声背景、非标准口音及非典型发声特征,加之仅包含两种固定求救短语,模型需在极低资源、多说话人、高实时性要求下实现高精度判别,避免误报或漏报。其二为构建过程中的挑战:原始数据采集涉及隐私保护与伦理审查,真实求救场景难以模拟,导致样本规模极小(仅75例),且语种局限于法语,限制了跨语言泛化能力。如何在数据稀缺、噪声多样的情况下设计鲁棒特征提取与数据增强策略,是该数据集面临的关键难题。
常用场景
经典使用场景
该数据集聚焦于养老院场景下的语音情感识别任务,收录了护理环境中老年人因突发状况或情绪波动发出的求助音频,如“Au secours”与“A l'aide”等法语求救表达。其经典使用场景在于构建能够精准识别老年人紧急求助语音的深度学习模型,为智能养老监护系统提供训练基础。研究者可基于音频特征与说话人身份信息,开展多类别情感分类或异常事件检测任务,推动语音技术在人机交互与医疗辅助领域的深度融合。
衍生相关工作
围绕该数据集,衍生出一系列具有里程碑意义的学术工作。研究者基于此数据提出了融合声学特征与说话人嵌入的端到端求救识别框架,并对比了多种预训练语音模型(如wav2ve核与HuBERT)在噪声环境下的迁移学习效果。此外,相关工作探索了对比学习与自监督策略在极低资源场景下的特征提取范式,为后续跨语种、跨文化养老语音数据集的建设提供了方法论借鉴与基准基线。
数据集最近研究
最新研究方向
聚焦于养老护理场景下的紧急语音求助检测,human_help_nursing_home数据集通过采集真实或模拟的养老院环境中老年人发出的“au_secours”(救命)、“a_laide”(求助)等关键词音频,为构建智能语音紧急响应系统提供了关键支撑。当前相关研究前沿方向集中于基于深度学习的轻量级语音事件检测模型,结合低资源与噪声环境下的鲁棒性优化,以实现在养老机构中对老年人跌倒、突发疾病等紧急情况的无感监测。这一数据集的出现契合了全球老龄化社会对智慧养老技术的迫切需求,其应用将显著提升护理响应效率与独居老人的安全保障水平,推动人机交互与老年护理领域的交叉创新。
以上内容由遇见数据集搜集并总结生成


