有没有相关的论文或文献参考?
这个数据集是基于什么背景创建的?
数据集的作者是谁?
能帮我联系到这个数据集的作者吗?
这个数据集如何下载?
RLAIF-V-Bias-Dataset 是基于 RLAIF-V-Dataset 构建的,旨在通过 LLaVA-v1.5-7b 模型缓解多模态大语言模型(MLLMs)中的模态偏差问题。
RLAIF-V-Dataset 提供了 83,132 个偏好对,指令来源于多个数据集,包括 MSCOCO、ShareGPT-4V、MovieNet、Google Landmark v2、VQA v2、OKVQA 和 TextVQA。此外,采用了 RLHF-V 中引入的图像描述提示作为长格式图像字幕指令。
在此基础上,引导 LLaVA-v1.5-7b 生成语言偏差答案(“question_only”)和视觉偏差答案(“image_only”)。在生成偏差响应的过程中,模型预训练知识和拒绝响应可能导致大量噪声样本的生成。
为了应对数据中的噪声,提出了 Noise-Aware Preference Optimization (NaPO) 方法。
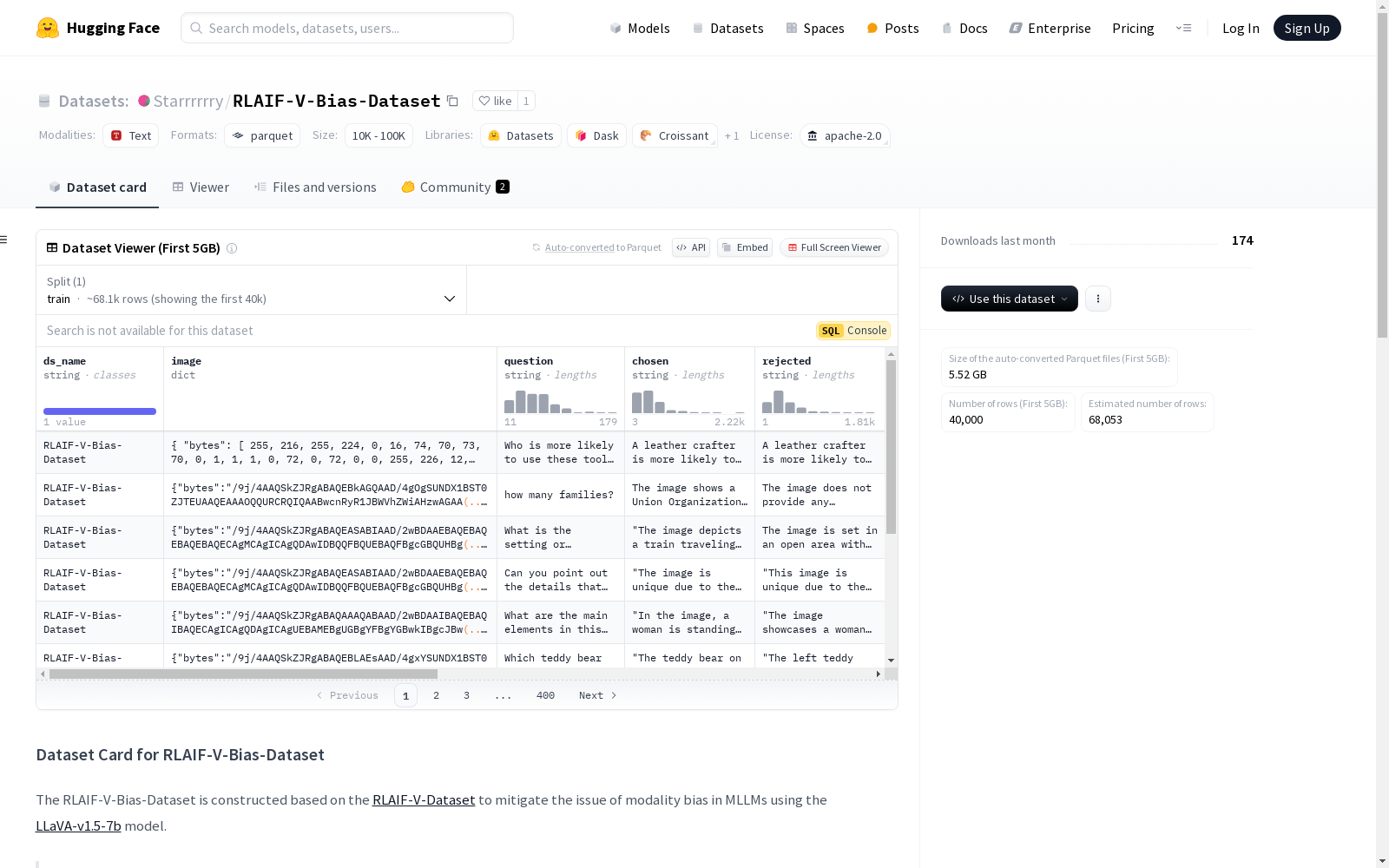
| 键 | 描述 |
|---|---|
| 0 | ds_name:数据集名称。 |
| 1 | image:包含路径和字节的字典,加载数据集时可自动转换为 PIL 图像。 |
| 2 | question:MLLMs 的输入查询。 |
| 3 | chosen:问题的被选响应。 |
| 4 | rejected:问题的被拒绝响应。 |
| 5 | origin_dataset:图像或问题的原始数据集。 |
| 6 | origin_split:每个数据项的元信息,包括生成被选和被拒绝答案对的模型名称、提供反馈的标注模型以及问题类型(“详细描述”或“问答”)。 |
| 7 | idx:数据索引。 |
| 8 | image_path:图像路径。 |
| 9 | image_only:语言偏差响应。 |
| 10 | question_only:视觉偏差响应。 |
python from datasets import load_dataset
data = load_dataset("Starrrrrry/RLAIF-V-Bias-Dataset")
相关论文将在后续发布。
中国气象数据
本数据集包含了中国2023年1月至11月的气象数据,包括日照时间、降雨量、温度、风速等关键数据。通过这些数据,可以深入了解气象现象对不同地区的影响,并通过可视化工具揭示中国的气温分布、降水情况、风速趋势等。
github 收录
网易云音乐数据集
该数据集包含了网易云音乐平台上的歌手信息、歌曲信息和歌单信息,数据通过爬虫技术获取并整理成CSV格式,用于音乐数据挖掘和推荐系统构建。
github 收录
中国空气质量数据集(2014-2020年)
数据集中的空气质量数据类型包括PM2.5, PM10, SO2, NO2, O3, CO, AQI,包含了2014-2020年全国360个城市的逐日空气质量监测数据。监测数据来自中国环境监测总站的全国城市空气质量实时发布平台,每日更新。数据集的原始文件为CSV的文本记录,通过空间化处理生产出Shape格式的空间数据。数据集包括CSV格式和Shape格式两数数据格式。
国家地球系统科学数据中心 收录
jpft/danbooru2023
Danbooru2023是一个大规模的动漫图像数据集,包含超过500万张由爱好者社区贡献并详细标注的图像。图像标签涵盖角色、场景、版权、艺术家等方面,平均每张图像有30个标签。该数据集可用于训练图像分类、多标签标注、角色检测、生成模型等多种计算机视觉任务。数据集基于danbooru2021构建,扩展至包含ID #6,857,737的图像,增加了超过180万张新图像,总大小约为8TB。图像以原始格式提供,分为1000个子目录,使用图像ID的模1000进行分桶,以避免文件系统性能问题。
hugging_face 收录
Subway Dataset
该数据集包含了全球多个城市的地铁系统数据,包括车站信息、线路图、列车时刻表、乘客流量等。数据集旨在帮助研究人员和开发者分析和模拟城市交通系统,优化地铁运营和乘客体验。
www.kaggle.com 收录