anv_data_ke
收藏Hugging Face2025-08-08 更新2025-08-09 收录
下载链接:
https://huggingface.co/datasets/MCAA1-MSU/anv_data_ke
下载链接
链接失效反馈官方服务:
资源简介:
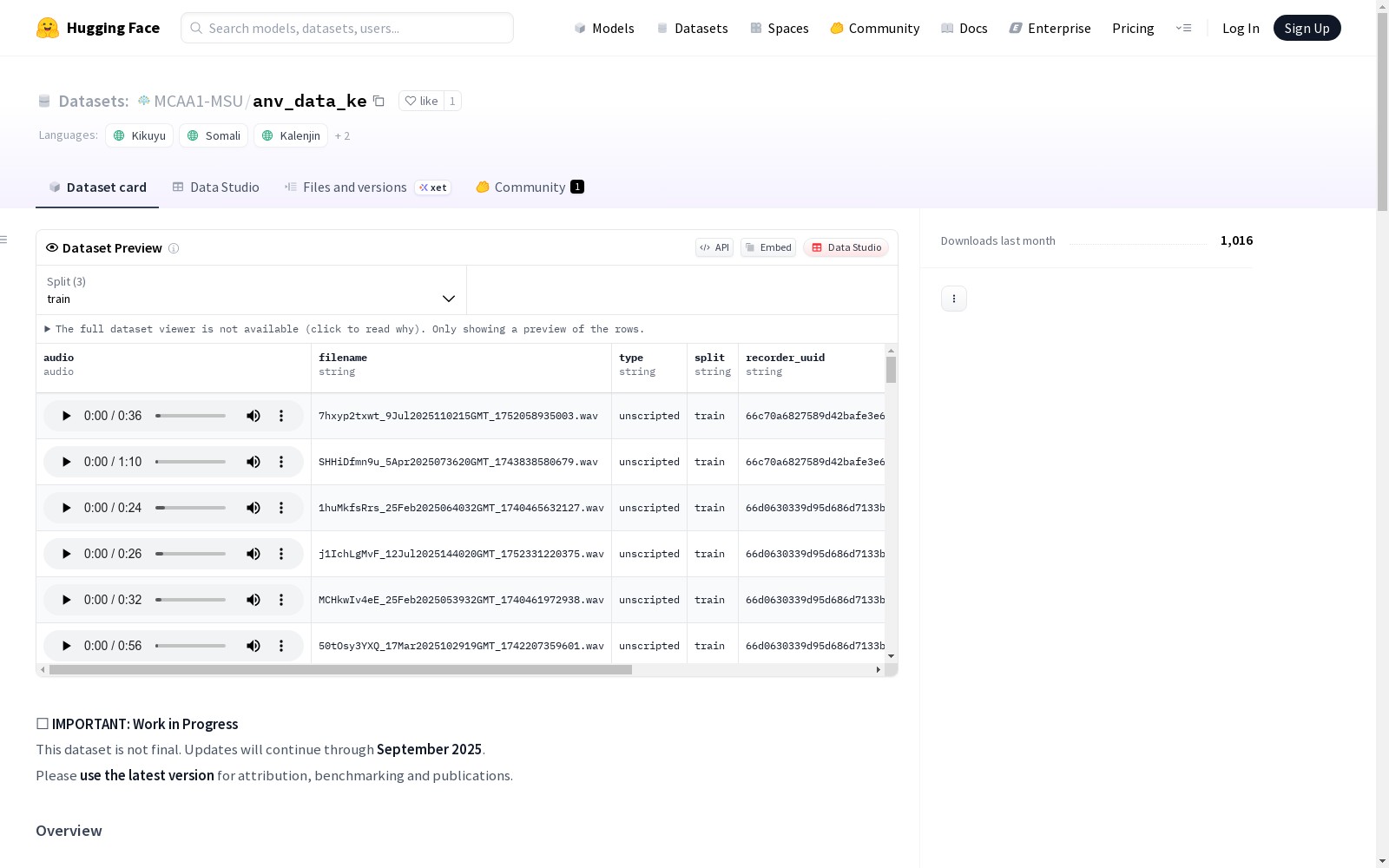
非洲下一个声音:肯尼亚初步数据收集是一个支持非洲语言语音技术的大型倡议的一部分。该项目由盖茨基金会资助,由肯尼亚大学和研究中心组成的KenCorpus联盟领导。数据集包括多种领域下,经过伦理、社区主导的过程收集的脚本化和非脚本化语音,涵盖了五种语言。数据集分为训练集、开发集、开发测试集和测试集,以确保公平的基准测试并最小化数据泄露的风险。
创建时间:
2025-08-05
原始信息汇总
数据集概述:African Next Voices - 肯尼亚试点数据收集
基本信息
- 名称:African Next Voices: Pilot Data Collection in Kenya
- 语言:Kikuyu (
ki), Somali (so), Kalenjin (kln), Dholuo (luo), Maasai (mas) - 状态:进行中(持续更新至2025年9月)
- 许可证:CC BY 4.0
项目背景
- 资助方:盖茨基金会
- 主导机构:KenCorpus Consortium(肯尼亚高校与研究中心的联盟)
数据内容
- 类型:脚本化与非脚本化语音
- 采集方式:通过符合伦理的社区主导流程收集
贡献机构
- Maseno University:Dholuo & Somali
- USIU-Africa:Maasai
- Kabarak University:Kalenjin
- DeKUT and LDRI:Kikuyu
领域覆盖
- 农业与食品
- 日常场景
- 金融交易
- 数字政府服务
- 命名实体识别
- 角色扮演
- 即兴故事
- 医疗保健
- 新闻与媒体
- 教育与技术
- 客户服务场景
应用场景
- 训练自动语音识别(ASR)模型
- 本地语言研究
- 多语言与低资源语音的基准测试
语言详情
| 语言 | 方言 | ISO | 目标小时数 | 已更新小时数 | 更新百分比 |
|---|---|---|---|---|---|
| Dholuo | Nyandwat & Milambo | luo |
750 | 0 | 0% |
| Kikuyu | Gĩ-Kabete, Ki-Mathira, Ki-Muranga, Ki-Ndia & Gĩ-Gichugu | kik |
750 | 0 | 0% |
| Somali | Maxatire | som |
500 | 312 | 62% |
| Kalenjin | Nandi & Kipsigis | kln |
500 | 218 | 43% |
| Maasai | Kimasaai & Kisamburu | mas |
500 | 0 | 0% |
数据集划分
- 训练集:85%
- 开发集:5%
- 开发测试集:5%
- 测试集:5%(保留用于未来的公共排行榜和共享任务)
数据列描述
| 列名 | 描述 |
|---|---|
mediaPathId |
音频文件路径的唯一标识符 |
recorder_uuid |
说话者或贡献者的唯一ID |
domain |
内容领域或主题类别(如医疗保健、农业) |
translatedText |
脚本化语音的英语翻译 |
actualSentence |
脚本化语音的原始本地语言表达 |
duration |
音频长度(秒) |
sentenceSource |
句子的来源 |
language |
表达的语言(如Dholuo、Kikuyu) |
sentenceDialect |
表达中使用的特定方言变体 |
type |
布尔标志,指示表达是否为脚本化 |
transcript |
非脚本化语音的文本转录 |
prompt type |
用于生成非脚本化语音的提示 |
引用格式
bibtex @misc{africannextvoiceske2025, title = {African Next Voices: Pilot Data Collection in Kenya}, author = {KenCorpus Consortium}, year = {2025}, note = {Work in Progress. XX.}, url = {xx} }
免责声明
本数据集仅供研究和开发ASR及相关技术使用。任何用于监视、歧视、剥削或不道德剖析的使用均被严格禁止。创作者对违反伦理准则、隐私权或社区同意的滥用行为不承担责任。
搜集汇总
数据集介绍
构建方式
在非洲语言语音技术发展的背景下,African Next Voices: Kenya数据集通过严谨的社区协作模式构建。由肯尼亚多所高校联合组成的KenCorpus Consortium主导,采用脚本与非脚本双轨采集策略,覆盖农业、金融、医疗等11个领域。数据收集过程严格遵循伦理准则,通过方言平衡设计收录了Dholuo、Kikuyu等五种语言的语音样本,每种语言均标注原始文本、英语译文及方言变体信息。
特点
作为非洲低资源语言研究的标杆数据集,其核心价值体现在多维度标注体系上。除标准语音文本配对外,特别标注了说话人ID、领域分类、方言变体等元数据,且通过85:5:5:5的比例划分训练集与三种验证集。值得注意的是,测试集采用封闭管理以保障评测公正性,所有子集均实现说话人隔离,有效防止数据泄漏。未完成标注的语料持续更新状态亦通过版本控制明确标识。
使用方法
研究者可通过HuggingFace平台获取动态更新的数据集版本,建议优先选用最新发布以满足学术引用规范。该数据集专为语音识别模型训练与低资源语言研究优化,使用时应严格遵循CC BY 4.0协议。特别注意事项包括:测试集仅限公开评测使用,禁止任何涉及监控或歧视的伦理违规应用。多语言混合实验需结合方言标注信息进行数据筛选,非脚本语音需配合prompt类型字段进行语境分析。
背景与挑战
背景概述
非洲语言语音技术领域长期以来面临资源匮乏的困境,为填补这一空白,肯尼亚语料库联盟(KenCorpus Consortium)在盖茨基金会资助下,于2025年启动了'非洲新声:肯尼亚试点数据收集'项目。该项目聚焦基库尤语、索马里语、卡伦津语、卢奥语和马赛语五种肯尼亚本土语言,通过社区参与式方法采集涵盖农业、金融、医疗等11个领域的脚本与非脚本语音数据。作为非洲语音技术基础设施的重要组成,该数据集为低资源语言的自动语音识别研究提供了首个系统性基准。
当前挑战
构建过程面临多重挑战:在领域问题层面,低资源语言的方言变体丰富(如基库尤语含5种子方言),导致语音标注的归一化处理困难;非脚本语音中的即兴表达(如即兴故事环节)对转录准确性提出更高要求。在数据构建层面,伦理审查与社区知情同意流程延长了采集周期,部分语种(如马赛语)的录音设备适应性不足影响初始数据质量。此外,为保持数据平衡,各领域语料的比例控制与方言覆盖仍需持续优化。
常用场景
经典使用场景
在非洲语言语音技术研究领域,anv_data_ke数据集为低资源语言的自动语音识别(ASR)模型训练提供了重要支持。该数据集覆盖了五种肯尼亚本土语言的脚本和非脚本语音数据,涉及农业、金融、医疗等多个领域,为研究者提供了丰富的语音样本和对应的文本转录。其经典使用场景包括多语言ASR系统的开发与优化,特别是在资源稀缺的非洲语言环境下,该数据集填补了现有语音数据的空白。
实际应用
在实际应用中,anv_data_ke数据集为肯尼亚本土语言的技术开发提供了坚实基础。例如,在数字政府服务和金融交易领域,基于该数据集训练的ASR模型能够支持语音驱动的本地化服务,提升用户体验。同时,该数据集在教育和医疗领域的应用潜力也备受关注,例如开发语音辅助学习工具或医疗问诊系统,为非洲社区提供更便捷的技术支持。
衍生相关工作
围绕anv_data_ke数据集,已衍生出多项经典研究工作,特别是在低资源语言ASR模型优化和跨语言迁移学习领域。部分研究利用该数据集的多语言特性,探索了语言间的共享表征学习,显著提升了模型在资源稀缺语言上的性能。此外,基于该数据集的方言识别和领域自适应研究也为非洲语言语音技术的多样化应用开辟了新方向。
以上内容由遇见数据集搜集并总结生成


