NearID-Flux_1024
收藏Hugging Face2026-04-03 更新2026-04-04 收录
下载链接:
https://huggingface.co/datasets/Aleksandar/NearID-Flux_1024
下载链接
链接失效反馈官方服务:
资源简介:
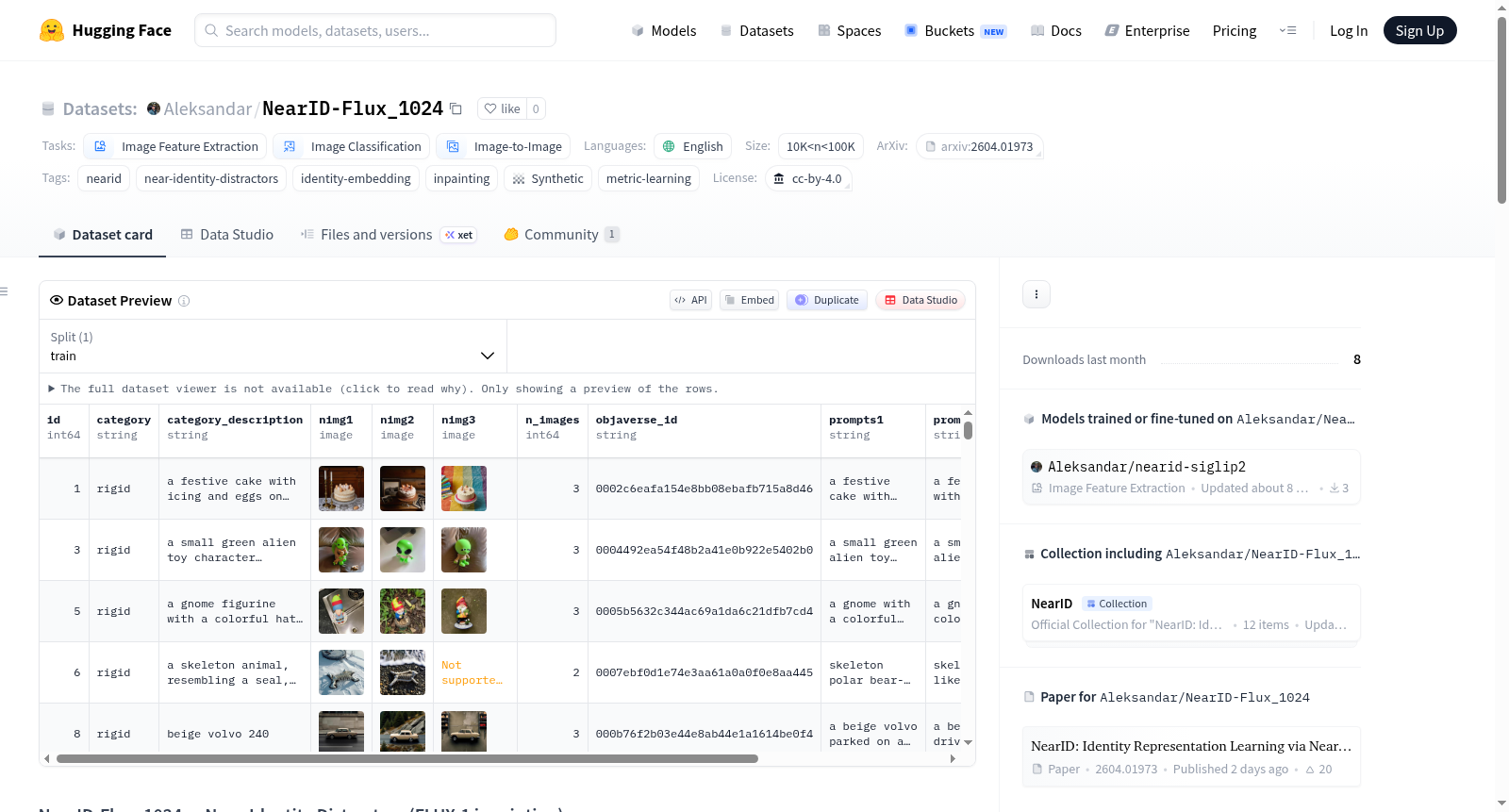
NearID-Flux_1024 是一个包含通过 FLUX.1 修复技术生成的近身份干扰项的数据集,分辨率为 1024×1024,属于 NearID 项目的一部分。每个样本包含最多 3 个干扰图像(nimg1, nimg2, nimg3),这些图像是通过在相同的背景/上下文中修复与基础 NearID 数据集中锚点对应的不同但视觉上相似的实例而生成的。这些干扰项用于训练和评估能够区分真实身份与上下文捷径的身份嵌入模型。数据集结构包括样本ID、对象类别、类别描述、干扰图像、有效干扰图像数量、源Objaverse对象标识符、生成提示和质量标签等字段。该数据集适用于图像特征提取、图像分类和图像到图像等任务,旨在帮助模型依赖内在身份特征而非背景上下文进行区分。
创建时间:
2026-04-02
原始信息汇总
NearID-Flux_1024 数据集概述
数据集基本信息
- 数据集名称: NearID-Flux_1024 (Near-Identity Distractors)
- 发布者: Aleksandar
- 语言: 英语
- 许可证: CC-BY-4.0
- 数据规模: 10K<n<100K
- 任务类别: 图像特征提取、图像分类、图像到图像
- 标签: nearid, near-identity-distractors, identity-embedding, inpainting, synthetic, metric-learning
- 数据拆分: train
数据集描述
该数据集包含通过 FLUX.1 修复技术在 1024×1024 分辨率下生成的 近身份干扰项,是 NearID 项目的一部分。
每个样本包含最多 3 个干扰图像 (nimg1, nimg2, nimg3):这些是不同的但在视觉上相似的实例,它们被修复到与基础数据集 Aleksandar/NearID 中对应锚点完全相同的背景/上下文中。这些干扰项用于训练和评估能够区分真实身份与上下文捷径的身份嵌入模型。
数据集结构
| 列名 | 类型 | 描述 |
|---|---|---|
id |
int64 | 样本ID(与基础NearID数据集匹配) |
category |
string | 对象类别 (rigid) |
category_description |
string | 对象的自然语言描述 |
nimg1, nimg2, nimg3 |
image | 近身份干扰图像(每个样本最多3个) |
n_images |
int64 | 有效干扰图像的数量 |
objaverse_id |
string | 源Objaverse对象标识符 |
prompts1, prompts2, prompts3 |
string | 每个干扰项的生成提示 |
quality |
string | 质量标签 |
干扰项生成方法
- 对于基础NearID数据集中的每个锚点身份,检索一个语义相似但不同的对象实例。
- 使用 FLUX.1 修复技术将干扰项实例修复到与锚点相同的背景中。
- 分辨率:1024×1024 像素。
相关资源
- 模型: Aleksandar/nearid-siglip2 — NearID身份嵌入模型
- 论文: NearID: Identity Representation Learning via Near-identity Distractors
- 代码: github.com/Gorluxor/NearID
- 项目主页: gorluxor.github.io/NearID/
许可与引用
- 许可证: 本数据集根据 CC-BY-4.0 许可发布。它源自 SynCD 数据集(MIT许可证,版权所有 2022 SynCD)。
- 引用要求: 如果使用此数据集,请同时引用NearID和SynCD。
- BibTex 引用: bibtex @article{cvejic2026nearid, title={NearID: Identity Representation Learning via Near-identity Distractors}, author={Cvejic, Aleksandar and Abdal, Rameen and Eldesokey, Abdelrahman and Ghanem, Bernard and Wonka, Peter}, journal={arXiv preprint arXiv:2604.01973}, year={2026} }
搜集汇总
数据集介绍
构建方式
在计算机视觉领域,构建能够有效评估身份表征学习的数据集至关重要。NearID-Flux_1024数据集通过系统化流程生成,其核心在于利用FLUX.1修复模型在1024×1024高分辨率下进行图像生成。具体而言,该数据集以基础NearID数据集中的锚点图像为基准,为每个锚点身份检索语义相似但不同的物体实例,随后将这些干扰实例通过FLUX.1修复技术无缝嵌入到与锚点完全相同的背景环境中。这一构建方法旨在创造视觉高度相似、仅身份特征存在细微差异的图像对,从而迫使模型必须依赖内在的身份特征而非上下文背景进行判别。
使用方法
在身份表征学习的研究与应用中,该数据集主要作为负样本源,用于训练和评估模型区分真实身份与视觉干扰的能力。典型的使用方法是与基础NearID数据集中的正样本(锚点与多视角正样本对)结合使用,共同构成完整的训练三元组。研究人员可通过Hugging Face的`datasets`库便捷加载数据,并利用其提供的图像与元数据字段,设计对比学习或度量学习损失函数,以提升模型在复杂视觉场景下对身份特征的鲁棒性识别与泛化性能。
背景与挑战
背景概述
NearID-Flux_1024数据集是NearID项目的重要组成部分,由阿卜杜拉国王科技大学(KAUST)和Snap研究院的研究团队于2026年创建,旨在推动身份表征学习领域的发展。该数据集的核心研究问题聚焦于如何使模型摆脱对背景上下文信息的依赖,从而学习到对象内在的身份特征。通过利用FLUX.1修复模型生成高分辨率(1024×1024)的近身份干扰图像,这些图像与锚点共享完全相同的背景,但包含语义相似的不同对象实例。这一设计为评估和训练身份嵌入模型提供了严谨的测试基准,对计算机视觉中的度量学习、图像特征提取等任务产生了深远影响。
当前挑战
该数据集致力于解决身份表征学习中的核心挑战,即模型容易利用背景、光照等上下文捷径进行判断,而非真正理解对象的本质身份特征。通过提供背景一致但身份不同的干扰项,它迫使模型必须聚焦于对象的固有属性,从而提升身份嵌入的判别能力。在构建过程中,研究团队面临生成高质量、语义相关且视觉逼真的干扰图像的挑战。这要求精确控制FLUX.1等生成模型,确保在复杂背景下进行无缝修复,同时保持与锚点对象的语义相似性,并维持1024×1024高分辨率下的图像质量,整个过程需要平衡生成多样性与身份判别难度。
常用场景
经典使用场景
在计算机视觉领域,身份表征学习旨在从图像中提取对象的本质特征,而NearID-Flux_1024数据集通过提供高分辨率的近身份干扰图像,为这一任务构建了严谨的评估基准。该数据集的核心应用场景是训练和验证身份嵌入模型,使其能够区分目标对象的真实身份与背景环境等上下文捷径。具体而言,模型需要对比锚点图像与在完全相同背景下生成的、视觉相似但身份不同的干扰图像,从而迫使学习算法聚焦于对象的内在身份属性,而非依赖场景线索进行判断。
解决学术问题
该数据集有效应对了身份表征学习中的一个关键挑战,即模型容易过拟合于与身份无关的背景上下文信息。通过提供严格控制的近身份干扰项,它促使研究社区开发出更具判别力的特征提取方法,确保身份识别系统的鲁棒性和泛化能力。其意义在于推动了度量学习与对比学习范式的进步,为评估模型是否真正理解了‘身份’这一抽象概念提供了可量化的标准,对提升计算机视觉系统在开放环境中的可靠性具有深远影响。
实际应用
在现实世界中,该数据集支撑的技术可广泛应用于需要精确身份辨别的场景。例如,在智能监控与安防领域,它有助于开发出不受拍摄角度、遮挡或背景变化影响的人脸或物体重识别系统。在内容创作与数字媒体领域,基于其训练的身份嵌入模型能够用于精准的图像检索、版权保护以及高质量的图像编辑与合成任务,确保生成的内容在身份特征上保持一致性与真实性。
数据集最近研究
最新研究方向
在计算机视觉领域,身份表征学习旨在从图像中提取稳定且具有判别性的特征表示。NearID-Flux_1024数据集通过FLUX.1修复技术生成高分辨率近身份干扰项,为模型训练提供了严格评估基准。当前研究聚焦于利用此类合成数据提升模型对身份本质特征的捕捉能力,避免其过度依赖背景上下文等表面线索。这一方向与生成式人工智能的快速发展紧密相连,特别是在可控图像合成与编辑技术推动下,为度量学习、图像检索及人脸识别等任务提供了更鲁棒的训练范式。该数据集的构建思路正引导学界探索如何通过精心设计的干扰项来增强模型的泛化性能与可解释性,对推动视觉表征学习迈向更高精度与可靠性具有显著意义。
以上内容由遇见数据集搜集并总结生成


