2k-ranked-images-open-image-preferences-v1
收藏Hugging Face2025-04-10 更新2025-04-11 收录
下载链接:
https://huggingface.co/datasets/Rapidata/2k-ranked-images-open-image-preferences-v1
下载链接
链接失效反馈官方服务:
资源简介:
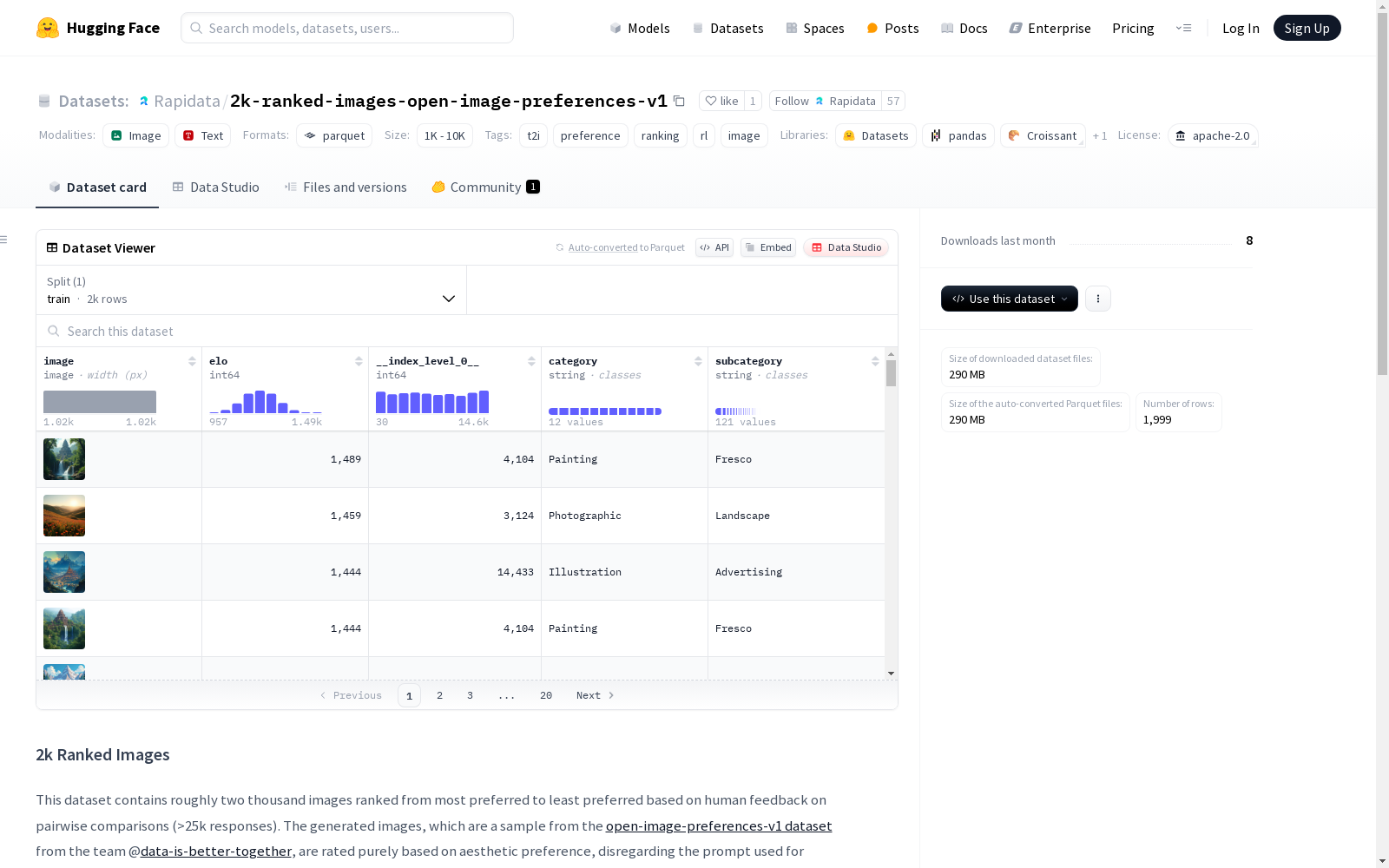
2k Ranked Images数据集包含了大约两千张根据人类审美偏好排序的图片,从最偏好到最不偏好。数据集基于成对比较的反馈进行排名,并提供了原始数据集的分类信息以便过滤。
创建时间:
2025-04-09
搜集汇总
数据集介绍
构建方式
在视觉偏好研究领域,该数据集通过创新性的构建方法为图像审美评估提供了新视角。基于open-image-preferences-v1数据集的子集,研究团队收集了超过2.5万组人类两两比较反馈,运用Elo评分系统对1999张生成图像进行排序。不同于传统基于文本提示的评估方式,该数据集完全依据人类审美偏好进行评分,同时保留了原始数据集的类别和子类标签以便于分析。
特点
该数据集呈现出鲜明的层次化特征,最高评分图像多展现优美宁静的自然景观,而低分图像则呈现多样化但质量欠佳的内容。每张图像均附带精确的Elo评分、类别标签和子类信息,为研究者提供了丰富的分析维度。特别值得注意的是,该数据集开创性地将游戏竞技领域的Elo评分机制引入图像审美评估,为量化视觉偏好建立了新的研究范式。
使用方法
研究者可通过HuggingFace平台直接加载该数据集,利用其提供的图像、评分和分类信息进行多角度分析。数据集适用于视觉生成模型优化、审美偏好研究等场景,用户可根据类别标签快速筛选特定主题图像。团队还提供API接口支持用户对自有图像进行排名,为扩展研究提供了便利工具。对于希望复现或扩展研究的用户,建议参考原始数据集和API文档以获取完整技术细节。
背景与挑战
背景概述
2k-ranked-images-open-image-preferences-v1数据集由data-is-better-together团队构建,旨在通过人类反馈对生成图像进行美学偏好排序。该数据集源自open-image-preferences-v1数据集,包含约2000张图像,基于超过2.5万次成对比较的人类反馈进行排序。其核心研究问题聚焦于探索人类对图像美学的普遍偏好模式,为生成式人工智能模型的优化提供重要参考。作为一种新型偏好数据模态,该数据集突破了传统成对比较的局限,为图像生成领域的偏好学习开辟了新方向。
当前挑战
该数据集面临双重挑战:在领域问题层面,图像美学评估具有高度主观性,如何建立可靠的跨文化审美标准是一大难题;同时,模型需要区分技术缺陷(如畸变)与主观偏好之间的差异。在构建过程中,大规模人类标注的一致性维护极具挑战性,25k次比较响应需要精细的质量控制机制;此外,从17k原始图像中筛选代表性样本时,需平衡类别覆盖与标注成本的矛盾。这些挑战使得数据集扩展至完整17k图像的计划需要谨慎的可行性评估。
常用场景
经典使用场景
在计算机视觉与生成式人工智能领域,2k-ranked-images-open-image-preferences-v1数据集为研究者提供了基于人类审美偏好的图像排序基准。该数据集通过超过2.5万次人工两两对比标注,构建了从最优到最差的图像质量梯度,成为评估生成模型输出美学质量的金标准。其典型应用场景包括训练图像生成模型的强化学习奖励函数,以及验证不同生成算法在人类主观评价维度上的性能差异。
实际应用
在实际应用中,该数据集被广泛应用于商业图像生成平台的算法优化。设计类AI工具利用其排序结果调整生成策略,确保输出符合主流审美标准;内容审核系统则参考最低评分图像特征,建立不良视觉内容的识别模型。广告创意领域通过分析高评分图像的共同特征,提炼出更具吸引力的视觉元素组合规律。
衍生相关工作
基于该数据集衍生的经典研究包括《基于人类偏好的生成对抗网络奖励机制设计》等多项重要工作。研究者们开发了基于Elo排序的强化学习框架Human-in-the-loop-RL,将人类审美判断融入模型训练过程。在跨文化审美分析方向,有团队利用数据集的分类标签,揭示了不同地域用户对图像风格的偏好差异,推动了个性化生成算法的发展。
以上内容由遇见数据集搜集并总结生成


