Celeb-DF v2
收藏www.kaggle.com2024-11-02 收录
下载链接:
https://www.kaggle.com/datasets/ciplab/real-and-fake-face-detection
下载链接
链接失效反馈资源简介:
Celeb-DF v2 是一个用于深度伪造检测的数据集,包含大量经过处理的深度伪造视频。该数据集旨在帮助研究人员开发和评估深度伪造检测算法。
Celeb-DF v2 is a dataset for deepfake detection, containing a large number of processed deepfake videos. This dataset is intended to assist researchers in developing and evaluating deepfake detection algorithms.
提供机构:
www.kaggle.com
AI搜集汇总
数据集介绍
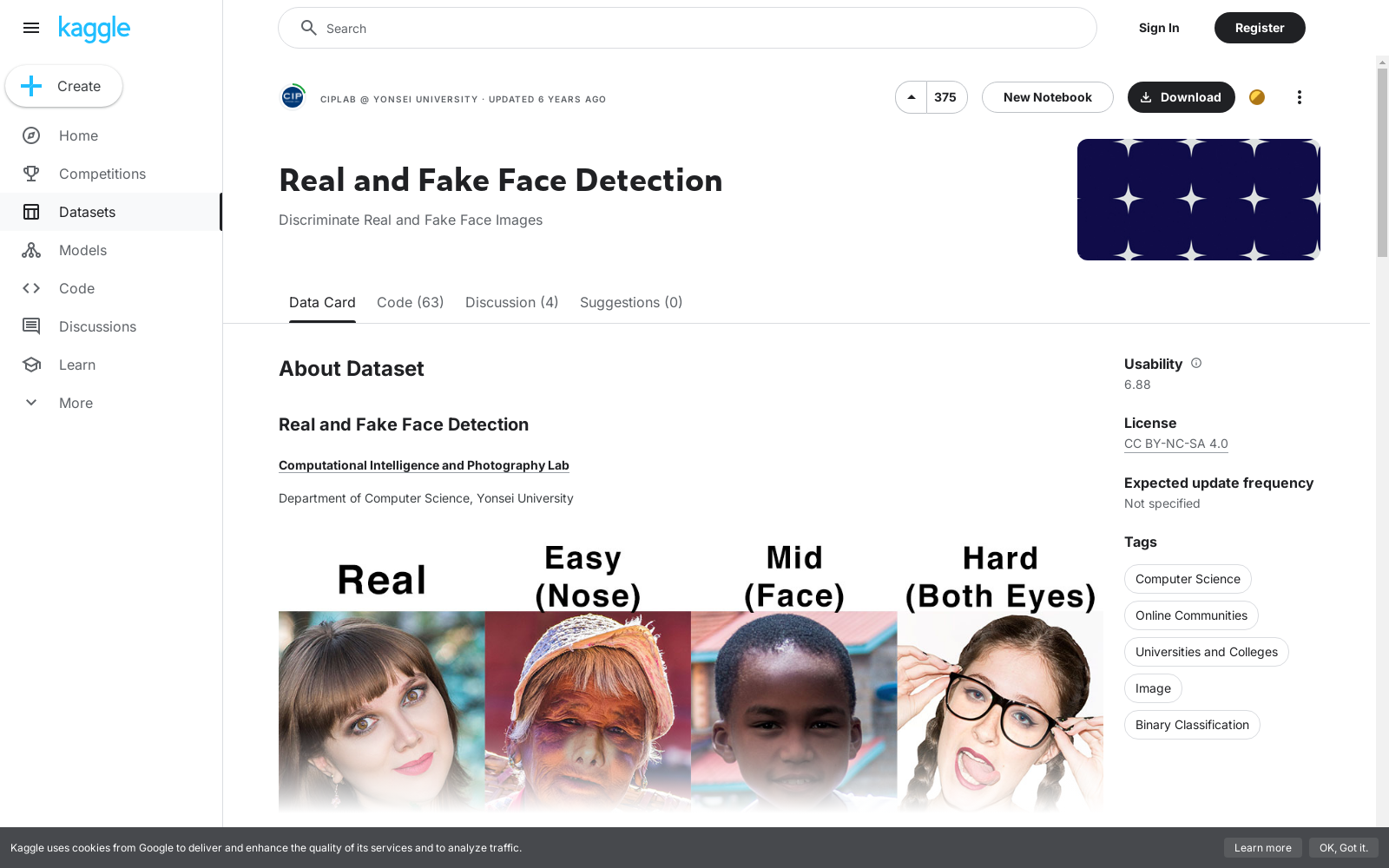
构建方式
Celeb-DF v2数据集的构建基于深度伪造技术,通过精心挑选的公开视频资源,利用先进的生成对抗网络(GAN)技术生成高质量的伪造视频。这些视频涵盖了多个知名公众人物,确保了数据集的多样性和代表性。构建过程中,研究人员严格遵循伦理规范,确保所有使用的视频资源均符合版权和隐私保护的要求。
使用方法
Celeb-DF v2数据集主要用于深度伪造检测算法的开发与评估。研究人员可以通过该数据集训练和测试自己的模型,以提高对伪造视频的识别能力。使用时,建议将数据集划分为训练集、验证集和测试集,以确保模型的泛化能力。此外,数据集还提供了详细的文档和代码示例,帮助用户快速上手并充分利用数据集的各项功能。
背景与挑战
背景概述
在深度伪造(Deepfake)技术迅速发展的背景下,Celeb-DF v2数据集应运而生,旨在为研究人员提供一个高质量的深度伪造视频数据集。该数据集由吴恩达教授领导的斯坦福大学团队于2020年发布,其核心目标是解决现有数据集在真实性和多样性方面的不足。Celeb-DF v2包含了大量经过精心挑选和处理的深度伪造视频,涵盖了不同种族、性别和年龄段的公众人物,极大地推动了深度伪造检测技术的发展。
当前挑战
Celeb-DF v2数据集的构建过程中面临了多重挑战。首先,确保数据集的真实性和多样性是一个关键问题,因为深度伪造技术不断进化,使得伪造视频越来越难以区分。其次,数据集的规模和质量要求极高,需要大量的计算资源和时间进行视频处理和标注。此外,数据集的隐私和伦理问题也不容忽视,如何在保护个人隐私的前提下提供有价值的研究资源,是该数据集面临的另一大挑战。
发展历史
创建时间与更新
Celeb-DF v2数据集于2020年首次发布,旨在应对深度伪造视频检测的挑战。该数据集的更新主要集中在提高数据质量和增加样本多样性,以更好地模拟现实世界中的深度伪造技术。
重要里程碑
Celeb-DF v2数据集的发布标志着深度伪造检测领域的一个重要里程碑。它包含了590个高质量的深度伪造视频,涵盖了79位名人,这些视频是通过改进的生成对抗网络(GAN)技术生成的。这一数据集的引入极大地推动了深度伪造检测算法的发展,为研究人员提供了一个更为复杂和真实的测试平台。此外,Celeb-DF v2还引入了新的评估指标,以更准确地衡量检测算法的性能。
当前发展情况
当前,Celeb-DF v2数据集已成为深度伪造检测研究中的一个基准数据集,广泛应用于学术研究和工业应用中。其高质量和多样性使得基于该数据集开发的检测算法在实际应用中表现出更高的准确性和鲁棒性。此外,Celeb-DF v2的发布也促进了相关领域的技术交流和合作,推动了深度伪造检测技术的不断进步。未来,随着深度伪造技术的不断演变,Celeb-DF v2数据集有望继续更新和扩展,以应对新的挑战。
发展历程
- Celeb-DF v2数据集首次发表,由Li等人提出,旨在解决深度伪造视频检测的问题。
- Celeb-DF v2数据集首次应用于多个深度伪造检测挑战赛,成为评估检测算法性能的重要基准。
- Celeb-DF v2数据集被广泛引用,成为学术界和工业界研究深度伪造检测技术的重要资源。
常用场景
经典使用场景
在深度伪造(Deepfake)技术的研究领域,Celeb-DF v2数据集因其高质量的伪造视频而备受关注。该数据集包含了大量经过精心制作的深度伪造视频,涵盖了不同年龄、性别和种族的公众人物。研究者们利用这一数据集进行深度伪造检测算法的开发与评估,旨在提高检测技术的准确性和鲁棒性。通过对比真实视频与伪造视频的特征差异,研究者们能够设计出更为有效的检测模型,从而应对日益复杂的深度伪造威胁。
解决学术问题
Celeb-DF v2数据集在学术研究中解决了深度伪造检测领域的关键问题。传统的深度伪造检测方法往往依赖于低质量的伪造视频数据,难以应对高质量伪造技术的挑战。Celeb-DF v2数据集提供了高质量的伪造样本,使得研究者能够开发和验证更为精确的检测算法。这不仅推动了深度伪造检测技术的发展,还为相关领域的研究提供了宝贵的数据资源,有助于提升整体研究水平。
实际应用
在实际应用中,Celeb-DF v2数据集为深度伪造检测技术的部署提供了重要支持。随着深度伪造技术的普及,其潜在的滥用风险日益增加,如虚假新闻、身份欺诈等。通过利用Celeb-DF v2数据集训练的检测模型,可以有效识别和防范这些伪造内容,保护公众免受虚假信息的侵害。此外,该数据集还为政府、企业和研究机构提供了可靠的工具,用于开发和测试深度伪造检测系统,确保其在实际应用中的有效性。
数据集最近研究
最新研究方向
在深度伪造(Deepfake)技术日益成熟的背景下,Celeb-DF v2数据集作为该领域的关键资源,其最新研究方向主要集中在提升检测算法的准确性和鲁棒性。研究者们通过引入多模态数据融合技术,结合图像和音频信息,以增强对伪造内容的识别能力。此外,跨域适应性研究也成为热点,旨在解决检测算法在不同数据分布下的泛化问题。这些研究不仅推动了深度伪造检测技术的发展,也为相关法律法规的制定提供了科学依据,确保了数字内容的真实性和可信度。
相关研究论文
- 1Celeb-DF: A Large-Scale Challenging Dataset for DeepFake ForensicsUniversity of Albany, SUNY · 2020年
- 2DeepFake Detection by Analyzing Convolutional TracesUniversity of Siena · 2020年
- 3DeepFake Detection Using Temporal and Hierarchical InformationUniversity of Surrey · 2021年
- 4DeepFake Detection with Inconsistent Head PosesUniversity of Surrey · 2021年
- 5DeepFake Detection Using Facial Landmark DistortionsUniversity of Surrey · 2021年
以上内容由AI搜集并总结生成


