search-arena-24k
收藏Hugging Face2025-05-16 更新2025-05-17 收录
下载链接:
https://huggingface.co/datasets/lmarena-ai/search-arena-24k
下载链接
链接失效反馈官方服务:
资源简介:
该数据集包含了从2025年3月18日至2025年5月8日在Search Arena平台上收集的所有野外对话,共有24,069个多轮对话,涉及多种意图、语言和主题,以及12,652个人类偏好投票。数据集涵盖了大约11,000名来自136个国家的用户,13个公开发布的模型,约90种语言(包括11%的多语种提示),和超过5,000个多轮对话会话。每个数据点包括两个模型标准化响应、半数数据点包含的人类投票结果、时间戳、完整的系统元数据和后处理注释,如语言和用户意图。
创建时间:
2025-05-16
搜集汇总
数据集介绍
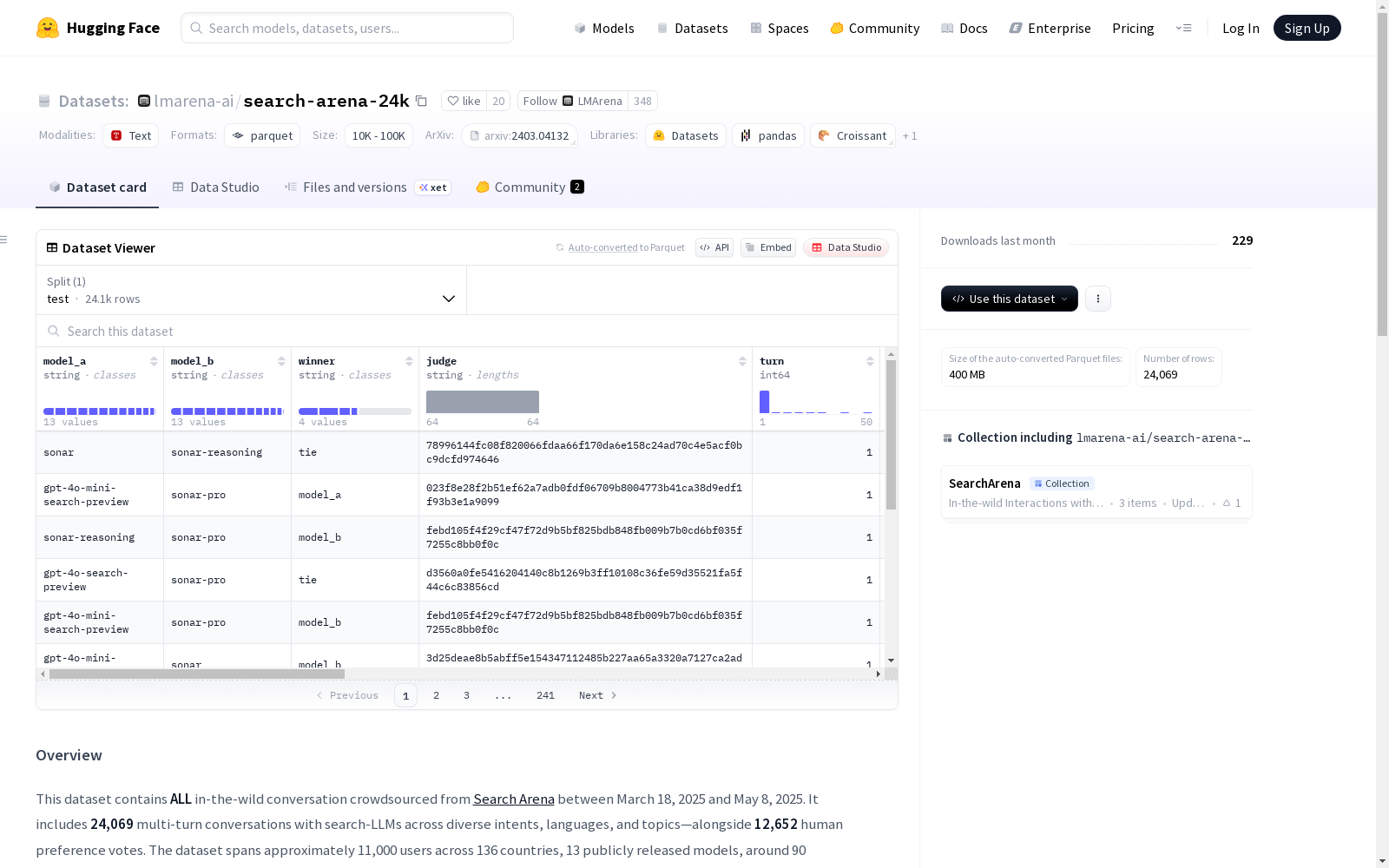
构建方式
在探索人机交互新兴范式的背景下,Search Arena 24K数据集通过大规模真实世界用户对话构建而成。数据采集自2025年3月至5月期间11,000余名用户的自然交互记录,采用谷歌数据丢失防护接口对个人身份信息进行脱敏处理,最终形成包含24,069轮多轮对话的语料库。所有对话均获得用户研究授权,并完整保留了包括时间戳、系统元数据及搜索轨迹在内的多维上下文信息。
特点
该数据集最显著的特征体现在其生态效度与多样性维度。覆盖136个国家用户群体产生的多语言对话中,约11%为跨语言查询,真实反映了全球化使用场景。数据集不仅包含模型标准化响应与人类偏好投票的对应关系,更通过12,652次人工标注构建了质量评估体系。其特有的混合交互模式记录了用户如何结合生成式回答与实时检索功能的行为轨迹,为理解搜索增强型语言模型的使用范式提供了独特视角。
使用方法
针对人机交互研究社区的需求,该数据集支持多维度分析框架的应用。研究者可基于时间序列分析用户行为演变规律,通过对比messages_a与messages_b的偏好投票数据构建质量评估模型。系统元数据与搜索轨迹的完整保留使得交互流程还原成为可能,而脱敏处理后的多语言语料则为跨文化比较研究提供了基础。建议遵循CC-BY-4.0许可协议使用用户提示部分,模型输出则需参照对应提供方的使用条款。
背景与挑战
背景概述
人机交互领域正经历由检索增强生成技术驱动的范式变革,Search Arena 24K数据集由加州大学伯克利分校等机构的研究团队于2025年创建,旨在捕捉融合实时检索与开放生成的新型搜索大语言模型交互模式。该数据集汇集了全球136个国家逾万名用户与13个公开模型的对话轨迹,涵盖90余种语言场景,通过多轮对话与人类偏好投票的并行记录,为理解混合式智能交互的认知机制提供了实证基础。
当前挑战
在构建过程中面临多模态数据对齐的复杂性,需协调搜索日志、对话序列与偏好标注的时序关联;领域问题层面需解决检索生成系统评估的维度冲突,包括事实准确性、对话连贯性与用户满意度之间的平衡难题。数据匿名化处理亦带来技术挑战,需在保护用户隐私的同时保留对话语义完整性,而跨语言场景下的意图分类与质量评估则要求建立超越单语种的文化语境理解框架。
常用场景
经典使用场景
在人工智能交互研究领域,Search Arena 24K数据集为探索混合检索生成模式提供了关键实证基础。该数据集通过记录用户与搜索增强语言模型的多轮对话,揭示了人类在融合实时检索与开放生成的新型界面中的行为模式。研究者可借助其大规模真实交互数据,分析用户提问策略、信息整合方式及偏好形成机制,为理解人机协作范式转变提供量化依据。
实际应用
在产业实践层面,该数据集为优化智能搜索引擎提供了重要参考。企业可基于真实用户与13种主流模型的交互轨迹,精准识别检索增强生成系统在医疗咨询、学术研究等垂直场景中的性能瓶颈。其经过数据脱敏处理的对话记录,还能助力开发符合伦理规范的对话系统,特别是在多语言服务、个性化响应等实际应用方向形成技术突破。
衍生相关工作
该数据集已催生多项前沿研究,其中Chatbot Arena开创的众包评估框架被扩展至检索增强场景。后续工作在此基础上发展了动态检索质量评估指标,提出了基于多轮对话的偏好学习算法。这些衍生研究不仅完善了混合智能系统的理论架构,更推动了如实时知识更新、跨模态检索等创新方向的发展。
以上内容由遇见数据集搜集并总结生成


